2008-08-31 15:38:39
昨日どうしてもre.findallが文章を分割して拾い上げてくれないと文句を云っていた件は、普通の正規表現は改行を飛び越えて対象を処理しないという基本的なことを忘れていたのが原因だった。そんなことに気づくのに二日もかかるとは! といふことで、改行を削除して処理したら何とかなった。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cgi
import wsgiref.handlers
from google.appengine.ext import webapp
from google.appengine.api import urlfetch
import urllib
import re
from re import *
class MainPage(webapp.RequestHandler):
def get(self):
self.response.out.write("""
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<title>TechnoratiKWIC</title>
</head>
<body>
<h2>TechnoratiKWIC</h2>
<form action="/kwic" method="post">
<div><input type="text" name="word" ></div>
<div>言語:
<select name="lang">
<option value="ja" selected>日本語</option>
<option value="ko">韓国語</option>
<option value="zh">中国語</option>
<option value="en">英語</option>
<option value="de">ドイツ語</option>
</select>
結果数:
<select name="limit">
<option value="20" selected>20</option>
<option value="50">50</option>
<option value="100">100</option>
</select>
</div>
<div><input type="submit" value="検索"></div>
</form>
<p>調べたい語句を入力し、言語と結果数を選び、検索ボタンを押してください。\\
<br />検索は<a href='http://www.technorati.com/' target='blank'\\
>Technorati</a>のウェブサービス(API)を利用します。</p>
<p><img src="http://code.google.com/appengine/images/\\
appengine-noborder-120x30.gif" alt="Powered by Google App Engine" /></p>
</body>
</html>""")
def kwic(word,lang,limit):
re_excerpt = re.compile('<excerpt>.+?</excerpt>')
re_title = re.compile('<title>.+?</title>')
re_link = re.compile('<permalink>.+?</permalink>')
tags = re.compile('<.+?>')
query = {'key':'xxxxxx','query':word.encode('utf-8'),'language':lang,'limit':limit}
url = 'http://api.technorati.com/search?' + urllib.urlencode(query)
xml = urlfetch.fetch(url).content
xml = xml.replace('\n',' ')
results = []
items = re.findall('<item>.+?</item>',xml)
if len(items) < limit:
items.pop()
for item in items:
link = tags.sub('',re_link.search(item).group())
title = tags.sub('',re_title.search(item).group()).decode('utf-8')
excerpt = tags.sub('',re_excerpt.search(item).group()).decode('utf-8')
res = {'excerpt':excerpt,'title':title,'link':link}
results.append(res)
return results
class Result(webapp.RequestHandler):
def post(self):
re_word = re.compile('<strong.+?</strong>')
word = self.request.get('word')
lang = self.request.get('lang')
if lang == ('ja' or 'ko' or 'zh'):
width = 20
else:
width = 30
limit = self.request.get('limit')
results = kwic(word,lang,limit)
table = "<table border='0'>"
for r_item in results:
rtm = r_item['excerpt'].replace('<','<')
