2011-05-24 21:08:56
本が増えて困っていた。今でも困ってはいる。本が増えたら本棚を買わなくてはならない。しかし、購入資金の目処がたたなかった。本は増えることはあっても、減ることはない。エントロピーと同じである。
本棚購入資金がなくても、本は増える。一冊買ったら30冊は増えると思った方がいい。そこで、やむなく本を切ってスキャナーで読み取り、pdfファイルにすることにした。もう何年も前から(多分8年くらい前から)何冊か試してみたことはあったのだが、心を決めて本格的に処理しようと思ったのである。「本格的に」とは数百冊から千冊程度以上のことだ。数十冊ならやらない方がいい。
スキャンの手順などはこれまで何度か書いているから省略する。今年に入ってから350冊くらいの本を処理してきた。主に、新書とオライリーの本だ。もちろん、それだけではないが。毎月どれくらいの本を処理したかが判るグラフを作った。購入書籍数と比べれば、物理的な書棚の中の本がどれくらい減ったかが判るというわけだ。→グラフ
問題は、自分がどの本を電子化してpdfで持っているのかをすぐに見つけられなくてはならないということである。できれば、その結果が「本があった!」ということを実感できるようにしたい。本を手に取るような感じが望ましい。そこで、前に書いたpdfファイルからjpg画像を作る方法などを利用して、表紙の画像ファイルを用意し、pdfファイル名にはisbnが含まれるようにして、著者名、書名、刊行年などの情報をネット検索で取得できるようにした。取得データをMySQLに保存して、検索結果をWWWブラウザに表示するPHPスクリプトを作った。例えば「岩波新書」という文字列で検索すると以下のような結果が表示される(これはちょっと古くて、今ではもっと増えている)。
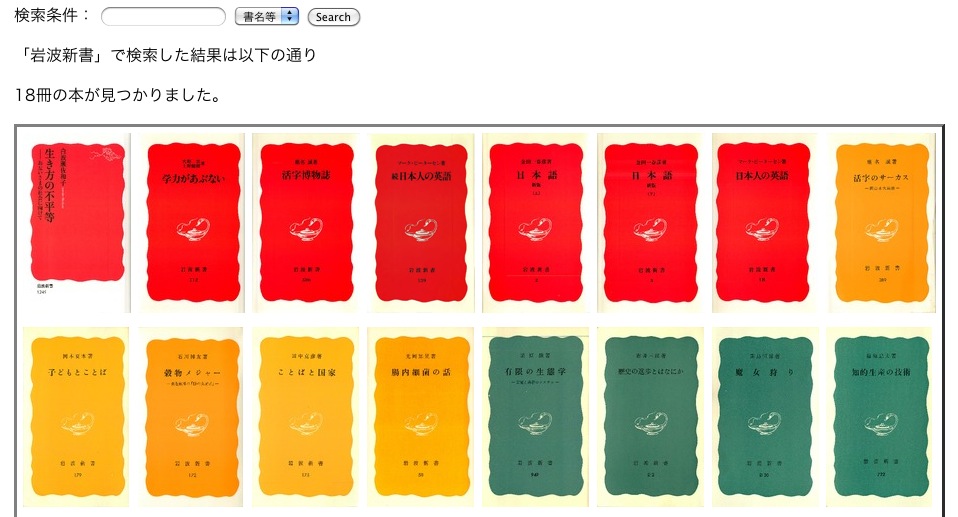
残念ながら、この表示画像をクリックしてもpdfファイルは開かない。ファイル名を確認できるだけだ。だが、近いうちにそうしようと思っている。ただ、地震の後は停電が怖くてサーバを自宅からAmazon EC2にしたので、いろいろと予定がくるってしまい、今のところいつ実現できるかは判らない。
それでも新書の電子化は進み、一つの小さな書棚に収まる量になった。新書はこの本棚以上に増やさないことに決めて、溢れてきたらスキャンすることに決めている。

こうして作ったpdfファイルを読むときの話はまた後ほど。