2007-10-28 20:12:38
MacOSX 10.5 Leopard インストールしました。新しいMacOSがあったらインストールせずにはいられないから。一秒でも早くインストールしたい。
早速インストールして気づいた点は以下のとおり。
- Jammingで日本語を入力したときに検索ができない。
- MaxMenusが異常終了してしまう。
- WindowShade Xが使えない。
- Synergyはなぜか -f オプションをつけて「フォアグラウンド」で開始しないと正常に動作しない。
- iTunesで曲を聴いてゐる途中で不意に止まることがある。しばらくすると恢復する。
- ABCLaunch 0.6.2を「1」以外のspaceで使おうとしてと、スペース1に行ってしまう(複数のスペースで一つのアプリケーションを使うことはできないということか)。
- Firefox 2.0で、htmlのフォーム入力欄でキリル文字が表示できなくなった。
- Safari 3.0でPHP/HTMLのフォーム入力からアップロードができなくなったサイトがある(自分のところ)。
- 気がつくとX11が勝手に立ち上がってゐることがある(気のせいかも)。
2007-10-19 23:54:39
RをMacOSXにインストール。Aqua版Tcl/Tkが使えるようになるとかで、X11環境がなくても使えるらしいので、以下のような条件でコンパイルしてみた。
./configure --with-blas='-framework vecLib' --with-lapack \\ --with-aqua --enable-R-framework --with-tcl-config=\\ /System/Library/Frameworks/Tcl.framework/tclConfig.sh \\ --with-tk-config=/System/Library/Frameworks/Tk.framework\\ /tkConfig.sh (中略) R is now configured for i386-apple-darwin8.10.1 Source directory: . Installation directory: /Library/Frameworks C compiler: gcc -std=gnu99 -g -O2 Fortran 77 compiler: g95 -g -O2 C++ compiler: g++ -g -O2 Fortran 90/95 compiler: g95 -g -O2 Obj-C compiler: gcc -g -O2 Interfaces supported: X11, aqua, tcltk External libraries: readline, BLAS(vecLib), LAPACK(in blas) Additional capabilities: iconv, MBCS, NLS Options enabled: framework, R profiling, Java Recommended packages: yes configure: WARNING: you cannot build DVI versions of the R manuals configure: WARNING: you cannot build PDF versions of the R manuals make sudo make installしかし、Aqua版Tcl/Tkでは動かない。前には一度できたような気がするのだが、何度かインストールしているうちに動かなくなったのではなかったか。あまりGUI環境は使わないからどうでもいいとはいえ、ちょっと悔しい。
2007-10-17 21:22:02
今度はMaximaをproc_openで操作してみた。
#!/usr/bin/php
<?php
$array = array(1,2,0,2,1,1,0,1,1);
$matrix = "[";
$i=1;
foreach($array as $val){
$matrix .= $val;
if(fmod($i,3)==0){
$matrix .= "],[";
}else{
$matrix .=",";
}
$i++;
}
$matrix = preg_replace("/,\[$/","",$matrix);
$descriptorspec = array(
0 => array("pipe","r"),
1 => array("pipe","w"),
);
$process = proc_open("maxima",$descriptorspec,$pipes);
if(is_resource($process)){
fwrite($pipes[0], "load(eigen);\n");
fwrite($pipes[0], "A:matrix(".$matrix.");\n");
fwrite($pipes[0], "eigenvalues(A);\n");
fwrite($pipes[0], "eigenvectors(A);\n");
fwrite($pipes[0], "quit();\n");
fclose($pipes[0]);
while(!feof($pipes[1])){
$result .= fread($pipes[1], 4096);
}
fclose($pipes[1]);
proc_close($process);
}
echo $result;
?>
行列を入力する形式が面倒臭い。正しく行列を入力して固有値と固有ベクトルを求めてみると、
Maxima 5.10.0 http://maxima.sourceforge.net
Using Lisp GNU Common Lisp (GCL) GCL 2.6.7 (aka GCL)
Distributed under the GNU Public License. See the file COPYING.
