2008-06-26 23:19:06
ubuntuにインストールしたATOK X3 for Linuxをいろいろ試してゐたら、自分で作った歴史的仮名遣ひ辞書を標準辞書に追加したり、ユーザ辞書として追加したりしゐたのだけれども、この頃のATOKの場合、「文語モード」にすればそれだけでもう問題なく歴史的仮名遣ひが変換できるやうだ。前から「文語モード」のことは知ってゐたのだが、「文語モード」っていふくらゐだから、文語で書かなければならないと思ひこんでゐたのだ。普通の現代文(口語文)を入力してもちゃんと変換してくれるではないか。標準モードだと、自分でハ行四段活用の動詞を追加して、たとへば「云ふ」といふ語を登録して安心してゐても、「いはう」と入力しても「云はう」と変換されないのである。未然形(已然形)は標準モードでは変換してくれないのである。それが、文語モードでは「いはう」と入力すれば「云はう」と変換してくれる。私が大事に育ててきた歴史的仮名遣ひ変換用辞書は不要だったやうだ。この際、MacもATOKにしてしまはうかな。ATOK 2008 for Mac
といふのが来月出るといふではないか。買ってしまはうか。さうして、文語モードで使ってみようか。
ああ、気がついたら歴史的仮名遣ひで書いてゐるぢゃないか。ここでは現代仮名遣ひで書くことにしてゐたのに。まあ、いいか、今日は。
2008-06-24 22:19:11
さて、昨日も書いたように、MacOSXのegbridge u2で使っていたユーザ辞書を移行したい。歴史的仮名遣いの変換用辞書を以前作ったからだ。これはどこかで買えるものではないのだ。
まずegbridge universal 2のユーザ辞書を「辞書管理ツール」を使ってメニューから「テキストへ書き出し」を選び、egbridgeテキスト形式で書き出す。文字コードがutf-16になっていたので、utf-8に変換して保存。
つ微にこのファイルをubuntuへコピーして、ATOKの「辞書メンテナンス」から「辞書ユーティリティ」を選び、「一括処理」をクリック。ATOK辞書を「ユーザー辞書(標準)」あるいは新規に作成したユーザ辞書(たとえば旧仮名辞書とかいう名前を付けてもいい)にして、「単語ファイル」を選ぶ。「登録」をクリックすると、
登録できた語:976 登録できなかった語:67という表示となって完了。登録できなかったものがあるのは、egbridgeにあってATOKにない種類があるからだろう。ユーザ辞書(標準)に追加した場合は、そのまま新規登録した語が使えるようになっている。別に歴史的仮名遣い用辞書を作った場合は、ATOKの環境設定で辞書セットに追加すると使えるようになる。たとえば、「うゑる」と打って変換すると下のような候補が示されるわけだ。
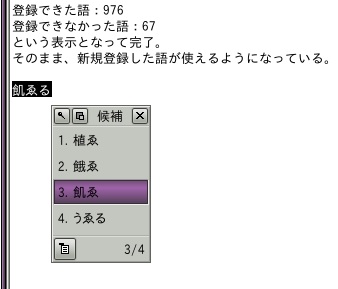
その品詞がegbridgeにあってATOKにないのかというようなことは、また明日見てみよう。
2008-06-23 22:51:09
ATOK X3 for Linuxをubuntu 8.04にインストールした。オンライン版を7350円で購入した。
今月12日にubuntu 8.04が正式対応となり、Ubuntu 8.04 LTSでのインストール方法というページもできたので、それにしたがって操作すれば簡単にインストールできる。「[Ctrl]+[Alt]+[F2]キーを押して仮想端末に切り替わる」とか「言語を変更する」とか書いてあるけれども、私はただ普通のターミナルで、
sudo touch /etc/gtk-2.0/gtk.immodules cd ATOKX3 sudo bash ./setupatok_deb.sh cd ../atokx3up1 sudo bash ./setupatok_up1_deb.sh sudo bash /opt/atokx3/sample/setting_debian4.shとやって再起動しただけだが、ちゃんと使えるようになった。もちろん、私はこの方法でも必ず使えるようになると保証している訳ではない。上のは、ATOKX3とアップデートモジュールを同じディレクトリに置いた場合のものである。
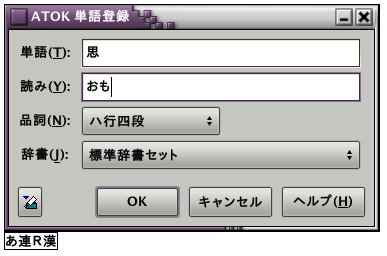
どうしてATOKを使いたかったのかというと、ハ行四段の動詞を登録したかったからである。「云ふ」とか「思ふ」とか。MacOSXではegbridgeとATOKでこれができたのだが、egbridgeの販売と開発が終わってしまって、何れはMacでもATOKを使うことになるだろうと思っていたので、まずはubuntuの方から始めることにしたのだ。おお、ちゃんとハ行四段の動詞が登録できるではないか! 嬉しい。次は、MacOSXのegbridge u2で使っていたユーザ辞書を移行する話である。
2008-06-22 00:22:56
