2008-09-30 22:17:19
昨日のRSSの埋め込みは、一旦.jsファイルとして取得データを保存しなくても、いきなりPHPスクリプトの出力を埋め込むこともできる。
$xml = simplexml_load_file("http://www.afp.com/english/rss/stories.xml");
$output = "document.writeln('<h3>AFP News</h3><ul>');\n";
foreach($xml->item as $item){
$dc = $item->children('http://purl.org/dc/elements/1.1/');
$xitem = "document.writeln('<li><a href=\"";
$xitem .= $item->link;
$xitem .= "\" target=\"_blank\">";
$xitem .= $item->title;
$xitem .= "\"<a><br />');\n";
$xitem .= "document.writeln('".$dc->date."</li>');\n";
$output .= $xitem;
}
$output .= "document.writeln('</ul>');\n";
print $output;
file_put_contentsのところをprintにしただけである。
htmlの方では、
<script language="javascript" type="text/javascript" src="rss.php"> </script>
というようにする。ここでは同じディレクトリにphpファイルがあるが、JavaScriptは遠くのファイルも取得できるので、別のサーバ上に置いたものを、src="http://xxx.xxx.xxx/rss.php"というようにして取り込むことも可能。だから、PHPを動かせないサーバでも、PHPを動かせるサーバを経由して情報を取得できる。その都度、情報を取得するので最新情報が表示できる。でも、過剰なトラフィックを発生させかねないのかも。
2008-09-29 21:41:12
JavaScript練習帖
JavaScriptを知っている人にとってはあまりにも当たり前の初歩的なことなんだろうが、何しろ私はJavaScriptだけは避けて生きてきたのだ。PHPとPython、ときにはRubyでなんとかやっていこうと思っていた。でも、どうも気になるので、もうJavaScriptから目を逸らさないことに決めたのだった。ほんの数週間前のことである。
Blog Developer's Cookbookというサイトの記事RSS feed を JavaScript で HTML に埋め込むを読んで、ちょっと真似してみた。何でも最初は真似である。私はいつも真似をして生きてきた。が、そんなことはどうでもいい。この記事では埋め込む.jsファイルをPerlで書いているが、私はPerlは解らないので、PHPで書いた。利用してみたのはAFPニュースのRSSである。
$xml = simplexml_load_file("http://www.afp.com/english/rss/stories.xml");
$output = "document.writeln('<h3>AFP News</h3><ul>');\n";
foreach($xml->item as $item){
$dc = $item->children('http://purl.org/dc/elements/1.1/');
$xitem = "document.writeln('<li><a href=\"";
$xitem .= $item->link;
$xitem .= "\" target=\"_blank\">";
$xitem .= $item->title;
$xitem .= "\"<a><br />');\n";
$xitem .= "document.writeln('".$dc->date."</li>');\n";
$output .= $xitem;
}
$output .= "document.writeln('</ul>');\n";
file_put_contents("afp.js",$output);
これで、AFPのニュースを埋め込み用ファイルafp.jsとして出力している。simplexmlでdc:dateを取得する方法を忘れていて、ちょっと戸惑ってしまった。上の$dcの行。これをcronか何かで、定期的に実行すれば、最新情報がafp.jsに保存される。その都度、情報を取得しに行く必要もないだろうから、これで一日二回とか実行すればいいのではないか。まあ、その都度取得しに行く方法を知らないから、今は何れにせよこれしかできない。これを実行すると、下のようなファイルができる。
document.writeln('<h3>AFP News</h3><ul>');
document.writeln('<li><a href="http://www.afp.com/english/news/stories/newsmlmmd.984ce7304f5b1936ad6df506f5f78f75.771.html" target="_blank">US lawmakers nail deal on Wall Street bailout"<a><br />');
document.writeln('2008-09-28T23:31+00:00</li>');
document.writeln('<li><a href="http://www.afp.com/english/news/stories/newsmlmmd.49a009e41d6df1ad48bec810cd48a5cc.2b1.html" target="_blank">Sudan says six tourist kidnappers killed in shootout"<a><br />');
document.writeln('2008-09-28T21:55+00:00</li>');
document.writeln('<li><a href="http://www.afp.com/english/news/stories/newsmlmmd.300f74a0cfc1d934503e71b3aa5aa8a6.fe1.html" target="_blank">Spate of Baghdad bombings kills 33"<a><br />');
document.writeln('2008-09-28T20:36+00:00</li>');
document.writeln('</ul>');
上には3項しか書いていないが、普通はもっと多くなるだろう。5とか10とか。こうして、できたafp.jsファイルを下のようにして、htmlの中に埋め込む。
<script language="JavaScript" src="./afp.js"></script>
埋め込まれるのはこんな感じになる。

これはすばらしい。私はいつもPHPで埋め込んでいたのだが、それだとPHPを使えるサーバでしか利用できない。これなら、いつでもどこでも埋め込めるじゃないか。でも、w3mとかlynxはJavaScriptを解さないので、読めなくなってしまうらしい。さっき引用元として挙げたサイトには、「Googlebot などの検索エンジンスパイダーも JavaScript を理解しません」と書いてあったけれども、今でもそうなのだろうか。この記事、5年前のもので、ちょっと古びてしまったところもある。
ということは、Googleに捕捉されない秘密のサイトを作れるということなのか。今度、こっそり作ってみようか。
2008-09-28 21:53:36
 遙か南方の海上で颱風が発生するともう私は一日何回も台風情報が気になって仕方がなくなる。いや、颱風になりそうな雲の渦を見つけたときからと云った方がいいかも知れない。その動きを追い続けるわけだ。
遙か南方の海上で颱風が発生するともう私は一日何回も台風情報が気になって仕方がなくなる。いや、颱風になりそうな雲の渦を見つけたときからと云った方がいいかも知れない。その動きを追い続けるわけだ。
もちろん、颱風に直撃されると困る。ベランダに出してある食虫植物や朝顔を家の中に入れなければならないし、万一停電になったりしたら、もう何もできない。冷蔵庫は止まって食べ物や飲み物も腐ってくる。大変である。
中学生か高校生だった頃、颱風で大雨が降って家の周りに水が押し寄せてきたことがある。水門の開閉を間違えたとかで、うまく田の水を川へ排水できずに雨水がどんどん溜まってしまったらしい。そんなことは後になって解ったことで、そのときはただ水位の上昇を見つめるだけだった。
いや、見つめるだけではなく、一回の本の、本棚の下の方にあるものを二階に運んだ。全部はとても運べなかったのだ。床から一メートルくらいまでのものは全部運んだような気がする。結局、床下浸水直前で水は引いたのだが、それでも大変だった。
そういう心配がないときは、部屋の中で豪雨を鑑賞する。私は豪雨を眺めるのが好きだ。稲妻も。夜中でも激しい雷雨に気づくと起き上がって窓際でじっと外を眺める。その圧倒的な迫力をただ眺める。子供の頃の、颱風で学校が休みになるんじゃないかという不純な動機とは全く別のものである。
今日、台湾に上陸した颱風はずいぶん大きいようだ。910hPaだった。伊勢湾颱風とか室戸颱風くらい?
上陸前にくっきり見えていた目は、もう消えてしまった。
『台風学入門』なんて本があることを、今日初めて知った。欲しいなあ。でも、我が家には本を置く余地があまりないのだ。雲の動きとか、天気図の気圧配置を眺めていると、なかなか楽しい。昨日読んだ、恩田陸『きのうの世界』(1700円+税/講談社)[amazon.co.jp, bk1,
楽天,
紀伊國屋書店,
Yahoo! Books]に、激しい雨の場面が繰り返し出てくる。雨は何か不思議なものを連れてくるような気がする。颱風の日に読む本を今から用意しておいた方がいいだろうか。
2008-09-27 20:21:53

7月11日に届いたサラセニアは順調に育っている。最初は左のような姿だった(いや、もう少ししっかりしていたかも)のが、すっかり大きくなってきた。その育ち具合を撮影して自慢したかったのだが、サラセニアは写真を撮りにくいのだ。ハエトリソウと違って、上に長いから写真をほとんど撮ることなく長年生きてきた私には、なかなか難しい被写体なのである。それに、私の関心はその足下、いや植物だから根本か、つまりそれを植えている水苔に向かってしまう今日この頃なのだ。
もう鉢から溢れんばかりに育っている。少し刈り込んでやった方がいいのだろうか。そもそも、水苔は刈り込んだりしていいのだろうか。よく解らない。

上の方は写っていないが、サラセニアも元気に育っている。きっとこれは水苔のおかげだ。きっとそうだ。水苔は、死んだものを使うと、まあ普通は死んだものを使うわけだが、腐ってきたり、表面に暗緑色のどろどろした藻だか何だかがべっとり増えたりするのだ。生きている水苔は腐らない。表面もいつも艶やかな緑色だ。美しい。
2008-09-27 16:02:37
 「R-1 ぐらんぷり 2008」というDVDが届いた。鳥居みゆき目当てである。これには特典映像として、7月20日に開催された「R1リターンズ」での演目が収録されている。これが、8月2日にTV放映されたのだが、なんと途中でぶち切られていたのだった。もちろん、DVDには最後まで収録されている。
「R-1 ぐらんぷり 2008」というDVDが届いた。鳥居みゆき目当てである。これには特典映像として、7月20日に開催された「R1リターンズ」での演目が収録されている。これが、8月2日にTV放映されたのだが、なんと途中でぶち切られていたのだった。もちろん、DVDには最後まで収録されている。
「米の吉田」は何年も前からの持ちネタのようだけど、昨年秋からずっとまさこしかやっていなくて、まさこ人気が安定してから、「蟹」の季節の頃からか、よくライブでやるようになったものである。6月26日に「ゴールデン・ステージ」とかいう番組で初めてまさこ以前の持ちネタが地上波TVで放映され、ファンたちの間で話題になった。「ハッピーマンデー」にも収録されている。

今日は訳あって音声なしで観たので自信はないのだが、今回も「山崎、春のパン祭り」のカードの件はなかったような気がする。その他は省略なしなのではないだろうか。「あなたみたいな人が満足させることができるのかしら。始めちょろちょろ中ぱっぱ、二合が限界のくせにさあ」も入っている。
9月7日に名古屋でやった「こっくりさん」が近々TVで放映されるのではなかったか。東海テレビだけだと思うけど。あ、もう明後日の放送ではないか。他には「試験勉強」とか「背が伸びちゃう」あたりは放送可能では? 「心配性」はどうでしょうか。
2008-09-26 23:06:57
![]() 近頃話題のGoogle ChromeがLinuxでも使えるという記事をいくつか読んだので、これは試してみなければなるまいと思い、Build Instructions (Linux) (Chromium Developer Documentation)を見ながらbuildしてみた。詳細はリンク先を見て試していただくとして、結論からいうと、動かせなかったのである。数時間に及ぶ作業の末の結果である。よく読んだら、As mentioned above, there is no working Chromium-based browser on Linux. The only things you can run right now are a bunch of unittests:と書いてあるじゃないか。何だ、動かないのか。と、同じことを書いている人がいた。何時間もかけて損した。
近頃話題のGoogle ChromeがLinuxでも使えるという記事をいくつか読んだので、これは試してみなければなるまいと思い、Build Instructions (Linux) (Chromium Developer Documentation)を見ながらbuildしてみた。詳細はリンク先を見て試していただくとして、結論からいうと、動かせなかったのである。数時間に及ぶ作業の末の結果である。よく読んだら、As mentioned above, there is no working Chromium-based browser on Linux. The only things you can run right now are a bunch of unittests:と書いてあるじゃないか。何だ、動かないのか。と、同じことを書いている人がいた。何時間もかけて損した。
それだけなら、ここで報告するようなことではないのだが、CrossOver Chromiumというのがあるのだ。Wineの仕組みを使って、Windows版ChromeをLinuxで動かすということらしい。
早速、CrossOver Chromium for Ubuntu and Debian (32 bit)をダウンロードしてインストール。すべて、opt/cxchromium/以下にインストールされる。あっという間である。昨夜の時間は何だったのか。
/opt/cxchromium/bin/chromium
とコマンドを打つか、左上の「アプリケーション・メニュー」からChroniumを選んで起動する。日本語が文字化けしているので、右上のスパナの絵を押してフォント設定をすると表示されるようになる。インストール時にutfには対応していないような警告が出ていたような気がするがもう消えてしまったのでよく解らない。Googleで何か検索しようとしても、日本語の文字は豆腐になって窓に入るので使いにくいこと甚だしい。しかし、それでも検索はできる。