Dedicated to the memory of William Schelter.
This is a development version of Maxima. The function bug_report()
provides bug reporting information.
(%i1) (%o1) /usr/share/maxima/5.10.0/share/matrix/eigen.mac
(%i2) [ 1 2 0 ]
[ ]
(%o2) [ 2 1 1 ]
[ ]
[ 0 1 1 ]
(%i3) (%o3) [[1 - sqrt(5), sqrt(5) + 1, 1], [1, 1, 1]]
(%i4) sqrt(5) 1
(%o4) [[[1 - sqrt(5), sqrt(5) + 1, 1], [1, 1, 1]], [1, - -------, -],
2 2
sqrt(5) 1
[1, -------, -], [1, 0, - 2]]
2 2
(%i5)
という具合になる。正しく結果を受け取れるのだが、最初にMaximaの説明がついてくるとか、計算結果の表示形式も、あまり受け取った後の処理には向いていないようだ。コマンドラインで操作できるものなら大抵のものはproc_openで操作出きそうなのだけれども、それに向いているものと向いていないものがあるようだ。
R 2.6.0が出ていた。全然気づかなかった。何度かRのトップページを見ているのに。
2007-10-16 21:51:57
PHPからRを操作してみた。最初に3行3列の行列を作って、固有値と固有ベクトルを得るというもの。
<?php
$array = array(1,2,3,9,11,16,21,22,23);
$descriptorspec = array(
0 => array("pipe","r"),
1 => array("pipe","w"),
);
$process = proc_open("R --vanilla --slave",$descriptorspec,\\
$pipes);
if(is_resource($process)){
fwrite($pipes[0], "A <- matrix (c(".implode(",",\\
$array)."), nrow=3,ncol=3)\n");
fwrite($pipes[0], "eigen(A)\n");
fwrite($pipes[0], "quit()\n");
fclose($pipes[0]);
while(!feof($pipes[1])){
$result .= fread($pipes[1], 4096);
}
fclose($pipes[1]);
proc_close($process);
}
echo $result;
?>
これを実行すると、
$values
[1] 38.8024950 -3.3394581 -0.4630369
$vectors
[,1] [,2] [,3]
[1,] -0.5003593 -0.8296818 -0.97423841
[2,] -0.5591098 -0.4301570 0.22377201
[3,] -0.6610876 0.3557992 -0.02802863
という結果が得られる。なかなかいい感じではないか。Rを呼び出すときに、「--vanilla --slave」というのを入れるのは、余計なものを表示させないためらしい。さて、今度は図を書かせたい。
<?php
$array = array(21,12,33,39,11,16,21,22,23);
$descriptorspec = array(
0 => array("pipe","r"),
1 => array("pipe","w"),
);
$process = proc_open("R --vanilla --slave",$descriptorspec,\\
$pipes);
if(is_resource($process)){
fwrite($pipes[0], "A <- c(".implode(",",$array).")\n");
fwrite($pipes[0], "bitmap(file=\"%stdout\", type=\\
\"png256\")\n");
fwrite($pipes[0], "hist(A)\n");
fwrite($pipes[0], "quit()\n");
fclose($pipes[0]);
while(!feof($pipes[1])){
$result .= fread($pipes[1], 4096);
}
fclose($pipes[1]);
proc_close($process);
}
header("Content-type:image/png");
echo $result;
?>
このファイルを保存してブラウザで表示させてみると、ヒストグラムが表示される。
もちろんこれだけならわざわざPHPから操作する必要もないことだけれども、自動的に生成される数値を処理するときなどには、なんらかのスクリプトで動かしてやらなくてはならないから、必要になるときが来るだろう。