rtm = rtm.replace('>','>')
rtm = rtm.replace('"','\"')
blcks = re_word.split(rtm)
keys = re.findall('<strong.+?</strong>',rtm)
if len(blcks) > 1:
for i in (range(len(blcks)-1)):
row = "<tr><td align='right'>"+blcks[i][(len(blcks[i])-width):]+\\
"</td><td align='center'>"+keys[i]+"</td><td>"+blcks[i+1][0:width]+\\
"</td><td><a href='"+r_item['link']+"' target='_blank'>"+\\
r_item['title'][0:10]+"</a></td></tr>\n"
table += row
table += "</table>"
self.response.out.write('<html xmlns="http://www.w3.org/1999/xhtml" \\
xml:lang="' + lang + '">\n<head>\n<meta http-equiv="content-type" \\
content="text/html; charset=UTF-8" />\n<title>TechnoratiKWIC</title>\n\\
</head>\n<body><h2>TechnoratiKWIC</h2>\n<p>Keyword = <strong>')
self.response.out.write(cgi.escape(word))
self.response.out.write('</strong></p>\n')
self.response.out.write(table)
self.response.out.write('<p><img src="http://code.google.com/appengine/\\
images/appengine-noborder-120x30.gif" alt="Powered by Google App Engine" \\
/></p></body></html>')
def main():
application = webapp.WSGIApplication([('/', MainPage),
('/kwic', Result)],
debug=True)
wsgiref.handlers.CGIHandler().run(application)
if __name__ == '__main__':
main()
説明は今日は面倒臭いので省略。すみませんね。まあ、読みたい人もいないでしょうが。強調はTechnoratiから返ってきた結果をそのまま使ってみるようにしたので、入力した語と必ずしも一致しない。複合語は分割されてしまうこともある。検索語にスペースが入っていると、変なことになる。そこは解決しなければ。あと、不思議なことにロシア語を検索すると下のような変なことになってしまうのだ。何なんだこれは。
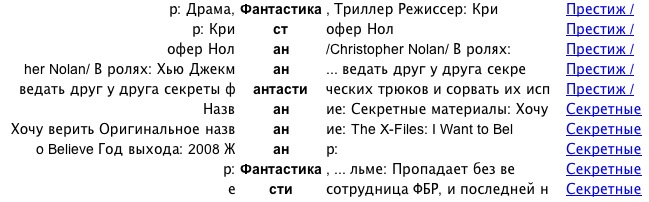
仕方がないのでとりあえずロシア語は外しておこう。それで、technoratikwic.appspot.comにて動かせるようにしてみた。KWICばかり作ってなにしているんだろうと思うけれども、これをやらないと始まらないから。全然理由になっていないけど。
2008-08-30 19:59:36
数日前にAmazon ECS(旧称)から返ってくる情報を正規表現で処理して一人悦に入っていたわけだが、今日はこんな記事(「金魚撥の技術メモ:Google App EngineでWEBサービスを使う」)を見かけたので、真似してみた。でも、できなかった。どうして他のみんなはできるのに自分だけできないんだろうと気分が沈んだ。
いや、Amazon ECS(旧称)はそんなことしなくていいんだから、もっと新しいことを考えよう。今日はTechnoratiのAPIを利用してみよう。もちろん、Google App Engineで。今日もElementTreeを試してみて失敗。でも、こっちには正規表現があるんだと思って、Amazon ECS(旧称)と同様の方法で処理したんだが……できなかった。なぜだ。AttributeError: 'NoneType' object has no attribute 'group'なんてエラーが出るのだ。変だなと思って、Technoratiから返ってきたXML文書を保存してローカルでターミナルからpythonで処理してみるとちゃんと目的のタグの間を抜き出せるのだが。ただ、findallはうまく動かなかった。まったく理解できない。これで、何時間も空しい時間が流れてしまった。一度始めると気になってなかなか止められない。そういう性格なのだ。
Technoratiだと一回に100件まで受け取れるし、キーワードを含む文書件数の時間経過も提供してくれたり、いろいろ興味深いのに。
自宅サーバでPHPを使ったスクリプトを書けば簡単に処理できるような気はするのだが、今はいろいろとGoogle App Engineで動かせるように調べる期間なので、そう簡単には引き下がれない。
2008-08-29 21:52:57