どのサイトでも日本語入力は文字化けするかというとそうでもないようで、日本経済新聞のサイトでは下のように日本語入力ができた。物珍しいので使ってみたけれども、正式版が出るまでは使うことはないでしょうね。

あ、これは二回目以降の起動の時には、前に訪れたサイトが一覧になって表示されるのか。見られたらまずいところを見たあとだとまずいことになるではないか。これが、「Chromeの新機能で引き起こされる悲劇」とはこのことだったのか!
2008-09-26 22:38:41
 生まれて初めてnon-noという雑誌を買った。ページをめくってみたが、若い女性たちがいろんな格好をしている写真があるだけで、私にはどういう意味があるのか全く理解できない。が、そんなことはどうでもいい。私の目当ては鳥居みゆきインタビューなんだから。しかし、そんなものは目次に載っていないじゃないか。たしか、白黒ページで一ページだけだとどこかで読んだことを思い出し、モノクロページをめくってみたら、あった。カラー印刷でない部分はほんの少ししかないのだ、この雑誌は。本当に一ページだけだったので、そこだけ切って本体は捨ててしまった。我が家には本が多すぎるのだ。申し訳ないが、non-noを入れる余地はないのである。
生まれて初めてnon-noという雑誌を買った。ページをめくってみたが、若い女性たちがいろんな格好をしている写真があるだけで、私にはどういう意味があるのか全く理解できない。が、そんなことはどうでもいい。私の目当ては鳥居みゆきインタビューなんだから。しかし、そんなものは目次に載っていないじゃないか。たしか、白黒ページで一ページだけだとどこかで読んだことを思い出し、モノクロページをめくってみたら、あった。カラー印刷でない部分はほんの少ししかないのだ、この雑誌は。本当に一ページだけだったので、そこだけ切って本体は捨ててしまった。我が家には本が多すぎるのだ。申し訳ないが、non-noを入れる余地はないのである。
ちょっと物足りないが、牛乳を飲んで口がウォホーとなった話とか、折り返し地点の話とか、歯がOLになる話とかが載っていなくてよかった。もう何十回も聞きましたから。芸人ではなくて廃人とか、相変わらず訳のわからないことを云っている。この前、「社交辞令でハイタッチ」で云っていた、蝉の一週間のことを話していた。雑誌の内容から、服装の話などがたくさん載っているのかと思ったら、最初の10行くらい。意外に面白いけど、やはり物足りない。
2008-09-26 22:25:55
牛頬肉というと結構高級料理っていう感じがして、確かに場末の街の昼の定食に牛頬肉が出てきたりはしない。私がいつも仕事の帰りによる食料品店はいろいろ珍しい世界の食品が並べられているのだが、ちょっと値段が高い。ちょっとでもないものも多い。特に肉はどうも高い。庶民なんだからもっと庶民的店に行けばいいのだろうが、仕事の帰りで疲れているので、楽な店に入ってしまうのを許していただきたい。そんな高い店の牛肉で一番安いのが頬肉だったのだ。すじ肉が入荷しているときはそっちの方が安いけれども。
今回もGulaschsuppe風。煮詰まって、GulaschとGulaschsuppeの間のようなものになってしまった。キャラウェイは袋に入れてみた。私はあの粒を噛んでしまったときの芳香が好きなのだが、嫌がる人もいるようなので。珍しく写真を撮ったのが、これ。

あまり美味そうじゃないな。私が作るのはほとんど肉と玉葱とトマトを煮込んだものだということに気づく。肉の種類と、香辛料が違うだけ。これは、仕事から疲れて帰ってきてすぐに食事を作る元気がないので煮込み料理ばかり作っていたからである。前日作った料理を暖めて食べて、一息ついてから、おもむろに翌日の夕食を煮込み始めるのである。煮込み料理は失敗が少ないし、何だかそれらしくできあがる。
ところで、グーラッシュの作り方をみていると、ときどきクミンを入れたりするのを見かけることがあるのだが、何だか南アジアか、メキシコの料理みたいになってしまうんじゃないかろうか。
2008-09-25 23:50:07
 eReader形式の電子書籍を買ってしまった。これはLinuxでは読めないのだ。じゃあ、テキストファイルやpdfに変換できないかと思ったが、secure eReader形式ってことで、それはできないのである。コピー&ペーストもできない。Macだったら、クレジットカード番号で認証するから、何台でも複製して読める。Adobe ebook形式だと他のパソコンに持って行くと読めない(初期化前のファイルを持って行って認証すればいいのかな)のに比べると使いやすいのか。しかし、Adobeの方はページ数に制限があるものの、一部なら印刷も可能だから、どちらが寛容かは判断しづらい。
eReader形式の電子書籍を買ってしまった。これはLinuxでは読めないのだ。じゃあ、テキストファイルやpdfに変換できないかと思ったが、secure eReader形式ってことで、それはできないのである。コピー&ペーストもできない。Macだったら、クレジットカード番号で認証するから、何台でも複製して読める。Adobe ebook形式だと他のパソコンに持って行くと読めない(初期化前のファイルを持って行って認証すればいいのかな)のに比べると使いやすいのか。しかし、Adobeの方はページ数に制限があるものの、一部なら印刷も可能だから、どちらが寛容かは判断しづらい。
どうしてもubuntuで読みたいってことで、VNCでMacOSの画面を表示させて読んでみたところ。でも、これでは出張先では読めないな。

Adobeのebookの方で、25ページでいいから印刷してそれをOCR処理して文字認識させればいいかなと思ったら、文字認識に必要な解像度を出力しないようになっているようだ。なんかけちくさいな、Adobeは。
2008-09-24 22:49:06
 Sugar Syncというオンラインバックアップもいいよという記事(見失ってしまったので、もう解らない)を見て、早速使ってみようかと思った。素早く同期を取ってくれるらしい。10GBで一ヶ月2.49ドルなので、手頃な価格ではないか。Dropboxと同時に使ってもいいかなと思ってアプリケーションをダウンロードしようとしたら、Linux用がないじゃないか。これでは使えない。
Sugar Syncというオンラインバックアップもいいよという記事(見失ってしまったので、もう解らない)を見て、早速使ってみようかと思った。素早く同期を取ってくれるらしい。10GBで一ヶ月2.49ドルなので、手頃な価格ではないか。Dropboxと同時に使ってもいいかなと思ってアプリケーションをダウンロードしようとしたら、Linux用がないじゃないか。これでは使えない。
Linux使っている人は人口として割合が小さいだろうが、ネット使用率とか、オンラインバックアップの必要性とかいったら、一番高い人々なんじゃないだろうか。ちぇ。
Dropboxは立派だとつくづく感じた次第である。

っていうのは面白いけど。
2008-09-24 21:36:34
![]() Googleが書籍検索結果や書評をサイトに組み込めるAPIを公開したとITmedia Newsなどで報じられていたので、さっそく試してみた。といっても、リンクを張っただけですが。
Googleが書籍検索結果や書評をサイトに組み込めるAPIを公開したとITmedia Newsなどで報じられていたので、さっそく試してみた。といっても、リンクを張っただけですが。
大きすぎる! でも、使い方はこれでいいんでしょうか。これは、私が好きな作家Jeffrey Fordの作品が載ってゐるアンソロジーです。しかし、利用する機会はあるでしょうか。どんなふうに使おうか、考え中。
2008-09-23 19:11:12
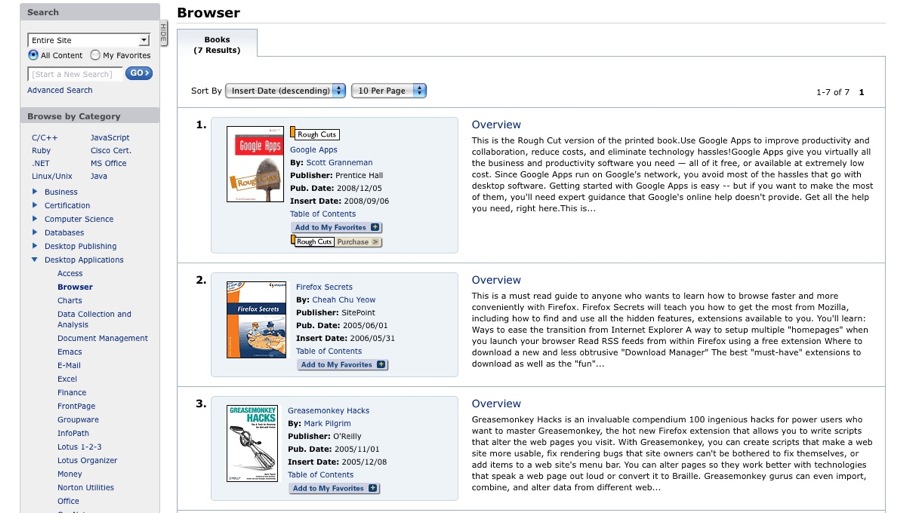
 Safari Books Onlineというのがあって、これは電子書籍をファイルで購入するのではなく、利用料を払って、閲覧するというもの。O'Reilly、Pearson Education、Addison Wesley、John Wileyといった出版社の本が入っていて、毎月80冊程度増えているらしい。現在合計何冊かはどこかで見たけれども忘れてしまった。分野はコンピュータ、IT関係が多い。John Wileyが入っていても、生物系はあまりない。
Safari Books Onlineというのがあって、これは電子書籍をファイルで購入するのではなく、利用料を払って、閲覧するというもの。O'Reilly、Pearson Education、Addison Wesley、John Wileyといった出版社の本が入っていて、毎月80冊程度増えているらしい。現在合計何冊かはどこかで見たけれども忘れてしまった。分野はコンピュータ、IT関係が多い。John Wileyが入っていても、生物系はあまりない。
個人契約には二種類あって、月$42.99(年$472.89)で、閲覧制限なし、月に5点のダウンロード、未刊行のRough Cutsの購読、動画の視聴などができるSafari Professional Libraryと、月に10冊の全文閲覧と月に5章分のダウンロード、Rough Cutsや動画ファイルは見られないという制限のあるSafari Professional Bookshelfというのがある。こちらは月に22.99ドル(年契約では252.99ドル)。私は迷いながらも前者を選択。月に4500円ならいいだろうということで。年払いだと一ヶ月分の割引があるが、今は一度に五万円は厳しい状況なのでやめておいた。
検索すると下のように、検索語がマークされて本などの一覧が表示される。中身を読みたくなったら、クリックすれば読める。この手の本は一ページ目から全部読むことよりも、必要なところだけを読むことの方が多いから、一気に検索してどんどん抜き出して読めるのは素晴らしい。本当にこれ全部読み放題なんだろうか。私が説明を誤解しているんじゃないだろうか。何だか怖くなってくる。もう我が家にある何十冊ものOReillyの本を処分して部屋を軽くしたくなってきた。なかなか本を捨てる勇気はないが。もう高くて重いOReillyの本を買わなくていいのだ。嬉しいではないか。
2008-09-23 13:45:35
 前に書いたように、毎日の食事を作らなくてはならなくなったことがあって、少し作れる料理を増やしたいと思って買ったのが、この本だった。もっと普通の料理にすればいいのに、いきなりロシア料理とは自分でも変だと思うが、欲しかったのだから仕方がない。ところが、買ってみるとロシア料理と書いてあるのに、旧ソ連のロシア以外の国々の料理だった。
前に書いたように、毎日の食事を作らなくてはならなくなったことがあって、少し作れる料理を増やしたいと思って買ったのが、この本だった。もっと普通の料理にすればいいのに、いきなりロシア料理とは自分でも変だと思うが、欲しかったのだから仕方がない。ところが、買ってみるとロシア料理と書いてあるのに、旧ソ連のロシア以外の国々の料理だった。
結局はほとんど作れなかった。唯一参考になったのがグルジアの牛肉とトマトのスープХарчоだけだった。それを今日久し振りに作ってみた。
- 牛もも肉(今日はカレー用というのを使用)150g
- トマト 1個(賽の目切り)
- 玉ねぎ 1個(薄くスライス)
- 大蒜 1片(薄くスライス)
- フェネグリーク(小さじ1程度をお茶葉用の袋に入れて投入)
- チリパウダー(小さじ1/2)
鍋で玉ねぎを炒める。これくらいでいいかなというところになったら、牛肉、トマト、大蒜を加えてさらに炒める。それから、適量の水、フェネグリーク、チリパウダーなどを加えて、20分くらい煮る。
これだけなので、実に簡単である。フェネグリークの独特の芳香がいいのだが、外れのフェネグリークを入手してしまうと間抜けなトマトスープになってしまう。今日も写真を撮ってみた。