昨日のスクリプトですが、「:」があってsimplexml関数を使うとうまく要素が取りだせないと書いたのは、確かにそうなのです。しかし、そこで簡単に諦めたのはいけなかった。「:」が困るのなら、置き換えればよかったのです。ということで、以下に示したようにして、simplexmlでもっとすっきりと情報を取得できました。
$data = file_get_contents("ids.txt");
$ids = explode("\n",$data);
$url = "http://www.dailymotion.com/rss/search/xxxxxx/1";
$rss = file_get_contents($url);
$rss = str_replace(":","_",$rss);
$xml = simplexml_load_string($rss);
foreach($xml->channel->item as $item){
$id = $item->dm_id;
$flv_url = $item->media_group->media_content[1]['url'];
$flv_url = str_replace("80x60","320x240",$flv_url);
$flv_url = str_replace("http_","http:",$flv_url);
if(!in_array($id,$ids)){
$curl = "curl -L -o 'flv_files/".$id.".flv' '".$flv_url."'";
exec($curl);
file_put_contents("ids.txt","\n".$id,FILE_APPEND);
}
}
2008-06-21 19:24:42
私は半年ほど前まで動画共有サイトなんてほとんど利用したことがなかった。ふとしたことから、今は毎日のように新着情報を確認しているのだから、世の中何がどう変るか予測できない。
さて、MacOSXでは(もちろんWindowsでも)RealPlayerの11以降をインストールしていれば、動画を観ると自動的にRealPlayer Downloaderというのが動き出して動画ファイルを保存してくれる。でも、Linuxではそんな都合のいいものはないようだ。それに、病気で数日寝込んでいても、自動的に新着情報を確認してファイルを保存しておいてくれれば、ゆっくり保養できるというものだ。今日はPHPで試みてみる。Dailymotionという動画共有サイトの場合。
情報源として新着情報を取得するRSSのURLを利用する。www.dailymotion.com/rss/search/xxxx/1といふようなURLのはずだ。このxxxxというところにキーワードが入っている。IDを記録して、一度ダウンロードしたファイルを記録するids.txtというファイルを作る。もちろん、名前は何でもいい。ダウンロード用のflv_filesというフォルダを用意し、ファイルを保存できるような権限にしておく。そして、下のようなPHPスクリプトを書いてみた。
$data = file_get_contents("ids.txt");
$ids = explode("\n",$data);
$url = "http://www.dailymotion.com/rss/search/xxxx/1";
$xml = file_get_contents($url);
$items = explode("<item>",$xml);
array_shift($items);
array_pop($items);
foreach($items as $item){
$media0 = strpos($item,"<media:group>");
$media1 = strpos($item,"</media:group>",$media0);
$media = substr($item,$media0,$media1-$media0);
$links = explode("<media:content url=",$media);
$flv_url = substr($links[2],0,strpos($links[2]," type="));
$flv_url = str_replace("80x60","320x240",$flv_url);
$id0 = strpos($item,"<dm:id>");
$id1 = strpos($item,"</dm:id>",$id0);
$id = strip_tags(substr($item,$id0,$id1-$id0));
if(!in_array($id,$ids)){
$curl = "curl -L -o 'flv_files/".$id.".flv' ".$flv_url;