他のでもいろいろ試してみようかな。
参考にしたのは主に以下の3箇所。
●
PHPでグラフを作る(gnuplot編)
●
PHPについて質問致します。
●
DokuWikiの日本語対応
2007-10-15 22:40:12
PHPのproc_openの使い方がどうもよく判らなかった。いろいろなことを他のプログラムにさせることができそうなのだが、あまりPHPの解説本にも載っていないのだ。PHPでmecabを動かすときにも読込ませたいテキストをみっともなくファイルに保存してから読込んで実行させていたのだ。これは何とかしたいと思い、ネット上を彷徨って私にも判りそうな記述を集めて少し理解した(ような気がする)。そこで、少し理解が進んだかどうかを検証するために、Yahooの検索で集めてきたサイトの"summary"情報をmecabで分解して名詞だけを取りだし、その数を集計するスクリプトを作ってみた。
#!/usr/bin/php
<?php
//最初はYahooAPIで検索#########################
$base = "http://api.search.yahoo.co.jp/WebSearchService/V1/\\
webSearch?appid=(id)&query=";
$key = urlencode($argv[1]);
$xml = simplexml_load_file($base.$key);
foreach($xml->Result as $item){
$nouns = array();
$result = "";
$summary = $item->Summary;
$summary = ereg_replace("\.\.\.","",$summary);
$summary = ereg_replace("\"","",$summary);
$summary = ereg_replace(" ","",$summary);
$summary = ereg_replace("\("," ",$summary);
$summary = ereg_replace("\)"," ",$summary);
echo $summary."\n";
//ここからproc_openでSummary情報をmecabで######
//処理する操作が始まる########################
$descriptorspec = array(
0 => array("pipe","r"),
1 => array("pipe","w")
);
$process = proc_open("mecab",$descriptorspec,$pipes);
if(is_resource($process)){
fwrite($pipes[0], $summary);
fclose($pipes[0]);
while(!feof($pipes[1])){
$result .= fread($pipes[1], 4096);
}
fclose($pipes[1]);
proc_close($process);
$lines = explode("\n",$result);
foreach($lines as $line){
$tab = explode("\t",$line);
$res = explode(",",$tab[1]);
if($res[0]=="名詞"){
array_push($nouns,$tab[0]);
}
}
}
$words = array_count_values($nouns);
$no = count($nouns);
arsort($words);
$i=1;
foreach($words as $key => $val){
echo $key.":".$val."回\n";
//結果表示はとりあえず最初の10件#################
if($i>10){
break;
}
$i++;
}
echo "合計".$no."語\n\n";
}
?>
ここで(id)となっているところは各自のYahoo Japan用のappidを入れる。たとえば、proctest.phpという名で保存して
php proctest.php マングースなどと打ち込んでみれば、
マングースはインド原産の食肉目の動物で、コブラの天敵として知ら れている。そこで東大の先生がマングースに注目、ハブと戦わせる実 験を行った。マングースはハブにかまれても死ぬことはなく、最後は ハブの頭に食いついて、見事にしとめたのだ。 ハブ:3回 マングース:3回 実験:1回 注目:1回 こと:1回 最後:1回 の:1回 見事:1回 頭:1回 先生:1回 東大:1回 合計23語というような感じになって、ここではマングースとハブが関係深いことが窺われる。これを利用して検索結果の分類に使えたりしないだろうかと思ったわけだ。しかし、面倒臭いのでこれ以上追究はしない。
mecabは何とかなりそうなことが判ったので、今度はRを少し操作してみたい。
2007-10-14 12:21:23
