2008-09-08 23:26:53
一昨日導入したGoogle Desktopだが、土日のうちにインデックス作成が終わっていた。Google Desktop APIsにある説明を読んで、真似してみようかと思ったが、ポートは4664ではなく32051だ。4664で繋ごうとしても、
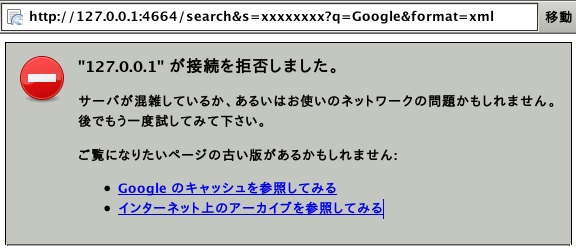
と返されてしまう。そこで、Google Desktop APIsにある説明のように、http://127.0.0.1:32051/search?flags=8&hl=ja_JP&num=10&q=glucose&start=0&s=xxxxの後ろに、&format=xmlをつけてやったらxmlで検索結果を返してくれるのかと思ひきや「存在しないページがリクエストされました。」と云われてしまう。解らない。
そこで、MacOSXにインストールしてみた。今度はポート番号は5089だった。
「google」を検索すると下のようなURLになった。
http://127.0.0.1:5089/search?q=google&s=xxxx&ie=UTF-8&btnG=Suche
そこで、この後ろに、
&num=30&format=xml
をつけてやったら、XML形式で30件の結果が表示された。どうなっているのか。Linuxでは駄目なのか。ネット上を彷徨っても情報は得られなかった。
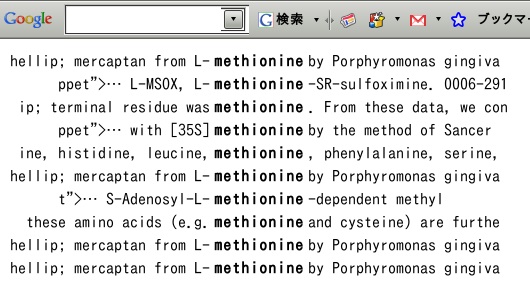
とりあえず、HTML形式で返ってきた結果を正規表現で取り出して強調表示してみた。が、納得できない。これで一度に100件とか500件とか表示してくれれば、自分がため込んでいる文献検索なんかが楽なのだが。用例検索ができて嬉しいのだが。
#!/usr/bin/python
import sys
import urllib
import re
from re import *
keyword = sys.argv[1]
query = {'hl':'ja_JP','s':'xxxxxxxxxxxx',\\
'ie':'UTF-8','adv':'1','type':'cat_files','filetype':'pdf',\\
'ext':'','mediatype':'','emailfrom':'','emailto':'',\\
'domain':'','q':keyword,'no':''}
url = 'http://127.0.0.1:32051/search?' + urllib.urlencode(query)
file = urllib.urlopen(url)
content = file.read()
file.close()
re_summary = re.compile('<span class=\"snippet\">.+?</span>')
items = content.split('<div class=\"searchresult\">')
items = items[1:]
table = '<table border="0">\n'
for item in items:
summary = re_summary.search(item).group(0)
kwds = re.findall('<b>.+?</b>',summary)
parts = re.split('<b>.+?</b>',summary)
j = 0
for kwd in kwds:
trow = "<tr><td align='right'>"+\\
parts[j][(len(parts[j]))-25:]+\\
"</td><td align='center'>"+kwd+\\
"</td><td>"+parts[j+1][0:25]+"</td></tr>\n"
table += trow
table += "</table>\n";
print table
こんな具合に書いて、ブラウザで開けば下のようになる。自分で溜め込んで整理していない論文pdfファイルから、用例を抜き出して提示してくれる。XML形式でどうしても返して来ないところが不愉快だが、これはもう少し真面目に作ってみようか。