exec($curl);
file_put_contents("ids.txt","\n".$id,FILE_APPEND);
}
}
curlが必要なので、まだなかったらインストールする。ここでは、ファイル名はIDになる。もっと判りやすいものにしてもいいのかも知れない。curlで-Lを付けないと何もダウンロードできない。このオプションの意味が解らない人はご自分で調べていただきたい。flvファイルのurlにある"80x60"を"320x240"にしないと小さい画面のflvファイルがダウンロードされてしまうので後で悲しい思いをすることになる。
これをcronで週に一回とか一日一回とか動かしてやれば、自動的にファイルが保存されていくと思う。
PHPではXMLを扱うのにsimplexmlなど便利な関数があるのだが、コロンの付いたタグの扱い方が解らなかったので、愚直に文字列を刻んだ。curl関数というのもあるが、使い方を知らないので、こうしてみた。難しいことは苦手なのだ。
この方法で誰もが望み通りの結果が得られるとは私には保証できない。悪いものをダウンロードしてしまっても私は責任を取れないことを予めご了承願いたい。
2008-06-16 21:15:06
この頃はデスクトップに好みの「壁紙」を貼り付けて作業をする人も多いようだが、私はアイコンが見づらいからあまり派手なデスクトップは好きではない。MacOSX10.2か何かのときについてきた青地に飛行機雲みたいな帯が流れているのを使い続けてきた。その画像ファイルをubuntuにも持っていって同じ背景にしていたのである。
しかし、思い起こしてみれば、昔のMacのデスクトップは大抵灰色だったのではなかったか。あれが一番落ち着く。そう思ってデスクトップを灰色にした。気分はすっかり灰色である。落ち着くなあ。ついでに、表示言語をドイツ語にした。落ち着くなあ。
おや、どうして月と曜日の表示が英語のままなんだ? どこで変えたらいいんだ。それはまあ、どうでもいいことだが、「計算機」(デスクトップに出現する電卓)で小数の計算ができなくなってしまった。ドイツ人は整数しか使わないのか。どうなっているんだ。そんなわけで、計算したいときは、ターミナルにRを出して計算している。それでまったく不自由はないけれど。
2008-06-15 17:26:27
XML文書を変換してpdfを作ってくれるxsl-foとかいう仕組みがあるらしい。これは面白い。TeX以外の手段も確保しておきたいということで、早速試してみた。まずApacheのFOPのサイトからbinary版をダウンロードしてきて、適当なところにおいて、fopのシンボリックリンクを/usr/local/binにでも張るだけである。これでubuntuでもMacOSXでも動いた。問題は日本語である。
今のところ使える日本語フォントはTTFだけらしい。ちょっと困るのだが、そういうことなのだから私にはどうにもできない。最初にfont metricsとやらを作成した。フォントはMacで使っていた平成明朝を使用した。ubuntuではホームディレクトリ下の.fontsフォルダに入っている。MacOSXではホームディレクトリ下のLibrary/Fonts/に入っている。fop-0.94の中(下)にfontsというディレクトリ(フォルダ)を作って、そこにmetricsを作らせるために、
java -cp build/fop.jar:lib/commons-logging-1.0.4.jar:lib/commons-io-1.3.1.jar\\ org.apache.fop.fonts.apps.TTFReader /home/username/.fonts/HeiseiMincho-W3.ttf\\ fonts/heisei-mincho.xmlとやると、
Parsing font... Reading /home/username/.fonts/HeiseiMincho-W3.ttf... Font Family: HeiseiMincho Creating xml font file... Creating CID encoded metrics... Writing xml font file fonts/heisei-mincho.xml... This font contains no embedding license restrictions.という表示がでて、メトリクスとやらができあがる。
次にconfフォルダにあるfop.xconfをconfig.xmlという名前でコピーして保存した。フォントとして以下のように登録。