ちゃんとした信頼できる調理法が載ってゐるところはどこだろうかと探してみたけれども、よく解らなかった。写真を見て、何だか私のと近そうなのを選んでみた。
・Суп харчо с гранатовым соком
・Харчо из говядины
探すのが面倒臭くなってきたので、これで終はりにする。前に一度羊肉で作ってみたことがあるのだが(グルジアでは羊も使うらしいので)、強烈に臭くて大変なことになってしまった。
あ、米を少し入れることを忘れていた。少量、好みで入れればいい。あまり入れるとグルジア風雑炊のようになってしまうから気をつけた方がいいが、それはそれで美味いかも知れない。
2008-09-23 13:01:40
今年最後の朝顔でしょう、これが。来年はもっと立派に育ててやりたい。株が弱らないようにと、萎れた花はすぐに摘んでいたつもりだったのに、種がいくつもついている。これを来年蒔いたらまた同じような花が咲くのだろうか。桔梗咲きはどうだったかな。次世代も安定だったかどうか、忘れてしまった。
朝顔も終わってもう秋かと思ったら、まだまだ昼間は暑いし、日差しも強い。


写真は実はかなり苦手。手が震えるから。種の時はなかなか震えがとまらなくて、くっきり写らなかった。小学生の頃から手が震える。手が震えない人が羨ましい。
2008-09-23 07:01:41
 この「〜を使ってみた」というタイトルは好きではないのだが、他に上手い言い回しが思いつかなかったので、やむを得まい。今日はGlide OSである。これもCloud Computingで知ったもの。Web-Based Desktopという章にまとめられているのだが、どこがデスクトップなのだろう、そして、××OSという名前が多い(Glide OS、eyeOS、youOS[運営停止])のはなぜだろうと不思議に感じた。
この「〜を使ってみた」というタイトルは好きではないのだが、他に上手い言い回しが思いつかなかったので、やむを得まい。今日はGlide OSである。これもCloud Computingで知ったもの。Web-Based Desktopという章にまとめられているのだが、どこがデスクトップなのだろう、そして、××OSという名前が多い(Glide OS、eyeOS、youOS[運営停止])のはなぜだろうと不思議に感じた。
名前とメールアドレスだけで登録できる。ログインするとブラウザ上にデスクトップという画面が現れる。

Write、Crunch、PresentというMicrosoft Office似のアプリケーションがある。あとはメールソフト(ここでもやはりメールアドレスが貰える)やカレンダー、さらにグループ作業用の場が設定できたりするようだ。Glide HDを選ぶと、ハードディスク管理画面のようなものがでてきて、ファイルを手元のパソコンからアップロードしたり、逆にダウンロードしたりできる。今は10GBまで無料で利用できる。これを見ても最初は何だかよく解らなかったのだが、だんだん「デスクトップ」の意味が解ってきた。OSという名前で何が云いたいのか何となく解ってきた。簡単に云えば「OSみたいに見えるでしょ」ということで、まあ、それは最初からそうだろうとは思っていたのだが、触っているうちに納得できるようになってきたということである。全然説明になっていないけど。
ブラウザのポップアップ抑制機能を有効にしていると全然デスクトップが動かないので要注意である。綺麗なのはいいのだが、不満は遅いこと。綺麗なものは遅いのだ。Appleを見ているとつくづくそう感じる。
ここの特徴は、独立したアプリケーションとしても実行できること。MacOS、Windows、Linux用の3種が用意されていて、ダウンロードしてインストールすれば、WWWブラウザから独立して動かすこともできる。

さらに、これに加えて、表計算ソフトのCrunchは単独のアプリケーションとして、MacOSやWindows、あるいはLinuxで使うこともできる。ほぼ完全にパソコンのOSから独立して(共通の動作環境で)動かせるようになる。だから、Glide OSを名乗る訳かとようやく納得できた次第。といっても、この上で、自分のスクリプトが実行できたりするわけではないので、あまりOSという感じはしない。コマンドラインで実行できるところはないのかな。この並んでいるアイコンの中にTerminalとかいうのがあったら大感激なのだが。ある訳ないか。
2008-09-21 22:16:01
 LinuxでMobileMeを使う方法が見つかりました。最初は、WineでWindows版をインストールしろなんてものしか見つからなくて、それは別に嘘ではないのですが、私の求めている答えじゃありません。
LinuxでMobileMeを使う方法が見つかりました。最初は、WineでWindows版をインストールしろなんてものしか見つからなくて、それは別に嘘ではないのですが、私の求めている答えじゃありません。
でも、こんな記事がありました:HOWTO: Apple's MobileMe on Linux.。FirefoxのUser Agent Switcherというadd-onを使って、身分をWindows版あるいはMac版のFirefoxまたはSafariと偽れということです。こいつをインストールしてFirefoxを再起動するだけですが、最初のブラウザのリストには目的のものは入っていないのです。そこで、ここにあるリストをダウンロードして読み込ませて、Winodws版Firefox 2だと名乗ったら、簡単に受け入れられました。

これで安心して、MobileMeが使えるというものです。よかった。
2008-09-21 21:07:12
この頃、あれこれウェブアプリケーションを探したり、共有ディスクを試したりしているのだが、長年のApple信奉者としては、MobileMeが使へればこんな楽なことはないのだ。でも、あまり使っていない。メールは使っているけれども、これも別のに移していこうかと考えているくらいだ。
共有ディスクが遅いという不満は確かにある。でも、Linuxへのマウントもできるし、なぜかMacOSよりもLinuxからアクセスするときの方が早いような気がする。だから、これはこれでいい。しかし、問題はメールとかカレンダーとか、共有ディスク以外の機能、すなわちウェブ・ブラウザから利用する機能である。腹立たしいことに、Linuxからアクセスできないのだ。こんな表示が冷たく出てくるだけだ。
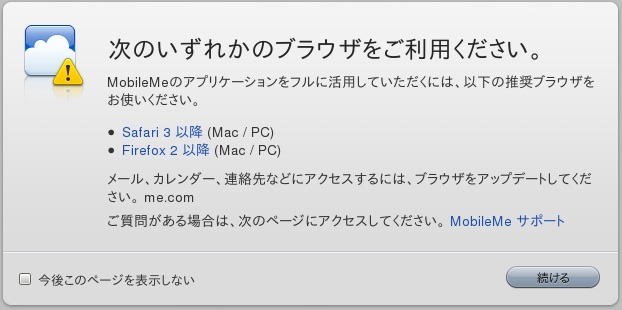
私はこれを見た瞬間、かなりAppleが嫌いになった。こんなに忠実に使い続けてきたのに、裏切られたような感じがする。Linuxを使うというところがすでに忠実でないのかも知れないが、こういう仕打ちを受けると、「ubuntuは裏切らない」と云ってしまいそうになる。でも、年間9800円も払っているのだ。まだ、20GBのうち、200MBしか使っていないのだ。何とかうまい利用法を考えたい。
2008-09-21 15:43:47
 昨日届いたCloud Computingに出ていたZohoを早速試してみた。Google Docsみたいに、文書作成(ワープロ)、表計算ソフト、スライド作成があるようだが、もっとたくさんの機能があるらしい。ほとんどが無料で使えることには驚かされる。気になったのは、Zoho CreatorというオンラインデータベースアプリケーションとZoho DB & Reports。最初はDB & ReportsのデータをAoho APIで操作して、Zoho Creatorで使えるのかと思ったのだが、どうやら違うようだ。まだよく解っていないのだが、別のサイトに埋め込んだり、いろいろ操作できるという。
昨日届いたCloud Computingに出ていたZohoを早速試してみた。Google Docsみたいに、文書作成(ワープロ)、表計算ソフト、スライド作成があるようだが、もっとたくさんの機能があるらしい。ほとんどが無料で使えることには驚かされる。気になったのは、Zoho CreatorというオンラインデータベースアプリケーションとZoho DB & Reports。最初はDB & ReportsのデータをAoho APIで操作して、Zoho Creatorで使えるのかと思ったのだが、どうやら違うようだ。まだよく解っていないのだが、別のサイトに埋め込んだり、いろいろ操作できるという。
Zoho Mailの料金欄を見たら、「現在サービスの再構築中のため受付を一時停止しております」と書いてあったので、それなら知らないうちにメールアドレスを作ってしまったりはしないなと安心していたのに、気がついたら作ってしまっていた。どういうことだ。申し込みの途中で、Google Gearsの設定の有無の確認があって、あると解るとオフライン設定しますかと問われる。
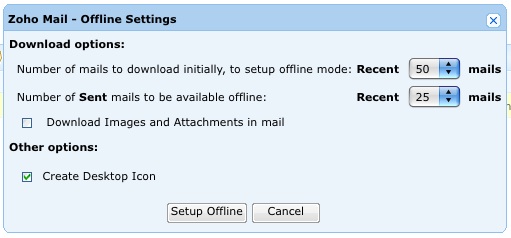
ここでデスクトップアイコンも作ってくれよというと、じゃあショートカット作ってもいい? と確認される。
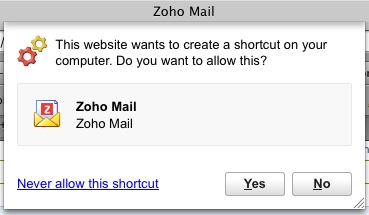
ものは試しにと、いいよと返事をしたら、デスクトップにZoho Mailなんてアイコンができてしまった。新しいメールアドレスなんて使うつもりもないのに! すでに五つも六つもアドレスがあって無駄に管理しなければならないのに。