Yahoo!検索APIで作ったKWICサイトに不満があるので、Google Search APIを使ってみようと考えた。前にIDを取得したことがあるのだが、長らく使っていなかったのだ。何だか、新規申し込みが停止されたとか云うニュースを読んだ記憶がある。この頃はどうなっているんだろうと思ったら、Não Aqui! » Google Search REST API を Python から使うという記事を見つけた。へえ、そうだったのか。Google AJAX Search APIを使えばよかったのか。全然知らなかった! ajaxという言葉に恐怖を感じる私はこの存在を知っていたけれども、近寄らなかったのだ。このサイトのおかげで何となくpythonで情報を受けとる方法や解ったのだが、私は自分の計算機ではなくGoogle App Engineで使いたい。どうしたらいいのだろう。
と思っていたら、Google App Engineで、外部にあるJSON形式のファイルを読み込むという記事を見つけた。へえ、Djangoユーティリティからsimplejsonをインポートするといいのか。Django なんて私は知らないから、そんなこと思いつくはずもない。この二つのサイトを参考に、見よう見真似で何とか動作確認までやってみた。「London」という単語を検索してみよう。別にロンドンに拘る意味はない。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import wsgiref.handlers
from google.appengine.ext import webapp
from google.appengine.api import urlfetch
from django.utils import simplejson
class MainPage(webapp.RequestHandler):
def get(self):
query = 'London'
url = 'http://ajax.googleapis.com/ajax/services/search/web?\\
key=xxxxxxxxxx&v=1.0&q='+query
result = urlfetch.fetch(url)
if result.status_code == 200:
a = simplejson.loads(result.content)
results = a['responseData']['results']
self.response.out.write("<html><body><h1>Test</h1>")
self.response.out.write("<table border='1'><tr><th>title</th><th>content</th></tr>")
for r in results:
self.response.out.write("<tr><td>%s</td>" % r['title'].encode('utf-8'))
self.response.out.write("<td>%s</td>" % r['content'].encode('utf-8'))
self.response.out.write("</table></body></html>")
def main():
application = webapp.WSGIApplication(
[('/', MainPage)],
debug=True)
wsgiref.handlers.CGIHandler().run(application)
if __name__ == "__main__":
main()
API Keyはなくてもいいらしいのだが、できればとってくれみたいに書いてあったので、取得してみた。結果は、こんな感じ。
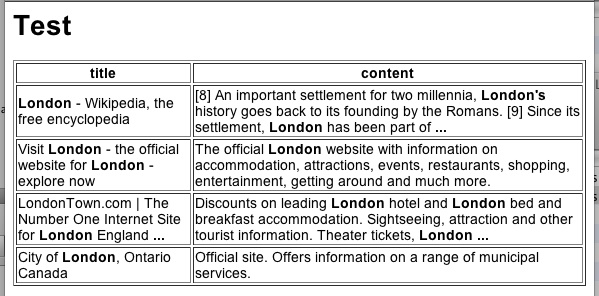
一見、ちゃんと情報を取ってきたように見えるのだが、たった4件? ロンドンに関する情報が4件? そんなわけがないだろう。一体どういうことなんだ。最大4件などと制限をかけてはいないはずだが。困ったな、これは。
2008-08-28 21:37:12
Yahoo!検索Webサービスから返ってくるXMLはElementTreeで受けられるようになったのだが、Amazon A2S (ECS 4.0) がどうしても処理できない。minidomも試したのだけど、どうにもならない。何週間も情報を探し求めたのだが、答えに辿り着かない。どうして、こんなことを探さなければならないんだ。他の方法を探そうと心に決めた。もうElementTreeもminidomも使ってやらない。XMLだからってちょっと生意気じゃないか。普通の文字列として処理してやりゃあいいじゃないか。ということに気がついて、正規表現で切り刻んでやった。今頃謝っても許してやらないからそのつもりでいるように(謝られたりはしていないが)。
#!/usr/bin/env python # -*- coding: utf-8 -*- #
import cgi import wsgiref.handlers
from google.appengine.ext import webapp from google.appengine.api import urlfetch import urllib import re from re import *
class MainPage(webapp.RequestHandler): def get(self): self.response.out.write(""" <html> <body> <h2>amazon-search</h2> <form action="/result" method="post"> <div><input type="text" name="word" ></div> <div><input type="submit" value="Submit"></div> </form> </body> </html>""")