前にも書いたubuntuのcrontabだが、crontab -e で書き込んだ指示は全く実行されない。出力を >/dev/null 2>&1とやって標準出力を棄てるのが大事だなどと書いてあるところもあるが、そう設定してみても駄目だった。

そうだ我が家にはubuntuの本があるはずだと思い書棚を探して、oreillyのUbuntu Hacksを見つけたのだが、cronのことは書いてないようだ。もう一冊あったはずだと探してUbuntu Linux 6.xというのを引っぱり出してきてみると、一応crontabの説明は後ろの方にちょっとだけある。ここでもユーザの設定はcrontab -e で編集せよと書いてある。管理者権限での設定はsudo crontab -eだという。そして設定例が書いてあって、最後にgcrontabみたいなGUIのフロントエンドもあるよという記述があって終わっている。ドイツ語だからあまり自信はないのだが、多分そういうことだろう。
本を開いても全く問題は解決されない。いくらやっても実行されないのだが、一体どういうことなんだ。標準出力を棄てるとか棄てないとかは全然関係ないじゃないか。
ということで、直接編集してはならないという/etc/crontabに書き込むことにした。ここの書けば実行されることは判っている。標準出力を棄てても棄てなくても。編集するなっていうけど、それなら何のためにあるんだ。私は自分の意思で編集したいときに編集したいファイルを編集したいように編集する。誰にも文句は云わせない(誰も云わないけど)。
話は変わるが、.macのメール送信が数日前から出来なくなってしまった。smtp.mac.comのポートを25から587に変更したら送信できるようになったようだ。
2007-10-12 20:51:53
mfc6800jlprをインストールしようとしてどうにもならない状況に陥ってしまった。何かをインストールしようとすると、必ず「E: パッケージ mfc6800jlpr を再インストールする必要がありますが、そのためのアーカイブを見つけることができませんでした。」というエラーが出てしまうのだ。再インストールしようとしても、パッケージが見つからないというエラーが出るだけ。強制的にアンインストールしようとすると、「dpkg: mfc6800jlpr の処理中にエラーが発生しました (--remove): パッケージが非常に矛盾した状態に陥りました。」などと云われてしまう。
/var/cache/apt/archiveに mfc6800jlpr-1.1.2-1.i386.deb を置いて、インストールしようとすると
mkdir: ディレクトリ `/var/spool/lpd/MFC6800J' を作成できません:\\ No such file or directory chown: cannot access `/var/spool/lpd/MFC6800J': \\ No such file or directory chgrp: cannot access `/var/spool/lpd/MFC6800J': \\ No such file or directory chmod: cannot access `/var/spool/lpd/MFC6800J': \\ No such file or directoryというエラーが出るので、/var/spool/lpdというディレクトリを作ってやった。そして再度インストールを実行すると、今度は、
/var/lib/dpkg/tmp.ci/postrm: 3: /etc/init.d/lpd: not foundというので、ダミーのlpdを/etc/init.d/lpdを置いて、もう一回インストール。おお、成功したではないか。ここでlprをインストールするという手もありかも知れないと思ったが、また失敗するのは嫌なので、
sudo dpkg -r mfc6800jlprとやって削除。そしてダミーのlpdを削除。
これで正常に復したと思う。一時はどうなることかと思った。Brother MFC-6800JのプリンターはMacOSXの方から使うから、ubuntuから使えなくても別にいいのだ。
2007-10-11 22:20:42
さて、キーワード検索もしたいので、PubMedでキーワード検索をしてからBibTeX形式で結果を表示するスクリプトを作ってみた。
#! /usr/bin/php
<?php
$base = "http://eutils.ncbi.nlm.nih.gov/entrez/\\
eutils/esearch.fcgi?";
array_shift($argv);
$kwords = implode(" AND ",$argv);
$kwords = urlencode(ereg_replace("_"," ",$kwords));
$url = $base."db=pubmed&term=".$kwords;
$res = file_get_contents($url);
$xml = simplexml_load_string($res);
$pmid_array = $xml->IdList->Id;