オンラインプレゼンテーションZoho Showの使い勝手はどうだろう。208 Slidesと比べてどうだろうか。少なくとも日本語の入力は問題ないようだ。いくらMacOSのKeynoteのように使えるとはいっても、日本語が直接入力できないのは不便だから、今度は試しにこれを使ってみようか。
機能が多すぎて、なかなか全体は把握できない。が、そこが楽しそうだと思うのは私だけではないだろう。


2008-09-21 13:05:00
この頃、水苔にばかり愛情を注いだせいか、よく育った水苔がハエトリソウを飲み込みそうな勢いである。写真左の小さい方の株はもうその存在を確認することすら困難だ(ちょっと大袈裟)。そこで、少し水苔を切ってやった。切り取った緑の水苔は、プランターの方の茶色の領域に植え付けた。そうすればまた伸びるらしいのだが、どうだろう。切り取ったあともそんなに変わり映えはしないので、写真は撮っていない。

皆さんの水苔は元気ですか。
2008-09-20 22:49:06
 死ぬほど辛いというDeath Sauceというものを娘が買ってきた。辛いものに合うのはこれだと思って作ったのが、chiliconcarneである。chili con carneと書くことも多い。チリビーンズとも。
死ぬほど辛いというDeath Sauceというものを娘が買ってきた。辛いものに合うのはこれだと思って作ったのが、chiliconcarneである。chili con carneと書くことも多い。チリビーンズとも。
レッドキドニービーンズ(Red kidney beans)を一握り(何かも適量で済ませる私である)水に浸けて一晩おく。数時間でいいと思うが、今回は寝る前に思いついたので。翌朝、豆を煮る。挽肉(適量)、刻んだ玉ねぎ(一個)、刻んだセロリ(適量)を炒めて頃合いを見計らって豆を煮た鍋に入れる。トマトの缶詰を一缶加え、固形スープの素を一個入れ、しばらく煮る。チリパウダー、クミン(粉末でも種でも。あるいは両方でも。今回は両方)、トマトはいつもは一缶使わないのだが、今回は面倒臭くて全部入れたら、多すぎた。大蒜は本当は欠かせないと思うものの、冷蔵庫に入っていないことに気づいたとには遅かった。ベーコンを入れることもあるが、冷蔵庫に入っていなかった。
普段は赤唐辛子を刻んで入れるのだが、今日はあとでDeath Sauceを入れるので赤唐辛子は入れない。それでも、チリパウダーが辛いので、まったく辛くないわけではない。
しばらく煮込んだら完成。今日は珍しく写真を撮ったので載せておこう。しかし、自分で撮った写真を見ると全然うまくなさそうだな。これはDeath Sauceを入れる前の状態。

これにDeath Sauceを適量(この加減が難しい)加えて、食べると、口の中から火が吹き出すんじゃないかと思うような辛さが舌を、そして喉を直撃。でも、食べ終えると、もう少し入れてもよかったかも知れないと思ってしまうのが不思議である。辛いものを食べると、CoCo壱番屋の10辛カレーを食べて、思考回路がショート寸前と云ったのは鳥居みゆきを思い出すのだが、今日のはそんなに辛くないので唾液が噴出したりはしなかった。
2008-09-20 22:11:08

まだ数日しか使っていないのだけど、今朝ふと気づくとDropboxが同期されなくなっていた。同期中という印が表示されるのだけど、いつまで経ってもできない。中身を見ることもできない。どうなっているんだ。

結局、私が勘違いして全てのフォルダとファイルの実行権を剥奪してしまったからだった。ファイルの方は問題ないのだが、フォルダの方がいけなかった。いや、そもそもここをどうにかしようと思っていたわけではなかったのだが。
それはもう解決したからいいのだが、Dropboxの中身が使えなくなったときの、自分の衝撃に驚いた。もう仕事ができない! と狼狽えてしまった。ほんとうは、wwwブラウザからファイルはダウンロードできるから、仕事はできたのだ。でも、全部ダウンロードするなんて時間の無駄だし、今後も使えなかったどうしようかと、本当に目の前が真っ暗になった気分だった。ほんの数日でここまで手放せない存在になっていたとは。ここまで依存するようになっていたとは。恐ろしい。Dropboxは恐ろしい。気がつくとすっかり虜になっているのだ。ほんの数日で13.5%の使用率になったから、近いうちに有料の50GB版に移行しそうだと、ちょっと喜びながらそのときを待っている自分に気づいてまた怖くなった。
ところで、Dropboxを使ってScrapbookのデータを共有しようという作戦はいろいろな人が思いつくことのようだ。私はMacの共有がうまくいかなかったのだが、うまくいっている人がいるようじゃないか[人生迷い箸]。どうしてこの人にできて、私にはできないんだ。どうしてうちのMacではできないんだ。
2008-09-19 23:11:07
一昨日のLinux Tipsに掲載された「キーボード操作でプログラムを起動するには」をみて、GONOME doを使ってみたくなった。MacOSXでは、ABCLaunchを愛用しているので、Linuxで似たようなのがあると知って早速試してみた。私はマウスが嫌いなのだ。だからトラックボールを使っているが、できればキーボードでなるべく済ませたい。マウスは指や腕が痛くなる。あるとき、あまりにも痛みが激しくなって、それ以来マウスやトラックボールは左手で使っている。そのせいで、ときどき「あれ、左利きでした?」と云われるのだが、普段は右利きである。一時期足でトラックボールを扱おうと頑張ったことだってあるのだ。が、その話は恥ずかしいので、今日はしない。
私はUbuntu 8.04なので、Synapticでインストール。簡単である。左上の「アプリケーション」というプルダウンメニューの中の「アクセサリ」にGNOME doという項目ができるので、これで起動させた。この後は、「Windows」+「Space」キーで選択画面が出てくるはずなのに、出てこない。そこで、やはりLinux Tipsに書いてあるようにして、「Tab」+「Space」に変更してみた。すると、文字入力時にスペースキーを押すたびに、GNOME do画面が出てきて、スペースが入力できないのだ。これは困る。何もできないではないか。仕方がないので、「super」+「space」に戻したら、どういうわけか「Windows」+「Space」キーで出てくるようになった。全く理解できないが、これで目的は達せられたのでいいことにしよう。

