2008-10-20 22:05:56
![]() 何度も書いてきた、論文のpdfファイルをAmazon S3に保存する話。まず、すでにデータベースに登録されているかどかを確認して、なかったらpubmedサイトで情報を検索し、pdftotextで全文テキストを抽出して、得られた情報をMySQLのデータに保存すると同時に、pdfファイルはAmazon S3にアップロードするという流れになっている。
何度も書いてきた、論文のpdfファイルをAmazon S3に保存する話。まず、すでにデータベースに登録されているかどかを確認して、なかったらpubmedサイトで情報を検索し、pdftotextで全文テキストを抽出して、得られた情報をMySQLのデータに保存すると同時に、pdfファイルはAmazon S3にアップロードするという流れになっている。
pdftotextでのテキストの抽出で文字コードがどうも合わないので、utf-8で出力するように設定してみた。
/etc/xpdfrcの #textEncoding UTF-8をコメントアウトして、テキスト抽出の時には-encで文字コードを指定した。
pdftotext -enc UTF-8 xxx.pdf xxx.txt
というかんじ。これでいいのかな。よくわからない。pdfには、もとからpdf-8のものとasciiのものがあると思うのだが、これもまたよくわからない。はっきりいって、何もかもよくわからない。
保存したpdfファイルを、最後ダウンロードしてあたまにdを付けた名前で再保存することで、動作の確認をしているが、これは確認後は外した方がいい。
処理していくとときどきエラーが出る。
TypeError: sequence item 4: expected string, NoneType found
とか、
AttributeError: 'NoneType' object has no attribute 'replace'
というエラーである。NoneTypeって何だ。前にも遭遇して困ったことがあるような気がしないでもないが、よく思い出せない。それが、歳を取るということなのだ。とりあえず今日はここまで。エラーが出たものは自動的に失敗フォルダに移動するようにしようか。

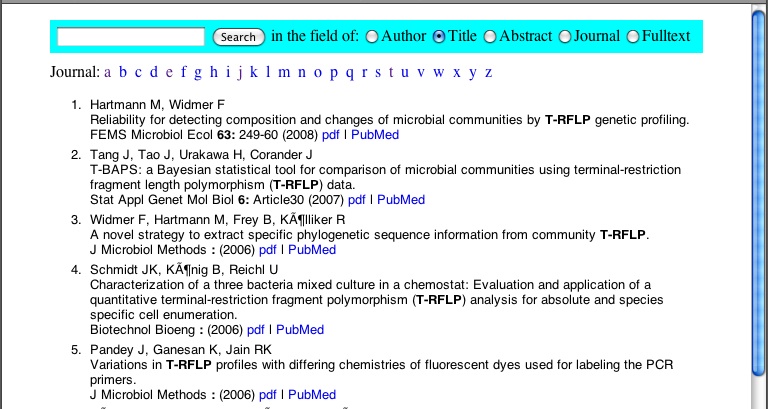
現在のところ、論文データ検索画面はこんなふうにできている。PHPで作ったページ。Journal名で一覧を出すこともできる。検索は、著者名、題名、要旨、全文検索ができる。題名にT-RFLPが含まれる論文を検索すると、下のように検索後が強調されて表示される。それで、関連情報を探したかったら、PubMedへのリンクをクリックすればいいし、論文を読みたいと思ったらpdfというリンクをクリックすればいい。Amazon S3にあるpdfファイルが呼び出されてくる。ちょっと遅いなあ。こんなちまちましたファイルには向いていないのか。まあ、いいか。