$pmids = "";
foreach($pmid_array as $pmid){
$pmids .= $pmid.",";
}
$pmids = ereg_replace(",$","",$pmids);
include("pmf.php");
?>
これをpmsearch.phpというような名前で保存して実行権を付与して保存。一方、昨日作ったスクリプトの$argvのあたりを$pmidsと書き換えてpmf.phpという名前で保存する。使うときには、./pmsearch.php trifluoromethionine 2002[edat]というようにする。スペースはAND検索に変換されるので、スペースとして残したいところはアンダーバーを入れておく。
昨日作ったpmfetch.phpはパスの通ったところにpmfetchという名前で保存しておくと、いつでもどこでもpmfetch 111111とやってBibTeX形式の文献情報が得られる訳だが、たとえば/usr/local/binに保存しようとしてディレクトリを覗いてみたら、そっくりな名前のスクリプトが既にあって、どうやら一年くらい前に一度作って保存していたことをすっかり忘れていたなんてことになると、気分は「こんな便利なもの作ってしまってひょっとして俺って頭いいのかも」という浮かれた状態から、「ただの惚け老人だったんだ」と一気に暗転するから迂闊に喜びすぎない方がいい。幸い、今回のは似たものは見つからなかった。
*昨日掲載したスクリプトは<?php……?>をそのまま書き込んでしまって、見えなくなっていたのを修正しました。
2007-10-10 21:42:34
これまでBibTeX形式の引用文献データを作るときには、Biorubyの使用例として紹介されているスクリプトを使ってきたのだが、昨日はどういうわけか結果が返ってこなかった。どうしてだろう。Google Scholarでも検索結果をBibTeX形式で表示させる機能があるのだが、コピー&ペーストが面倒臭い気分のときもある。Biorubyスクリプト不調の原因を解明するよりも自分で作った方がいいかなと思い、しかしRubyはまだよく使えないのでPHPで作ってみた(以下のPHPスクリプトで\\は本来改行していない行を改行していることを示している)。
#!/usr/bin/php
<?php
$pmid = $argv[1];
$url = "http://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?";
$url .= "db=pubmed&id=".$argv[1]."&retmode=xml";
$res = file_get_contents($url);
$xml = simplexml_load_string($res);
foreach($xml as $item){
$pmid = $item->MedlineCitation->PMID;
$type = $item->MedlineCitation->Article->PublicationTypeList-\\
>PublicationType[0];
if($type=="Journal Article"){
$ttype = "article";
}else{
$ttype = "other";
}
$title = $item->MedlineCitation->Article->ArticleTitle;
$authors = $item->MedlineCitation->Article->AuthorList->\\
Author;
$authorarray = array();
foreach($authors as $author){
array_push($authorarray,($author->LastName.", ".$author\\
->Initials));
}
$authorlist = implode(" and ",$authorarray);
$journal = $item->MedlineCitation->Article->Journal->Title;
$volume = $item->MedlineCitation->Article->Journal->\\
JournalIssue->Volume;
$number = $item->MedlineCitation->Article->Journal->\\
JournalIssue->Issue;
$pages = $item->MedlineCitation->Article->Pagination->\\
MedlinePgn;
$year = $item->MedlineCitation->Article->Journal->\\
JournalIssue->PubDate->Year;
$tlwords = explode(" ",$title);
$thrlett = strtolower(substr($tlwords[0],0,1).substr\\