説明を読むと、右上の三角を押すと「Preference」という項目を選べると書いてあるのだが、そんなものは出てこない。どうなっているのか。まあ、いいや。細かいことは気にしない性格である。
ここに紹介するためにスクリーンショットを撮ろうと思ったのだが、GNOME doは他の操作をすると選択窓が消えてしまうので、スクリーンショットを撮れなかった。みんなどうやって撮っているんだろう。
2008-09-17 22:51:43
 Firefox 3 Hacksで知ったScrapBookはなかなか便利。全文検索が好きな私も満足できる検索機能もついている。この本で紹介されているScrapBox.netというアドオン機能を使うと、別のPCに転送して共有できるという。これは是非使わなくてはと思い、ScrapBook アドオン機能を見たら、この機能は今は使えなくなっているではないか。そこで、昨日見つけて大感激したDropboxを使って共有化することにした。自分が頭がいいのではないかと勘違いしてしまうのはこんなときである。
Firefox 3 Hacksで知ったScrapBookはなかなか便利。全文検索が好きな私も満足できる検索機能もついている。この本で紹介されているScrapBox.netというアドオン機能を使うと、別のPCに転送して共有できるという。これは是非使わなくてはと思い、ScrapBook アドオン機能を見たら、この機能は今は使えなくなっているではないか。そこで、昨日見つけて大感激したDropboxを使って共有化することにした。自分が頭がいいのではないかと勘違いしてしまうのはこんなときである。
ScrapBookのデータ保存先は初期設定でFirefoxのプロファイルフォルダ内のScrapBookフォルダとなっている。そこで、Dropboxに.ScrapBookというフォルダを作って(普段は見える必要がないと思って、「.」で始まる名前にしてみた)。それから、ScrapBookの設定画面で下のように、Dropboxにあるフォルダをデータ保存先として指定した。これで、Dropboxを設定しているところではデータ保存先が同期されるはず。
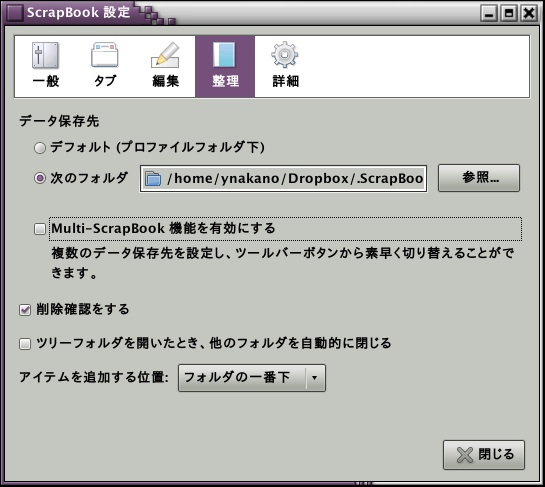
と思ったら、MacOSXのFirefoxの方で、「.」で始まる名前を選べなかった。見えなくても、パスを打ち込めばいいだろうと思っていたのだが、文字を入力できないのだ(Linux版でもそうだったと後で解った)。どういうことだ。あきらめて、ただの「ScrapBook」というフォルダ名に変更。これでいいだろうと思ったら、MacOSXの方ではScrapBookのデータ保存先が変更できなかった。一見、設定は変わっているようなのだが、初期設定の情報しか見に行かないし、保存も初期設定の場所にしか入らない。どういうことなんだ。共有計画は失敗である。Dropboxに複数のScrapBookフォルダを作って、ときおり取り込んだり書き出したりすればいいのだが、同じファイルがいくつもできて無駄である。なかなか思うようにはいかない。
でも、Linux同士ではこの方法で共有化できたような気がする。結局、Linux2台はのScrapBookフォルダは不可視フォルダで共有するということで落ち着きそう。Mac版は職場でも自宅でも保存先の変更が機能しなかった。ああ、時間を損した。2時間くらい悩んであれこれ試してみたのだった。
2008-09-17 22:04:59
![]() GoogleがGoogle Audio Indexingで、動画内の音声のテキスト検索を始めた。今は主に大統領候補の演説がテキスト化されているらしい。これは人が演説を聴き取ってタイプ打ちしていたりするのではなく、音声認識技術を使ってテキスト化しているという。話し言葉のデータベースがこれからすさまじい勢いで増えていくということだろうか。検索してみると動画内の音声に検索語が出現した箇所が数語と共に表示される。どんな文脈で使用されるとか、どんな用法で使われるとかいう集計もできるようになるかも知れない。私は話し言葉よりも書き言葉が好きなので、そんなに用例検索には使わないと思うけれども。でも、誰がどんなことを言っているのか調べるのには優れていると思う。
[ITmedia, MarkeZine]
GoogleがGoogle Audio Indexingで、動画内の音声のテキスト検索を始めた。今は主に大統領候補の演説がテキスト化されているらしい。これは人が演説を聴き取ってタイプ打ちしていたりするのではなく、音声認識技術を使ってテキスト化しているという。話し言葉のデータベースがこれからすさまじい勢いで増えていくということだろうか。検索してみると動画内の音声に検索語が出現した箇所が数語と共に表示される。どんな文脈で使用されるとか、どんな用法で使われるとかいう集計もできるようになるかも知れない。私は話し言葉よりも書き言葉が好きなので、そんなに用例検索には使わないと思うけれども。でも、誰がどんなことを言っているのか調べるのには優れていると思う。
[ITmedia, MarkeZine]
Google App Engine SDK 1.1.3が発表された [Google App Engine Blog]。ローカルでのデータ登録がしやすくなったとか。あまりよく解らないけど。[CodeZine]
2008-09-16 23:53:53
前にも書いたように牛頬肉の赤ワイン煮には飽き飽きである。うまいのだけど、飽き飽きである。食べさせてもらっているときには、こんなことを云ったら作ってくれた人に失礼だが、自分で作っているのだから、云ってもいいのだ。もちろん、私が作った牛頬肉の赤ワイン煮を食べてそう云われたら腹が立つ。呪ってやる! 食べるのは今のところ娘か妻なので呪わないけど。
ということで、今日はGulaschsuppe風にしよう。グーラッシュという料理があって、オーストリアとか南ドイツでよく作られる食べ物と私は思い込んでいるが、本当のところはよく知らない。元は、ハンガリー料理のグヤーシュらしい。
普通は頬肉は使わない。が、私は頬肉である。300g程度の牛頬肉を適当な大きさに切って、表面を焼く。それから、よく煮る。ワインを少し入れたりしながら。3〜5時間くらい経ったら、玉ねぎ一個、トマト一個(缶詰でも可。なぜか生よりも缶詰の方が安かったりするので、この頃は缶詰を利用することが多い)を適当な大きさに切って鍋に入れる。固形スープの素を一個入れると味の調整が簡単である。キャラウェイ、マジョラムを適量入れる。私はキャラウェイを多目に入れたいのだが、娘はちょっと嫌がる。まあ、各人の好みで。全然入れないとグーラッシュではなくなってしまうと思う。あとパプリカも適量投入。何もかも適量である。
玉ねぎが柔らかくなったら、これまた適当な大きさに切ったじゃがいも一個分を入れて、芋に日が通るまで煮込む。こんないい加減な作り方でも、それなりの味になるのが、煮込み料理のいいところである。
こんないい加減な作り方では何の訳にもたたないとお怒りの方には、私が参考にしたサイトにリンクを張っておく。ここにはちゃんと分量が書いてある。
相変わらず写真はない。私のに似た写真が載ってゐるサイトを紹介しておこう。
・Rezept Gulaschsuppe
・Ungarische Gulaschsuppeキャラウェイが入っていない! ハンガリー風だから?
・Gulaschsuppe - essen & trinkenこれは出来合いのスープを使っているのか。そんなのありか!
2008-09-16 23:14:57
こんなニュースが報じられた訳なのだが[InternetWatch]、私はGoogle Gearsというものが今ひとつよく解っていない……というのは大嘘で、今ひとつどころか全然解っていないのだ。「Webアプリケーションをオフラインの状態でも使えるようにする」なんて云われてもよく解らないのだ。Official Google Mac Blogの当該記事を読んでもやはり解らない。
あまりにもよく解らないので、とりあえず二日前に白石俊平『Google Gearsスタートガイド』(1980円+税/技術評論社)[amazon.co.jp, bk1,
楽天,
紀伊國屋書店,
Yahoo! Books]を註文した。数日中には届くはずだ。JavaScriptを使っているというので、JavaScript: The Missing Manual (O'Reilly, 7/2008) [Amazon.co.jp, Amazon.com,
紀伊國屋]を買った。pdf版なので、もう手元にある(でもまだ読んでいない)。使えるようになるだろうか。せめて、どういう意味なのか、われわれに何をもたらすものなのかくらいは解るようになりたい。
2008-09-15 14:04:59
ここ数日Dropboxが一般公開されたという記事をあちこちで見かける[@IT, ITmedia]。今までは初期のGmailのように新規申し込みが招待制になっていたらしい。それが三日ほど前に誰でも申し込めるようになったという。さっそく、登録してみた。
サイトを訪れるといきなりダウンロードっていうボタンがあるので、それをクリック。何でアクセスしているのか解っているので、MacOSXならMacOSX用、LinuxならLinux用のダウンロードへと進むようになっている。Macではアプリケーションフォルダにダウンロードしたものを入れて、ダブルクリックで立ち上げる。登録します? とか促されるので、ここは当然登録して使ってみるために導入したのだから、登録する。入力項目は名前とユーザIDとパスワードくらいである。設定が終わると画面上のメニューバーにDropboxのアイコンが出現する。ホームディレクトリ上にフォルダもできる。次回からはログインと同時に勝手に配置されるらしい。Linuxでは、Fedora9用、Ubuntu 7.10用、Ubuntu 8.10用などが予め用意されている。Sourceもあるので、他の環境でも使えるのだろうが、私はUbuntu 8.10なので、これで導入。MacOSXとほとんど同じでホームディレクトリ上にフォルダができて、上のバーにDropboxのアイコンが追加される。Nautilusを使っている人は、インストール後に$killall nautilusを実行するのを忘れないように。
こんな具合にフォルダができて、これが勝手にサーバ上のフォルダと同期される。でも、同期ってことは、同じ容量のフォルダがローカル環境にもできるってことなのか。オフラインでも作業できて、オンラインになった瞬間に勝手に同期されるのがいいらしいのだが、手元にファイルを置きたくないときはどうするんだろう。ディスク容量が僅かしかない小型ノートの場合とか。
それでも、MacとLinuxでほとんど同じように共有・保存・同期ができるのは嬉しい。Linux版ってなかなかないのである。Linux使う人は自分でオンライン同期くらいするでしょうって感じで。だから、万人に普及しないのだろう。
あと、うっかり消してしまったファイルの復活機能もある。
2GBまでは無料。年およそ100ドルで50GBにできるという。とりあえず、2GBで使ってみよう。
2008-09-15 10:37:26
確か7月にもMacBook Touchが出るという噂が流れていたような気がする。その前のときはMacBook Airが出る前だったか。もうよく覚えていない。数日前から再びまことしやかに囁かれている噂がある。多分、今月10日のDaring Fireball (John Gruber)の記事に端を発したものだと思う。その日のうちにELECTRON4CSに載っていたけれども、10月14日にLLet's MacBookという催しが開かれてMacBook Touchのようなものが発表されるという噂があると書いているだけで、情報源については記されていない(ように見える。私の見落としかも知れない)。
日本では、昨日のGizmode Japanに載っていた。これだけ噂ばかり聞かされてきたから、もう何も信じられなくなっているのだけど、どうなのだろう。9インチあたりの小型ノートパソコンが売れているから、歓迎されるんじゃないかと思うけれども、美しい高級小型ノートだったら私には買えない。そうでなくても、私はDellのubuntu版9インチノートを注文したばかりだ。とても買えない。だから、出なくていいんですよ、私はね。
2008-09-15 08:01:29
昨日280 Slidesの話を書いたときにブラウザの全画面(fullscreen)モードに工夫が必要なんて書いたのだが、MacOSX以外の人には何を云ってゐるんだといふ感じだったのかも知れない。確かに、ubuntu上のFirefox 3ではF11を押したら全画面モードになって、一瞬にしてスライド映写画面のようになった。
MacOSXでF11を押しても、アプリケーションのウィンドウが上下左右にさっと退くだけで、どうにもならない。Firefoxが駄目ならMacにはSafariがあると思ったのだが、Safariにも全画面モードは見つけられなかった。でも、Opera 9.5に全画面モードがあった。
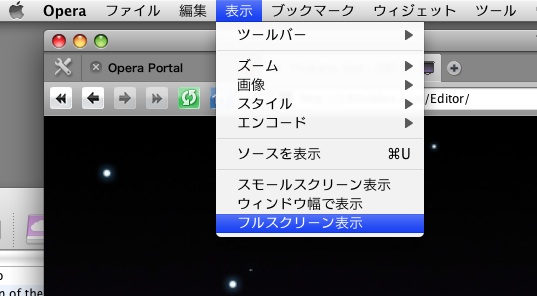
Operaはなかなかいいのだ。前にSafariやFirefoxでキリル文字やハングルの入力で困ったときに、Operaには助けてもらった。もっと普及してもいいのに。といいながら、私もあまり使っていない。
MacOS専用のiCabでは、「キオスクモード」というのがあって、それでもフルスクリーンに近い状態が得られる。メニューバーは残るけど。
ということで、LinuxでもMacOSXでも280 Slidesで作ったものをそのままスライド映写できそうで安心した。Windowsは使わないので知らない。
2008-09-14 15:28:30
本のことばかり書いているもう一つの日記の方に、水苔のことをちょっと書いたら、Googleで「生きている水苔」と検索してみると、かなり上位に出てきてしまったりする。ほとんど水苔のことなんか書いていないのに。こちらは写真も載せて、食虫植物のときと、生水苔だけのときと、それなりに生きている水苔について愛を込めて語っているのに、全然検索に引っかかってこない。たしかにあっちは10年以上書いている。でも、何か悔しいというか、釈然としない。これが、SEOってことですか。ネット社会はおっかないなあ。
生きている水苔は接近して撮ってもなかなか綺麗である。これだけ見せられると何だか一瞬解らないのだけど、紛う方なき水苔なのだ。

2008-09-14 13:16:35
Firefox 3 Hacks(O'Reilly, 2008/8/27)という本が昨日届いてぱらぱらと捲っていたのだけど、何だか難しい話ばかりじゃないかと感じて本を閉じそうになったときに、ふと目にとまったのが280 Slidesに関する記事だった。早速サイトを訪れて、試用してみた。簡単にいうと、オンラインでPowerPointやKeynoteのようなプレゼンテーション材料を作成できるサイトである。所謂スライドいうやつだ。だから、サイト名も280Slidesというのだろうが、280が何かは知らない。
使用感はPowerPointよりもKeynoteに近い。AppleのKeynoteを使っている人は少ないだろうけれども、私はPowerPointよりも100倍くらい使いやすいし、出来映えは256倍くらい綺麗だと思っている。MacOSXでしか使えないけど。
とにかく、簡単にスライドが作れる。ファイルは向う側(サーバ)に保存する仕組みになっていて、インターネットに接続できれば、いつでもどこからでも作業ができる(逆に言えばインターネットに接続できないとなにもできない)。
下のようなアイコンがあって、ファイルを保存したり、開いたり、図を描いたり、文字を書き込んだり、まあ普通のスライド作成作業は簡単にできる。できあがったものをPowerPoint形式やpdf形式で出力することも可能。残念ながらKeynote形式なんてものはない。当然だけど。
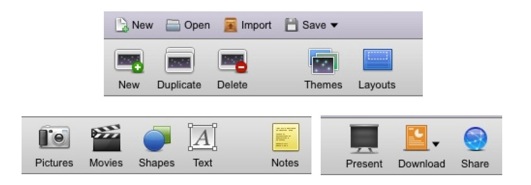
残念なのは少なくとも私の環境では日本語入力ができなかったこと。日本語仮名漢字変換が有効にならないのだ。が、別のところで作った日本語文をコピー&ペーストなら可能だった。その後の文字化けもない。下のは5秒くらいで作ったもの。