def amazon(word): re_asin = re.compile('<ASIN>.+?</ASIN>') re_title = re.compile('<Title>.+?</Title>') tags = re.compile('<.+?>') query = {'Service':'AWSECommerceService','AWSAccessKeyId':'xxxxxxxxxxx',\\ 'Operation':'ItemSearch','SearchIndex':'Books','Sort':'-publication_date',\\ 'Keywords':word.encode('utf-8'),'ResponseGroup':'Medium'} url = 'http://webservices.amazon.co.jp/onca/xml?' + urllib.urlencode(query) xml = urlfetch.fetch(url).content items = findall('<Item>.+?</Item>',xml) res = [] for item in items: ASIN = tags.sub('',re_asin.search(item).group(0)) title = tags.sub('',re_title.search(item).group(0)).\\ decode('utf-8') res.append(ASIN+' : '+title) return res
class Result(webapp.RequestHandler): def post(self): word = self.request.get('word') res = amazon(word) results = '<br />'.join(res);
self.response.out.write('<html><body><h2>\\ Amazon Search</h2>Keyword=') self.response.out.write(cgi.escape(word)) self.response.out.write('<br />\n <pre>') self.response.out.write(results) self.response.out.write('</pre></body></html>')
def main(): application = webapp.WSGIApplication([('/', MainPage), ('/result', Result)], debug=True) wsgiref.handlers.CGIHandler().run(application)
if __name__ == '__main__': main()
まず、urlfetch.fetch(url).contenで受け取ったXMLを<Item>〜</Item>で分割する。結果はリストに収納されるので、Itemごとにやはり正規表現で<Title>とか<ISBN>とか抽出していけばいい。上では、題名とASINを抜き出している。日本語の文字列はdecode('utf-8')としてやらないと読める文字にならない。試しに「食虫植物」で検索してみると下の画像のようになった。
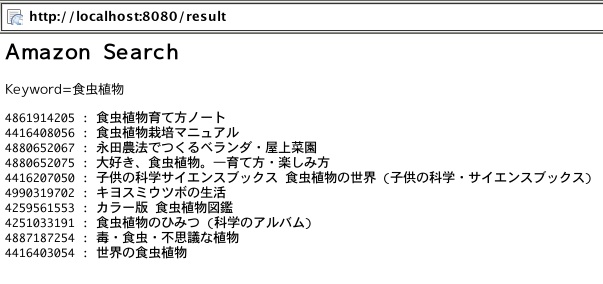
なんだ、簡単じゃないか。XMLだからって偉そうに人を馬鹿にしやがって。さて、これで何を作るかはまだ考えていない。
2008-08-27 22:47:27
昨日のYahooKWICに英語やドイツ語、ロシア語も選べるようにしてみた。でも、ロシア語などはあまりいい結果が返ってこないような気がする。読めないからよく解らないけど。Yahooはロシア語サイトはあまり集めていないのだろうか。そんなことはないと思ふのだが。英語やドイツ語の結果も驚くほど少ないことがある。英語は英語のYahooサイト、ドイツ語はドイツ語のYahooサイトで検索した方がいいのかな。今度アメリカのサイトで検索して比較してみよう。
さて、ロシア語の表示なのだが、MacOSXのSafariで見るとこんな感じなのだが、

ubuntuのEpiphanyだと下のように間延びした表示になってしまうのだ。
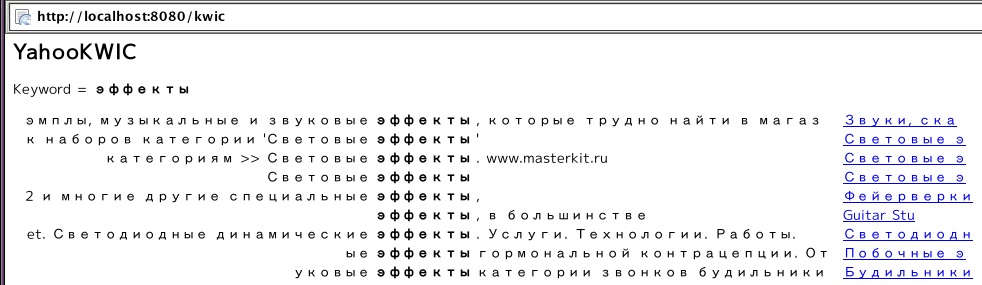
いろいろフォント設定を変えたりしても、このままである。ロシアのサイトを見に行けばちゃんと表示されるのだが。ubuntuのMozillaを使えば、まあこんな感じでそれなりにまともに表示される。

それはさておき、この結果ではどうも満足できない。しっかりした文章の例が出てこない割合が高すぎる。何とかWeb上の文書を綺麗に検索・表示するKWICサイトを作れないものか。
2008-08-26 22:18:01
ここ三週間ばかり、Google App EngineやらAmazon EC2に悩んでいた。どうもよく解らない。うまく使えない……
自宅サーバの管理も面倒臭いからこういうものを積極的に利用していこうかと思いながらも、やはり手元に本体があるのが何かと使いやすいような気もするし……何がいいのかと。そんな深刻な悩みじゃありませんが。
何か使ってみたいと思って試してみたのが、Yahoo!検索Webサービスを利用して検索をして、結果をKWIC(keyword in context)で表示しようというもの。前に作ったことがあるのだけど、あまり出来がよくないので作り直したかったのである。このときはPHPで作ったが、Google App Engineなので今回はPythonだ。とりあえず、こんなふうにしてみた。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import cgi
import wsgiref.handlers