<font metrics-url="/home/username/Applications/fop-0.94/fonts/heisei-mincho.xml"\\ kerning="yes" embed-url="/home/username/.fonts/HeiseiMincho-W3.ttf"> <font-triplet name="heisei-mincho" style="normal" weight="normal"/> </font>ここではfop-0.94はホームディレクトリ下のApplicationsというフォルダに置いている。そして、test.foというファイルを作って、
fop -c /home/username/Applications/fop-0.94/conf/config.xml test.fo -pdf test.pdfとやるとtest.pdfファイルができあがるという寸法である。面倒臭い指示だが、ちゃんとできたのだ。絶対パスで書かないともっと面倒なことになるらしい。とにかくpdfファイルはできるのだ。素晴らしいではないか。問題は縦書きである。私は日本語は縦書きにしなければ気が済まないのである。そこで、次のような試験用ファイルを作った。
<?xml version="1.0" encoding="UTF-8" ?> <fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format" > <fo:layout-master-set> <fo:simple-page-master master-name="PageMaster"> <fo:region-body margin-top="3cm" writing-mode="tb-rl"\\ display-align="center" /> </fo:simple-page-master> </fo:layout-master-set> <fo:page-sequence master-reference="PageMaster"> <fo:flow flow-name="xsl-region-body"> <fo:block font-family="heisei-mincho" font-size="18pt"\\ text-align="center" background-color="aqua"> 日本語の縦書き文書を作成。 </fo:block> </fo:flow> </fo:page-sequence> </fo:root>writing-mode="tb-rl"というとことが、上から下へ、右から左へという文字の流れを指定するはずである。ところが、下の画像のような文字列になってしまうのだ。フォント、大きさ、背景色、配置、そして文字の流れもちゃんと指定通りなのだが、ただ文字が横を向いてしまう。なぜ? なぜなんだ!

2008-06-15 12:46:33
Appleの.macがmobilemeとかいうものに変るらしい。その.mac/mobilemeにiDiskというのがあって、自分のファイルを保存しておいてどこからでも利用できるっていう、そんなに珍しくもないものである。ログインすると、MacOSXのホームディレクトリのように、DocumentsとかMoviesとかSitesというようなフォルダ/ディレクトリが用意されている。共有利用のために、Publicの他にGroupsというのもあらかじめ準備されている。これを私はあまり利用していなかったのだが、もっと利用しようと思い、Linux(ubuntu)からも利用できるように設定してみた。
ubuntuからはwebDavという接続方式で利用する。そこで、davsf2をインストールして設定してみたのだが、確かに接続できてディスクをマウントできる。簡単である。しかし、書き込みができない。いろいろやってみたけれども、Permission deniedという結果になってしまう。ちぇっ、面白くないな。
不愉快な気持で世界を呪っていたら、もっと簡単な接続方法があることが解った。
- メニューの[場所]から[サーバへ接続]を選択
- サービスの種類を WebDAV (HTTP), サーバ名を idisk.mac.com, フォルダ名を アカウント名,ユーザ名をアカウント名にして「接続」をクリック(ポート番号は空欄。入れるなら80)
- 「ブックマークを追加」をチェックして、ブックマーク名をたとえば「iDisk」などと入れる。
- パスワードを求められるので入力
2008-06-06 21:27:08
RSS情報をPythonで処理したくてどうしようかと思い、ElementTreeというのがあるのを見つけて何時間もかけてようやく使い方が少し解ったのだが、自分が2月に一度試みていることをすっかり忘れていて、そのときの記録を見たら結局ほとんどおなじところに辿り着いていた。自分の莫迦さ加減に呆れた瞬間だった。そういう時間の無駄をしないように、これを書いているというのに。情けない。
今日はbk1の新着情報RSSを受け取りたかったのである。結局こんなふうにした。