一方、Google Docsにも文書や表計算だけでなく、Presentationというのも作成できる。こちらは日本語も画面上で入力できるのだけど、何だか使いにくい。どう操作したらいいかよくわからないのだ。下のようなもの一枚作るのに何分もかかってしまった。私の要領が悪いだけなんだろうが。こちらもサーバにファイルを保存して、いつでもどこでも編集が可能。スライド表示モードがあるから、全画面表示にして発表にもそのまま使える(かも知れない)。

Firefoxの本で見つけたものだけど、MacのSafariでも使用できる。全画面表示での発表時には、メニューなどまで完全に見えなくするための工夫をするといいと思う。いろいろあるらしいが、実はよく知らない。
この頃、こういうサーバ側にファイルを保存して仕事をできるようにしようとしているのは、もちろん、ファイル保存容量の小さい小型ノートパソコンを買ったりしたからである。そんなに出張なんてないのだけど。
2008-09-13 22:09:15
生水苔に対する思いは三日前に書いた通りだ。オンラインショップで生きている水苔を見つけたのは7月のこと。日本花卉ガーデンセンターから購入した。これが新聞紙を広げたのと同じくらいの面積があって、食虫植物を育てるのに使うのは、小さな鉢二つ分である。あとは余ってしまう。そこで、何にも使われずに放置されているプランターに放り込んで水をかけておいた。暗闇で作業したので、あまりきちんと緑の部分が上に揃えられなかった。
それでも数日するとそれなりに安定してきたようだった。そのときに撮った写真がこれ。

朝晩一日二回水をかけてやって、20日後の姿を撮影したのが下の写真。緑の部分が増えている。

さらに20日後の9月13日の写真がこれ。緑の部分が増えると同時にかなり盛り上がってきた。水苔ってこんなに増えるのか。もっと早く手に入れたかった。

食虫植物や朝顔の愛好家のホームページは多くて、写真が満載されていることが多い。緑の水苔にもたくさん愛好家がいるのかと思ったら、ほとんどいない。数少ない例の一つが「ミズゴケの再生・栽培」。この人も食虫植物を育てている人のようだ。やはり食虫植物には生きた水苔である。
2008-09-13 18:21:59
昨日はubuntu 8.04にRPy2をインストールしたので、今日はMacOSX(PowerMac G5/MacOSX 10.5.4)にインストールしてみよう。これで自宅でも仕事ができる。
まずRの現時点でも最新版2.7.2を以下の条件でコンパイルする。
./configure --with-blas='-framework vecLib' \\ --with-lapack \\ --with-aqua \\ --enable-R-framework \\ --with-tcl-config=/System/Library/Frameworks/Tcl.framework/tclConfig.sh \\ --with-tk-config=/System/Library/Frameworks/Tk.framework/tkConfig.sh \\ --enable-R-shlibすると、
configure: error: --with-x=yes (default) and X11 headers/libs are not available
というエラーが出てしまった。何なんだ。何となく、/usr/X11/binのPATHを通したら、エラーは消えた(.bash_profileに追加した)。あとは、make, sudo make installで完了。
次にsudo python setup.py installで終わりだと思ったら、
Exception: "/Library/Frameworks/R.framework/Resources/bin/R" CMD config LAPACK_LIBS
returned
などというエラーが出て、これは解決できなかったので諦めた。諦めるのは早いのだ。そこで、1.0.3をインストール。sudo python setup.py installですんなり完了。2.3 Small examplの例をやってみた。こんな例:
>>> from rpy import *
>>>
>>> degrees = 4
>>> grid = r.seq(0, 10, length=100)
>>> values = [r.dchisq(x, degrees) for x in grid]
>>> r.par(ann=0)
>>> r.plot(grid, values, type='lines')
すると、下のような図が描けた。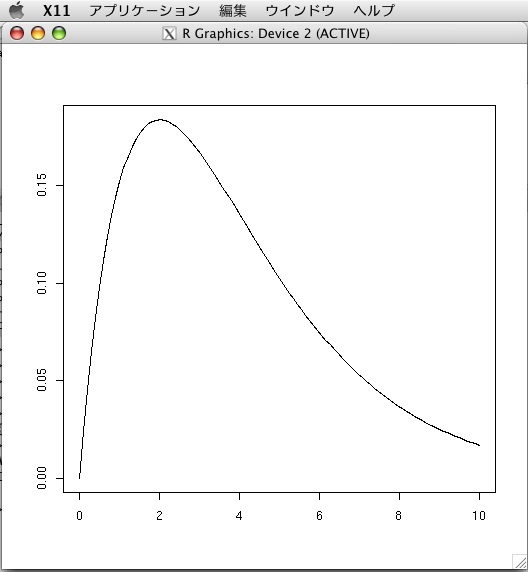
ついでに、iPythonもインストールした。
python setup.py build sudo python setup.py installこれだけ。
2008-09-12 23:54:36
tenki.jpのサイト構成が今月から変はって前よりも解りづらくなったような気がする。でも、雲の衛星写真や天気図に「ブログに紹介する」というリンク作成ボタンがあるので、使ってみたくなった。下に示したのがそれである。それにしても今年の夏の天気図は何とも奇妙ではないか。今日のは颱風なんかがあって夏っぽいけれども、大きく東から張り出している太平洋高気圧の姿が見えなくて、日本の夏らしくない。
これは、この日記を書いているときの天気図ではなく、今この日記を読んでゐるときの天気図なのかな。では、この颱風の美しい等圧線の曲線を載せておきたいというようなときには使えないのか。じゃあ、使い方を間違えているのか、私は。(追記:この天気図は常に9月12日18:00のものが表示される。)
天気図というのが子供の頃から好きで、どうしても天気図が書きたくなったことがあって、まだ三省堂書店の本店が二階建てだった頃に、あまり客のいない二階で天気図の書き方の本と天気図用紙(ラジオ用天気図用紙—地上天気図[No.1]、[No.2])を買ったことがあった。ラジオで気象通報を聞きながら何回か描いてみたけれども、自分で描くとなかなか大変なので数回描いてみてやめてしまった。昔から飽きっぽい性格だったのだ。ラジオの気象通報ももう随分聞いていないが、今でも一日三回やっているらしい。「天気図を描こう」なんていうブログもあるんですね。久しぶりに気象通報を聞きながら、天気図を描きたくなってきた。多分、描かないけど。
2008-09-12 23:16:59
PythonからRを使うために、RPy - 2.0.0a3をインストールした。いきなり、Rがlibraryとしてインストールされていないとかいうエラーが出てしまったので、
./configure --enable-R-shlibとやって再インストール。 そして再び、
sudo python setup.py installとインストール。Drkcore「macbookでRpyを利用できるようにしたのでメモ」を参考にして。Macじゃないけど。
が、import rpy2.robjects as robjectsのところで、
Error in dyn.load(file, DLLpath = DLLpath, ...) : 共有ライブラリ '/usr/local/lib/R/library/methods/libs/methods.so'\\ を読み込めませんというエラーが出てしまう。そこで、/etc/ld.so.confに、
/usr/local/lib/R/libを追加して、再度、RとRPy2をコンパイル&インストールすると、成功。
RPy2サイト Documentにある一番最初の例:
import rpy2.robjects as robjects
import array
r = robjects.r
x = array.array('i', range(10))
y = r.rnorm(10)
r.X11()
r.layout(r.matrix(array.array('i', [1,2,3,2]), nrow=2, ncol=2))
r.plot(r.runif(10), y, xlab="runif", ylab="foo/bar", col="red")
kwargs = {'ylab':"foo/bar", 'type':"b", 'col':"blue", 'log':"x"}
r.plot(x, y, **kwargs)
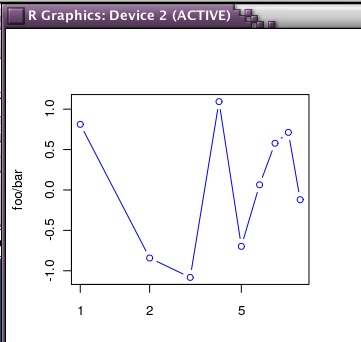
を試してみると、こんな絵が描けた。これでいいということなんだろうか。
2008-09-11 22:34:25
 註文してしまった、Dell™ Inspiron Mini 9 ベーシックパッケージを。OSが使い慣れているUbuntu 8.04だということと、直販だとUSキー配列が選べること。メモリを1GBにして、送料と税金がかかって、54,705円となった。
註文してしまった、Dell™ Inspiron Mini 9 ベーシックパッケージを。OSが使い慣れているUbuntu 8.04だということと、直販だとUSキー配列が選べること。メモリを1GBにして、送料と税金がかかって、54,705円となった。
そんな金あるのか。ある訳がない。どうすればいいんだ。
Ubuntu版の製造は今月後半からだといふから、出荷は月末か来月といふことだらうか。ハードディスクが4GBしかないので、いろいろ溜め込むことはできない。極力ファイルはネット上あるいはネットを介して自宅サーバに保存しよう。DVDドライブがないので、DVDで映画を観たりすることはできない。あまりパソコン画面で映画を観たいとは思はないので、私には関係ないのだが。
これで一体私に何ができるのだろう。いつでもどこでもオンライン書店にアクセスして本が買えるということなんだろうか。そんな金はないというのに。
2008-09-11 22:00:12
家庭の事情で二年半ほど朝晩の食事と娘の弁当を作らなくてはならなくなった時期があった。今はもう毎日の食事の準備を免れてゐるが、最初は料理などほどんとしたことがなかったので、どうしようかと思った。そんなに悩んだ訳でもないけれども、ちょっと戸惑った。自分だけならどうとでもなると思ったが、中学生の娘がゐたから、あまりひどい食事を続けるわけにもいかない。魚が嫌ひだといふことと、仕事から帰ってきてから食事を作る時間がほとんどないといふことから、肉を煮込むことにした。翌日の夕食を前の日の夜に作るのである。
よく作ったのが牛頬肉の赤ワイン煮。料理をほとんどしたことのない者でも、長時間煮込んでゐればそれなりのものができあがるので安心なのだが、どうも納得できる味でなかった。その後、毎日の食事を作らなくていいやうになってもときどき作ってゐて、やうやく思ふやうな味になった。何か酸っぱいやうな味が混ざってくるのがやうやくなくなったのである。
牛頬肉を300グラムくらゐ適当な大きさに切って、鍋に入れて表面を焼く。小麦粉を付けるとかいふ人もゐるけれども、付けても付けなくてもあまり変はらなかったやうな気がする。私はこの頃バターで焼いてゐる。表面が焼けたら、肉が浸るくらゐ赤ワインを注ぎ込む。そして1時間ほど弱火で煮る。暇だったらあくを取ったりしてもいい。一時間を過ぎると水分が減ってゐると思ふので、水を足して、ローリエの葉などの香草を入れる。私はお茶用の袋にローリエ、ローズマリー、タイム、キャラウェイなどそのときの気分で入れて鍋に投入してゐる。4つくらゐに切った玉葱、適当に切ったトマト(その日の都合で缶詰の場合もある)、そして固形スープの素(料理には疎いので微妙な味の調整などそもそもできないから、これでいいのだ)を入れて5時間くらゐ煮続ける。分量はすべてそのときの気分。秤量してゐないから、記せないのだ。大蒜やセロリとか人参とか入れてみたこともあるけれども、面倒くさくなって肉と玉葱とトマトだけになった。前と何が違ふのかといふと、最初の一時間は肉だけ煮るといふところである。最初は全部一緒に投入してゐた。何と何の組合はせがいけないのかは調べてゐないのだけど、かういふ順に入れれば、少なくとも私の口に合ふ味にはなる。これを参考にして失敗しても私は責任をとれないので、あまり信用しないやうにお願ひする。
写真はない。かういふ調理法を記したページでは得意げに写真を掲載するのが常だが、私には恥づかしくてそんなことはできない。代りにブリューゲルの「農夫の婚礼」でも載せておかう。牛頬肉は食べてゐないやうだけど。