from google.appengine.ext import webapp
from google.appengine.api import urlfetch
import urllib
import xml.etree.cElementTree as ET
class MainPage(webapp.RequestHandler):
def get(self):
self.response.out.write("""
<html>
<body>
<h2>KWIC-search</h2>
<form action="/kwic" method="post">
<div><input type="text" name="word" ></div>
<div>
<select name="lang">
<option value="ja" selected>日本語</option>
<option value="ko">韓国語</option>
<option value="szh">中国語(簡体字)</option>
<option value="tzh">中国語(繁体字)</option>
</select>
<select name="resnum">
<option value="20" selected>20</option>
<option value="50">50</option>
</select>
</div>
<div><input type="submit" value="検索"></div>
</form>
</body>
</html>""")
def kwic(word,lang,resnum):
query = {'appid':'xxxxxx','query':word.encode('utf-8'),\\
'language':lang,'results':resnum}
url = 'http://search.yahooapis.jp/WebSearchService/V1/webSearch?'\\
+ urllib.urlencode(query)
xmlns='{urn:yahoo:jp:srch}'
xml = urlfetch.fetch(url).content
dom = ET.fromstring(xml)
results = []
for item in dom.findall(xmlns + 'Result'):
summary = item.findtext(xmlns + 'Summary')
title = item.findtext(xmlns + 'Title')
clickurl = item.findtext(xmlns + 'ClickUrl')
res = {'summary':summary,'title':title,'clickurl':clickurl}
results.append(res)
return results
class Result(webapp.RequestHandler):
def post(self):
word = self.request.get('word')
lang = self.request.get('lang')
resnum = self.request.get('resnum')
results = kwic(word,lang,resnum)
table = "<table border='0'>"
for r_item in results:
prts = r_item['summary'].split('...')
for part in prts:
if part.find(word) > 0:
lr = part.split(word)
trow = "<tr><td align='right'>"+lr[0][(len(lr[0])-20):]\\
+"</td><td><strong>"+word+"</strong></td><td>"+lr[1][0:20]\\
+"</td><td><a href='"+r_item['clickurl']+"' \\
target='_blank'>"+r_item['title'][0:10]+"</a></td></tr>"
table += trow
table += "</table>"
self.response.out.write('<html><body><h2>KWIC-yahoo</h2>\n\\
<p>Keyword = <strong>')
self.response.out.write(cgi.escape(word))
self.response.out.write(('</strong></p>\n'))
self.response.out.write(table)
self.response.out.write('<hr /></body></html>')
def main():
application = webapp.WSGIApplication([('/', MainPage),
('/kwic', Result)],
debug=True)
wsgiref.handlers.CGIHandler().run(application)
if __name__ == '__main__':
main()
これの、for item in dom.findall(xmlns + 'Result'):のところが解らなくて、何日も何週間も悩んでいたのだ。こんなこと誰も教えてくれない。何でみんな解るんだ? とにかくこれでやっと結果を処理できるようになったのだ。返ってきた結果にには検索語が複数入っていることがある。たいていは「...」で分割されているので、なるべくそれも反映するようにしてみた。今日は余裕がないので、四言語しか選べないようになっているけれども、これは後で追加したい。