#!/usr/bin/python
# vim: set fileencoding=utf-8 :
import xml.etree.ElementTree as ET
from urllib import urlopen
url = "http://www.bk1.jp/webap/user/Bk1ExpressRSS.do?keyword=%E5%8F%A4%E6%9B%B8"
root = ET.parse(urlopen(url)).getroot()
items = root.getiterator('item')
for item in items:
print item[0].text
ここでは「古書」というキーワードで引っかかってくる新着図書の情報を受け取っている。今日の新着情報はこんな感じ。
金魚屋古書店 7 白氏六帖事類集 2 影印 大東急記念文庫善本叢刊 別巻1第6巻 影印 延慶本平家物語 第6巻 京都 和菓子手帖 大阪自転車ホリデー 大東急記念文庫善本叢刊 5 影印 和歌 2 朝鮮古書目録 復刻版 古代東アジアの情報伝達 稀本・艶本・珍本解題 第3巻 復刻 日本艶本解題 第2輯 稀本・艶本・珍本解題 第2巻 復刻 日本艶本解題 第1輯 ブックオフと出版業界 新・文學入門 訓點語彙集成 第4卷 し〜そ 王元化著作集 第2卷 思辨隨筆 中国古代の律令と社会 蕭紅研究 佐佐木高行家旧蔵書目録 東アジアの出版と地域文化 子供より古書が大事と思いたい 増補新版 駅舎 現代中国の社会変容と国際関係 中華民国の制度変容と東アジア地域秩序 先秦家族關係史料の新研究 近代中国の中央と地方 白氏六帖事類集 1 影印 EMIKO人形 京都時代MAP 平安京編 日本藝術の創跡 2008 美を拓く者たち ふるほん行脚 吉田富夫先生退休記念中國學論集他にリンク先URLと本の説明が得られる。しかし、著者名と出版者名、価格などの情報が得られないってどういうことか。本のことが解っている人たちが作ったとはとても思えない。これじゃあ使えないじゃないか。
2008-06-01 16:16:42
 mod_pythonのことが書いてある本はなかなかないのだが、先日ようやく見つけたので早速オンライン書店に註文した。Peter Walerowski Python (Open Source Library) (EUR 29,95, Addison-Wesley, November 2007) [Amazon.de,
mod_pythonのことが書いてある本はなかなかないのだが、先日ようやく見つけたので早速オンライン書店に註文した。Peter Walerowski Python (Open Source Library) (EUR 29,95, Addison-Wesley, November 2007) [Amazon.de, 紀伊國屋]である。昨日届いたのでぱらぱらと捲っていたら、python server page (psp)というものが載っていた。PHPのように、あるいはJSPのようにスクリプトが書けるというではないか。早速試してみた。mod_pythonをインストールして、AddHandler mod_python .psp// PythonHandler mod_python.pspとApache2の設定に書き加えればいいだけだと書いてある。しかし、私はすでに、.pyとmod_python.publisherという設定を使っているのだ。両方使うにはどうしたらいいんだ? と思って調べてみたら、解決法があった。
AddHandler mod_python .py .pspと書けば両方使えるらしい。試しに本に書いてあるスクリプトを表示させてみた。
PythonHandler mod_python.publisher | .py
PythonHandler mod_python.psp | .psp
<%
import sys
%>
<html>
<head><title>Info</title></head>
<body>
<table border=1>
<tr>
<td><%= sys.version %></td>
</tr>
<tr>
<td><%= sys.copyright %></td>
</tr>
</table>
</body>
</html>
これをブラウザで見ると、下のような画面が表示された。
おお、これは! 驚いた。
今度はMacOSXで試してみようと、やってみたら、
/Library/Python/2.5/site-packages/mod_python/_psp.so: no matching architecture in universal wrapperというエラーが出てしまって動かない。どうしたらいいんだ! と検索したら解決法があった。しかし、面倒臭いのでまだ解決を試みていない。
最新の日記に戻る