あ、いつもの癖で歴史的仮名遣ひで書いてしまった。直すのが大変だから、このまま載せてしまはう。
2008-09-10 23:22:01
小学生か中学生の頃、食虫植物に夢中になっていた。何十種類という食虫植物を集め、水苔に植えては成長を見守っていた。植物を育てるというのはあまり少年らしくない趣味だが、食虫植物というところは少年らしい。食虫植物の育て方をいろいろ調べてくるとよく見かける文章が、「生きている水苔に植えるのが最適」だというものである。生きている水苔って何だ。いや、何かは解るのだが、一体どうやったら手に入るのか。園芸店でも見たことがない。一度だけ旅行先の園芸店で見かけたことがあるのだが、盆栽の一部で、水苔だけは売っていないという。水苔のために高価な盆栽を買って水苔以外の部分を捨てるわけにもいかない。それ以前に、そんなものを買う金は持っていなかった。私は中学生だったのだ。
やがて食虫植物に注ぐ気持ちも余裕もなくなって、本ばかり読む生活を続けていたが、なんと今年の八月に生きている水苔を手に入れたのだ。インターネットとは恐ろしい。何でも手に入る。百年前のダンセイニに関する新聞記事を読むこともできれば、生きている水苔を買うこともできる。水苔を手に入れて、久し振りに購入したハエトリソウを植えた。嬉しかった。30年以上の願いが叶ったのだ。

この頃はハエトリソウよりも水苔の育ち具合の方が気になってしまう。水苔と食虫植物の話はまだまだ続く(と思う)。
2008-09-10 21:37:54
 Googleが「新聞各社と提携し、過去の新聞記事をデジタル化してオンラインで検索可能」(ITmedia他多数)という記事を読んだ。早速Google News Archive Searchとやらを試してみて驚いた。古い記事が本当に検索できるのだ。
Googleが「新聞各社と提携し、過去の新聞記事をデジタル化してオンラインで検索可能」(ITmedia他多数)という記事を読んだ。早速Google News Archive Searchとやらを試してみて驚いた。古い記事が本当に検索できるのだ。
たとえば、ロード・ダンセイニのThe Queen's Enemiesという作品がthe Neighborhood Playhouseで上演されたときのNew York Times 1916年11月15日に載った記事を探し出して、それをpdfで全文読めるのである。ちなみにその作品はHorrorMasters.comで全文読める。
これだけいろいろなものが調べられるようになると、調べていないことは単なる怠慢になってしまう。百年前の外国の新聞に載った記事を探して写しを手に入れるなんて、一般庶民の我々にはとうていできない(可能なのかも知れないけれど、一体どうやったらいいのか解らない)ことだったのだが、これなら誰でもいつでもできるのだから。もちろん、すべての新聞記事が調べられるわけではないので、そういう記事がなかったことは示せないけれども、少なくとも一つはそういう記事があったことだったら容易に示せるのだ。
2008-09-09 21:11:18
 昨日届きました。DVD全然大丈夫 特別版。目当ては特典映像の方に入っている舞台挨拶だかトークショーだかの映像。主役級の人たちには全然関心がなくて、鳥居みゆきですね。2月21日に開催されたときのもの。そのときの映像はニュースサイトなどにいくつか出ていたのですが、今までに見たことのない場面が収録されていて、損した気分になって落胆したりはしませんでした。といっても、髪引っ張って変な顔しているところだったりしますが。とにかく、この数分間だけのために買いました。
昨日届きました。DVD全然大丈夫 特別版。目当ては特典映像の方に入っている舞台挨拶だかトークショーだかの映像。主役級の人たちには全然関心がなくて、鳥居みゆきですね。2月21日に開催されたときのもの。そのときの映像はニュースサイトなどにいくつか出ていたのですが、今までに見たことのない場面が収録されていて、損した気分になって落胆したりはしませんでした。といっても、髪引っ張って変な顔しているところだったりしますが。とにかく、この数分間だけのために買いました。
そのときのニュースサイトから。もっとたくさんあるけれども、面倒臭くなったので、4つだけ。
- シネマトゥデイ「この人だいじょーぶ?鳥居みゆきの支離滅裂トークも全然大丈夫!」
- TV LIFE 鳥居みゆきが映画「全然大丈夫」のトークショーで支離滅裂!?
- eiga.com ピン芸人の鳥居みゆきが大暴走!「全然大丈夫」トークショー
- BARKSニュース 鳥居みゆき、トークショーで独走状態
このあと、電車の連結部分でヒットエンドラ〜ンの練習をする人が続出するんじゃないかと思ったけれども、まだそういうことは聞いていません。私もしませんけど。
2008-09-08 23:41:38
今日の朝顔は近くに寄った朝顔。「今日の朝顔」といっても、毎朝の写真を掲載する訳ではありません。今日は寄ってみた写真が’あったので、何となく。

2008-09-08 23:26:53
一昨日導入したGoogle Desktopだが、土日のうちにインデックス作成が終わっていた。Google Desktop APIsにある説明を読んで、真似してみようかと思ったが、ポートは4664ではなく32051だ。4664で繋ごうとしても、
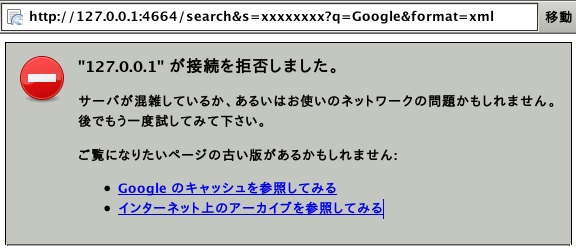
と返されてしまう。そこで、Google Desktop APIsにある説明のように、http://127.0.0.1:32051/search?flags=8&hl=ja_JP&num=10&q=glucose&start=0&s=xxxxの後ろに、&format=xmlをつけてやったらxmlで検索結果を返してくれるのかと思ひきや「存在しないページがリクエストされました。」と云われてしまう。解らない。
そこで、MacOSXにインストールしてみた。今度はポート番号は5089だった。
「google」を検索すると下のようなURLになった。
http://127.0.0.1:5089/search?q=google&s=xxxx&ie=UTF-8&btnG=Suche
そこで、この後ろに、
&num=30&format=xml
をつけてやったら、XML形式で30件の結果が表示された。どうなっているのか。Linuxでは駄目なのか。ネット上を彷徨っても情報は得られなかった。
とりあえず、HTML形式で返ってきた結果を正規表現で取り出して強調表示してみた。が、納得できない。これで一度に100件とか500件とか表示してくれれば、自分がため込んでいる文献検索なんかが楽なのだが。用例検索ができて嬉しいのだが。
#!/usr/bin/python
import sys
import urllib
import re
from re import *
keyword = sys.argv[1]
query = {'hl':'ja_JP','s':'xxxxxxxxxxxx',\\
'ie':'UTF-8','adv':'1','type':'cat_files','filetype':'pdf',\\
'ext':'','mediatype':'','emailfrom':'','emailto':'',\\
'domain':'','q':keyword,'no':''}
url = 'http://127.0.0.1:32051/search?' + urllib.urlencode(query)
file = urllib.urlopen(url)
content = file.read()
file.close()
re_summary = re.compile('<span class=\"snippet\">.+?</span>')
items = content.split('<div class=\"searchresult\">')
items = items[1:]
table = '<table border="0">\n'
for item in items:
summary = re_summary.search(item).group(0)
kwds = re.findall('<b>.+?</b>',summary)
parts = re.split('<b>.+?</b>',summary)
j = 0
for kwd in kwds:
trow = "<tr><td align='right'>"+\\
parts[j][(len(parts[j]))-25:]+\\
"</td><td align='center'>"+kwd+\\
"</td><td>"+parts[j+1][0:25]+"</td></tr>\n"
table += trow
table += "</table>\n";
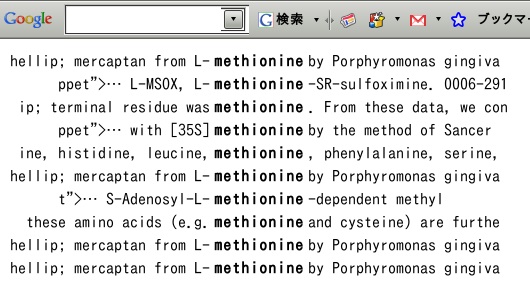
print table
こんな具合に書いて、ブラウザで開けば下のようになる。自分で溜め込んで整理していない論文pdfファイルから、用例を抜き出して提示してくれる。XML形式でどうしても返して来ないところが不愉快だが、これはもう少し真面目に作ってみようか。
2008-09-07 20:18:50
 AppleのMac mini(1.83GHzの方。メモリを2GBにした。)を註文したが、そんなに楽しくない。なぜなら私が使うものではなく、妻が使うから。今まで昔私が買ったPowerMac G4(グレイのポリタンクみたいな姿の)を使っていたのだが、さすがに調子が悪くなってきたらしい。先週調子が悪いと訴えたときには、電源ケーブルが外れかけていることを指摘して、ちゃんと差し込んだから突然止まってしまうことは今後はないと云ってもうしばらく使わせようとしたのだけど、Microsoft Wordが反応しなくなってせっかく書いた文書の変更が失われてしまうことがあるという。ならばMicrosoft Wordなんか使わなければいいと云ったのだが、使いたいという。どうしてみんな文句をいいながらあれを使うのだろう。素晴らしいソフトウェアだと褒め称える人に出会ったことがない。皆ひどい目に遭ったという。不思議だなあ。だから、私はMicrosoft Wordは使わない。ほとんど不自由はしていない。相手から送られてきたファイルを開くときに不愉快な思いをするだけである。ほとんどの文書はテキストファイルで保存している。テキストファイルは裏切らない。信用できる。
AppleのMac mini(1.83GHzの方。メモリを2GBにした。)を註文したが、そんなに楽しくない。なぜなら私が使うものではなく、妻が使うから。今まで昔私が買ったPowerMac G4(グレイのポリタンクみたいな姿の)を使っていたのだが、さすがに調子が悪くなってきたらしい。先週調子が悪いと訴えたときには、電源ケーブルが外れかけていることを指摘して、ちゃんと差し込んだから突然止まってしまうことは今後はないと云ってもうしばらく使わせようとしたのだけど、Microsoft Wordが反応しなくなってせっかく書いた文書の変更が失われてしまうことがあるという。ならばMicrosoft Wordなんか使わなければいいと云ったのだが、使いたいという。どうしてみんな文句をいいながらあれを使うのだろう。素晴らしいソフトウェアだと褒め称える人に出会ったことがない。皆ひどい目に遭ったという。不思議だなあ。だから、私はMicrosoft Wordは使わない。ほとんど不自由はしていない。相手から送られてきたファイルを開くときに不愉快な思いをするだけである。ほとんどの文書はテキストファイルで保存している。テキストファイルは裏切らない。信用できる。
そこで言い争っても仕方がないので、Mac miniを買うことにしたわけだ。
それに、I-O DATA WSXGA+ 22型という液晶モニタ。22インチが三万円以下で買える時代になったとは! 私が19インチなのに、何だか悔しい。でも、昨日DellのInspiron Mini 9が欲しいと云ったばかりだ。Mac miniと22型液晶モニタとInspiron Mini 9を全部買っても20万円を越えないのだが、その20万円がないから買えない。この中で一つだけ買えるとしたら何にしようか。あ、24.1インチが39,980円だ。それでもいいかな。
2008-09-07 13:55:21
コンピュータを関係のない話を書くことにしたのだった。うっかり忘れていた。
朝顔である。数年前朝顔ばかり育てていた頃があった。といっても、品評会に出そうとかいう訳でなく、個人的に育てていただけだが。
当時、早朝六時前に朝顔の写真を撮っていたら誰かに見られていたらしく、妻が近所の人に「本当に朝顔がお好きなんですね」と云われたらしい。朝顔が好きで悪いか。
あれから引っ越したので朝顔を写真を撮ってみることにした。あの頃はデジタルカメラなんて持っていなかったが、古いもの好きの私も今年の初めに一つ買ったのだった。写真が大嫌いなので、あまり活用していない。
今年数年ぶりに育てた朝顔は種ではなく苗を買ったものだ。ペットエコ&ザガーデン楽天市場店から購入した。「かざぐるまシリーズゆき姫」と「かざぐるまシリーズお銀」という品種である。