これはhttp://yahookwic.appspot.com/で使えるようにしておいた。たくさん結果を集めて前後の単語の頻度順なんかで並べ替えられるようにすると格好いいのだが、今はそんなことをする元気はない。日本語だと形態素解析とかしなければならないし。がんばってやったことはあるんだけど。
2008-08-02 21:55:01
アプリケーションのアップロードは、ZDNet Japanの記事を参考にした。ほとんどそこに書いてある通りなのだが、
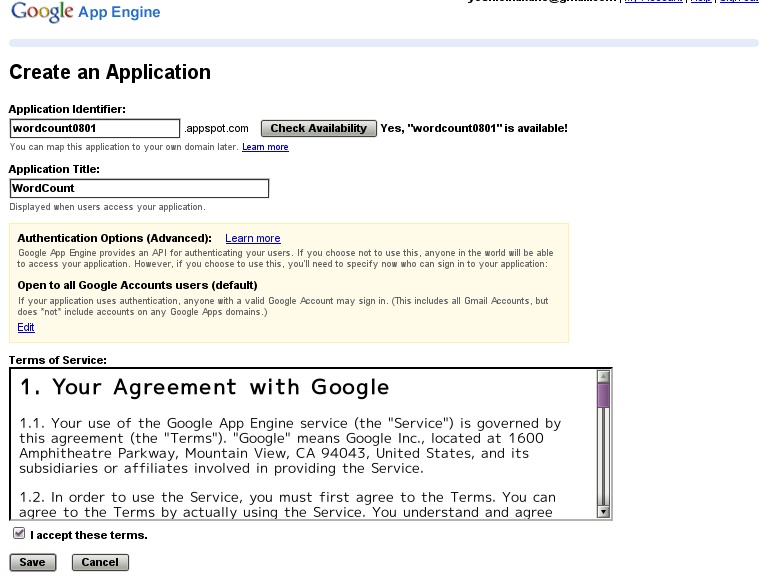
ここのところで、Application Identifierにwordcountを使おうとしたら、すでに使っている人がいるのか、駄目だと云われてしまい、wordcount0801という名前にした。そしてSaveをクリックすると、こんな画面が! (ここではなかったかも。実はよく覚えていないが、この一連の作業のどこかに出てきたのだ)
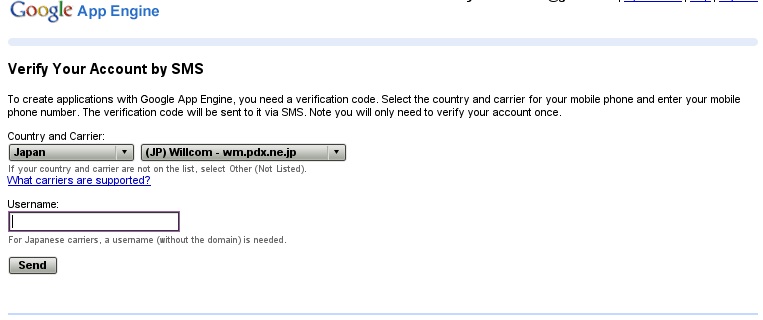
何だこれは? 携帯電話なんか私は持っていないのだが。と思ったが、Wilcomが使えるので大丈夫だった。Wilcomのユーザ名(メールアドレスの@の前)を入れて送信すると、暗証番号が携帯メールに送られてくる。それを入力して初めて、次に進めるのだ。そんな話は聞いていないのでちょっと慌てた。無事に、
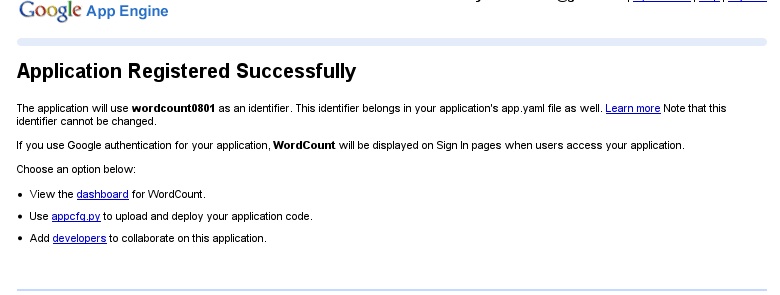
という画面が出た。
そこで、先ほどの作業ディレクトリに戻って、
appcfg.py update wordcount0801/というコマンドを実行すると、アップロードできるという訳である。アクセスしてみると、動いているようじゃないか! 多少なりともPythonが使えてよかった。RubyとかPHPは使えないのだ。
ただでこんなことができるなんてGoogleは太っ腹ではないかと喜び、本当の目的にアプリケーションを作ってアップロードした。その内容はここには書かない。秘密である。今度は携帯メールに合い言葉が送られてきたりはしない。その代わり、「これをアップロードしたらあと8個アプリケーションを作れることになりますよ」という表示が出る。どうやら全部で10個しか作れないらしい。無料だし、まだpreview releaseだし。私には10個も作れれば十分だと思い、アップロードして動かしてみたら、DeadlineExceededErrorというエラーが出てしまった。タイムアウト時間は約8秒らしい。ローカル環境でできないこと、あるいは時間がかかりすぎることをやってもらおうと思っていたのに。残念。他の動作環境を探さなければ。そこで考えたのが、Amazon EC2である。その話は明日以降。
2008-08-02 21:18:46
実際にアップロードするアプリケーションがHello World!ではあまりにも情けないので、今年二月に書いたPython練習帖:単語を数えるを使ってみることにした。wordcount0801というディレクトリを用意し、そこで、
import cgi
import re
from google.appengine.api import users
from google.appengine.ext import webapp
from google.appengine.ext.webapp.util import run_wsgi_app
class MainPage(webapp.RequestHandler):
def get(self):
self.response.out.write("""
<html>
<body>
<form action="/result" method="post">
<div><textarea name="content" rows="3" cols="60"></textarea></div>
<div><input type="submit" value="Count!"></div>
</form>
</body>
</html>""")
class Wordcount(webapp.RequestHandler):
def post(self):
self.response.out.write('<html><body>Result:<pre>')
content = cgi.escape(self.request.get('content'))
if len(content) < 10000:
noLine = re.sub('(\n)+', ' ', content)
sLine = re.sub('[.!:?]', ' ', noLine)
sLine2 = re.sub("[,\-']", ' ', sLine)
sLine3 = re.sub("[,';:]", '', sLine2)
sLine3 = re.sub('"', '', sLine3)
words = sLine3.split(' ')
words = [w for w in words if len(w) > 0]
wDict = {}
for w in words:
if wDict.has_key(w):
wDict[w] += 1
else:
wDict[w] = 1
keys = wDict.keys()
keys.sort()
optxt = ""
for key in keys:
optxt += key + ":" + str(wDict[key]) + "\n"
optxt += '\n There are a total of ' + str(len(wDict)) + ' words in this text.'