($tlwords[1],0,1).substr($tlwords[2],0,1));
$cite = strtolower($authors[0]->LastName).$year.$thrlett;
$pp = explode("-",$pages);
$len0 = strlen($pp[0]);
$len1 = strlen($pp[1]);
$pp1 = substr($pp[0],0,($len0-$len1));
$ppages = $pp[0]."--".$pp1.$pp[1];
echo "@".$ttype."{".$cite.",\n";
echo " title={".$title."},\n";
echo " author={".$authorlist."},\n";
echo " journal={".$journal."},\n";
echo " volume={".$volume."},\n";
echo " number={".$number."},\n";
echo " pages={".$ppages."},\n";
echo " year={".$year."}\n";
echo "}\n\n";
}
?>
このスクリプトをpmfetch.phpなど好きな名前で保存して(実行権を与えて)、% ./pmfetch.php 16709590,15908380,15845368というように引用したい論文のPubMed IDを引数に実行するとBibTeX形式で結果が返ってくるはず(複数の論文の情報を得たいときは「,」でつなぐ)。引用用のIDはGoogle Scholarふうの作り方にしてみた。Google Scholarではなぜかタイトルが二重の{}で囲まれているけれども、ここではそんなことはしていない。ページ数を全部表示させるのに余計な手間がかかってしまった。ファイルに保存したいときは、「>>ファイル名」などとしてみる。ちなみに、キーワードで検索する機能はない。
2007-10-08 15:35:26
OkidataのMicroline 18NRでpdfファイルを印刷するとどういうわけか文字が網掛けしたような状態でプリントされる。Acrobatでもプレビューを使っても、どうも黒々とくっきり印刷してくれない。そこで、ubuntuから印刷させることにした。メニューにあるプリンター設定ユーティリティを使って設定しようとしたが、Okidataのプリンター一覧に18NRはない。どうしようかと思ってgoogleで検索したら自分の日記に「OL810e/PSを選んだら問題なく印刷できた」と書いてあるのが出てきた。しかも、そんなに昔ではなく半年ほど前のことだった。情けない。とにかく今回もOL810e/PSを選んだら問題なく印刷できた。前と違うのはネットワーク上のプリンターとして18NRが自動的に認識されていたことだ。印刷してみると、pdfも黒々くっきり印刷できた。よかったよかった。
ついでにBrother MFC-6800Jの印刷やスキャナを使ってみようかと思ってドライバーをダウンロードしてインストールしたのだが、うまくできなかった。印刷もスキャンも。ML 18NRで印刷できるようになったからいいんだけどさ。
2007-10-07 17:46:32
今日は日曜日なので、主にMacOSXで作業。Carbon Emacsの2007年夏版を何の気なしにダウンロードして古い版と入れ替えた。その後、またもや何の気なしにbibtexファイルをダブルクリックしたところ、HyperBibDBというアプリケーションでファイルが開いた。あれ? さっきまでEmacsで開いていたのに。このHyperBibDBって何?
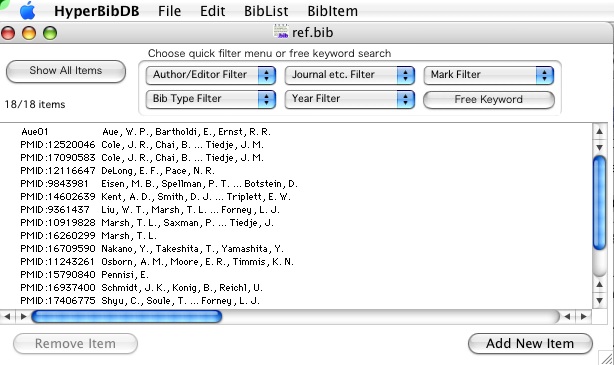
吃驚して調べてみたところ、ありました、HyperBibDB。もともとMacOSXに入っているはずはないので、自分で入れたのだろう。しかし、全く覚えていない。いつ入れたんだろう。便利なのだろうか。よく判らない。
2007-10-07 14:16:05
楽天書籍検索APIは使いづらい。楽天全体のウェブサービスと構造が共通だから、書籍検索だというのに書名とか著者とか出版社といった項目で情報が提供されていない。ひょっとしたら私の勘違いかも知れないが、今のところはそうとしか思えないのだ。
ふと思いついて、オンライン書店で売れている本を表示させるページを作ってみた。困ったのが楽天ブックスの商品画像。アフィリエイト契約条項に画像提供が含まれているようなので、画像を取得するのは悪いことではないはずだ。試行錯誤の末、http://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/0000/00000000.jpg?_ex=128x128と指定すれば取れることが判った。この00000000のところに入れる番号が、書籍のIDとは違う番号だというところがまた腹立たしい。なぜそういうことをするんだ。面倒臭いなあ。
やっと見つけたことなので、忘れないようにここに書き留めておく。
できあがったページはなんとなくすっきりしない。やはり左右が揃っていないからか。
最新の日記に戻る