else:
optxt = 'Your text is too long for this application to count words'
self.response.out.write(optxt)
self.response.out.write('</pre></body></html>')
application = webapp.WSGIApplication(
[('/', MainPage),
('/result', Wordcount)],
debug=True)
def main():
run_wsgi_app(application)
if __name__ == "__main__":
main()
というPythonのスクリプトを書いて、これをwordcount.pyとして保存する。次に、app.yamlというファイルを用意する。
application: wordcount0801 version: 1 runtime: python api_version: 1 handlers: - url: /.* script: wordcount.pyこれがローカル環境で動いたので、これが無事にアップロードできれば、http://wordcount0801.appspot.comで利用できるようになるはずだ。それはまた、次項で。
2008-08-02 20:56:44
Google App Engineというのが話題になっていたらしいのだが、世間の流行にあまり関心のない私はよく知らなかった。が、突然「便利なのかも知れない!」と思い、使ってみることにした。
申請が面倒くさいかと思ったら、Googleアカウントを持っていれば簡単らしい。まずは、ローカル環境でプログラムを書くための設定をすることとした。
ダウンロードページでLinux版Google App Engine SDKをダウンロード。zipファイルなので展開して適当なところに置く。とりあえず、ホームディレクトリに置いた。dev_appserver.pyとappcfg.pyのシンボリック・リンクをパスの通っているディレクトリに張った。
動作確認はhello worldと決まっているらしいので、Hello, World!に書いてあるように、helloworld.pyとapp.yamlの2ファイルを作ってhellowというディレクトリに置いた。ディレクトリはどこに作ってもいいのだと思う。とりあえず、さっき展開したフォルダの中に作った。hellowディレクトリの一つ上の階層で
dev_appserver.py hello/と打つと、
INFO 2008-08-01 02:12:09,432 appcfg.py] Server: appengine.google.com Allow dev_appserver to check for updates on startup? (Y/n): Y dev_appserver will check for updates on startup. To change this setting, edit /home/tolle_et_lege/.appcfg_nag INFO 2008-08-01 02:12:14,915 appcfg.py] Checking for updates to the SDK. INFO 2008-08-01 02:12:15,532 appcfg.py] The SDK is up to date. WARNING 2008-08-01 02:12:15,532 datastore_file_stub.py] Could not read datastore data from /tmp/dev_appserver.datastore WARNING 2008-08-01 02:12:15,532 datastore_file_stub.py] Could not read datastore data from /tmp/dev_appserver.datastore.history INFO 2008-08-01 02:12:15,698 dev_appserver_main.py] Running application helloworld on port 8080: http://localhost:8080 INFO 2008-08-01 02:22:16,804 dev_appserver.py] "GET / HTTP/1.1" 200 - INFO 2008-08-01 02:22:16,805 dev_appserver_index.py] Updating /home/tolle_et_lege/googleApp/hello/index.yamlというような状態になる。そこで、ブラウザでhttp://localhost:8080を開くと、下のようなhellow worldという表示が出る。
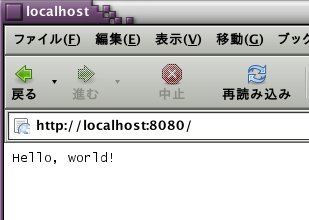
プログラムのアップロードなどは次項で。
最新の日記に戻る