今年は変な病気に感染してしまったのか、どの朝顔も葉が捻れてきて成長が止まってしまった。今は花だけがぽつぽつ開いていく。花は綺麗なのだが何だか可哀想である。

桔梗咲きの画像は、ちょっと検索すれば個人の朝顔愛好家の写真が無数に出てくる。いろいろな朝顔の姿を確認したい人は、アサガオ類画像データベースとか、九州大学大学院理学研究院アサガオホームページで、さまざまな朝顔の姿とともに桔梗咲きの姿も見いだすことができる。
来年はもっと健康に育ててやりたい。
2008-09-07 00:19:17
巷ではこの頃ミニノートパソコンが話題なのだけど、私はWindowsは使えないので、冷たく横目で眺めていたのだった。ubuntuをインストールしましたというような報告はたくさんあるのだが、自分で挑戦する元気は今のところないから、どうでもいいやという気分だったわけだ。だから、上のようなものをDellが売り出したというのを見ても、へえ、そうなんだと思っただけだった。Atom N270 (1.6GHz)/1GB DDR2-SDRAM メモリ/Windows(R) XP Home Edition Service Pack 3という構成で57,979円。もうAmazon.co.jpで売っている。それでも、唾を吐きかけながら、だから何なんだよ、私はWindowsは使わないんです、あなたとは違うんです! と言い放ちたい気分だった。しかし、記事をよく読むと、Ubuntu版があるというじゃないか。Ubuntu 8.04 (DELL カスタマイズ版)/512MB DDR2-SDRAM メモリで(CPUはWindows版と同じ)49,980円。欲しい。メモリは1 GBに増やせるようだし、嬉しいのがUSキーボードが選べること。Dellから直接買えばだけど。
Ubuntu版は九月下旬発売だというから、それまでに金を貯めよう。無理だと思うけれども。問題は、そんなものが私に必要かということだ。全然出かけない私に、そんなものが必要なのか。でも、欲しいんだから仕方がない。金を貯めよう。
2008-09-06 21:01:29
数日前にGoogleKWICを作ったときのことだが、ここでは表をブラウザのウィンドウの幅に合わせて改行しないようにcssを使って設定している。app.yamlで指定してやることになるのだが、こんな記事(にーやんのブログ「Google App Engine SDK: CSS や JS などの静的ファイルを利用する」)を読んだので、真似してやってみたら駄目だった。
- url: /css static_dir: cssと書くと、
<class 'google.appengine.tools.dev_appserver.InvalidAppConfigError'>:\\ regex invalid: unbalanced parenthesisというエラーが出てうまくいかないのだという。そこで、
- url: /css/(.*\.css) static_files: css/\1 upload: css/(.*\.css)と記したらうまくいったそうだ。でも、私は駄目だった。
- url: /css static_dir: cssと書いたらうまくいった。一体どうなっているんだ?
2008-09-06 00:09:16
Google App EngineでAmazon ECSから10件以上の結果を受け取るために、こんなふうにしてみた。といってコードを掲げようかと思っていたのだが、そんなに人に見せるほどのものでもないので、やめた。ただ、20件なら2回、100件なら10回リクエストを送っているだけなんだけだから。 Amazon ECSには一秒ルールというのがあるらしいので、リクエストを一回送ると1秒待つようにしている。これを使って何を作ろうか、まだ思案中。
Google Desktopをubuntu 8.04にインストールしてみた。昨日入れたのだが、初回のインデックスがまだ終わらない。まだ3分の1も終わっていない。残りおよそ60時間! とはいっても、実は一晩で終わりましたってことにならないかと期待していたのだけど、あれから二晩経ってもまだ終わらない。

せっかく検索できるようになるのだから、Google Desktop Search APIsを利用してみようと思い、 ttp://127.0.0.1:4664/search&s=xxxxxx?q=keyword&format=xmlという感じでアクセスしてみたら、応答を拒否されましたというような表示が返ってくるだけ。どうなってゐるんだ? またいつものやうに、自分のファイルの検索結果をKWIC表示してやろうと思ったのに。
ここ数日Google関連のものをいくつか試してみたのだけど、この関係の本は少ないような気がする。Google Appsで検索してもほとんどないじゃないかと思っていたら、グーグル・サービスとかで検索したら何冊か出てきた。私が今ほんとうに欲しいのは、Google App Engineの本だが、それは本当にまだほとんどないようだ。
こんなふうに、コンピュータ関連のことを書き記してきたのだが、今後は幅広い話題を書いていくことにしたい。本のこと以外の話題なら、何でも。本のことばかり長年書いているページがあるので、それは書かない。ときどき写真なんか載せながら。普通の人が普通に書いているブログみたいなものですね。ちょっと真似してみようかと思って。
2008-09-02 22:42:40
ようやく使い方が少し解ったので、いつものようにKWICである。gglkwic.appspot.comで使えるようにした。コードはしたのような感じで。
import cgi
import wsgiref.handlers
import urllib
from google.appengine.ext import webapp
from google.appengine.api import urlfetch
from django.utils import simplejson
import re
from re import *
class MainPage(webapp.RequestHandler):
def get(self):
self.response.out.write("""
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="ja">
<head>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
<link type="text/css" rel="stylesheet" href="/css/gglkwic.css" />
<title>GoogleKWIC</title>
</head>
<body>
<h2>GoogleKWIC</h2>
<form action="/kwic" method="post">
<div><input type="text" name="word" ></div>
<div>言語:
<select name="lang">
<option value="ja" selected>日本語</option>
<option value="sl">スロヴェニア語</option>
<option value="sv">スウェーデン語</option>
<option value="tr">トルコ語</option>
</select>
結果数:
<select name="resnum">
<option value="2" selected>16</option>
<option value="4">32</option>
</select>
</div>
<div><input type="submit" value="検索"></div>
</form>
<p>調べたい語句を入力し、検索ボタンを押してください。<br />
検索は<a href='http://code.google.com/apis/ajaxsearch/'>
Google AJAX Search API</a>を利用します。</p>
</body>
</html>""")
def kwic(word,lang,resnum):
urlbase = 'http://ajax.googleapis.com/ajax/services/search/web?'
res = []
for i in range(int(resnum)):
query = {'v':'1.0','q':word.encode('utf-8'),'hl':lang,'rsz':'large',\
'start':str(i*8),'key':'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'}
url = urlbase + urllib.urlencode(query)
result = urlfetch.fetch(url)
if result.status_code == 200:
a = simplejson.loads(result.content)
results = a['responseData']['results']
for r in results:
title = r['titleNoFormatting']
content = r['content']
url = r['url']
res.append({'title':title,'content':content,'url':url})
return res
class Result(webapp.RequestHandler):
def post(self):
word = self.request.get('word')
lang = self.request.get('lang')
if lang == ('ja' or 'ko' or 'zh-TW' or 'zh-CN'):
width = 20
else:
width = 30
resnum = self.request.get('resnum')
results = kwic(word,lang,resnum)
table = "<table border='0'>"
for r_item in results:
content = r_item['content'].replace('<b>...</b>','')
kwords = re.findall('<b>.+?</b>',content)
parts = re.split('<b>.+?</b>',content)
j = 0
for kword in kwords:
trow = "<tr><td align='right'>"+parts[j][(len(parts[j]))-width:]+\
"</td><td align='center'>"+kword+"</td><td>"+parts[j+1][0:width]+\
"</td><td><a href='"+r_item['url']+"' target='_blank'>"+\
r_item['title'][0:10]+"</a></td></tr>"
j += 1
table += trow
table += "</table>"
self.response.out.write('<html xmlns="http://www.w3.org/1999/xhtml" \
xml:lang="' + lang + '">\n<head>\n<meta http-equiv="content-type" \
content="text/html; charset=UTF-8" />\n<link type="text/css" \
rel="stylesheet" href="/css/gglkwic.css" />\n<title>GoogleKWIC\
</title>\n</head>\n<body><h2>GoogleKWIC</h2>\n<p>Keyword = <strong>')
self.response.out.write(cgi.escape(word))
self.response.out.write(('</strong></p>\n'))
self.response.out.write(table)
self.response.out.write('</body></html>')
def main():
application = webapp.WSGIApplication([('/', MainPage),
('/kwic', Result)],
debug=True)
wsgiref.handlers.CGIHandler().run(application)
if __name__ == '__main__':
main()
昨日も書いたように、一回の検索で返ってくる結果の上限はわずか8件。これを何回もまわせばいいのかと思ったが、5回以上回したらエラーが出てしまった。毎回1秒待ってみたけれども、同じだった。ばれているのか。最大32件じゃ頻度を集計して並べ替えたりする気にもならない。これでは全然面白くない。件数の多さではTechnoratiなのだが、どうも使いにくい。何れにせよ、もっと面白い使い方を探してみよう。2008-09-01 21:44:37
Google AJAX Search APIの動かし方を試していたときに、どうして結果が4件しかないんだ! と思ったら、初期条件は4件らしい。説明はちゃんと読まなければいけない。rszという引数について、「この引数 (省略可能) は、アプリケーションが受け取る結果の数を指定します。small の値は、結果セットのサイズが小さいこと、つまり 4 件の結果を示します。large の値は、結果セットが大きいこと、つまり 8 件の結果を示します。この引数が指定されない場合、値は small と仮定されます。」と書いてあるではないか。
ならば、40件の結果を得たいときは、rsz=largeにして4回繰り返せばいいのか。29日の記事の、情報を取得する部分をこんなふうにしてみた。
class MainPage(webapp.RequestHandler):
def get(self):
urlbase = 'http://ajax.googleapis.com/ajax/services/search/web?'
for i in range(5):
query = {'v':'1.0','q':'London','rsz':'large','start':i*8,'key':'xxxxxx'}
url = urlbase + urllib.urlencode(query)
result = urlfetch.fetch(url)
if result.status_code == 200:
a = simplejson.loads(result.content)
results = a['responseData']['results']
if i == 0:
self.response.out.write("<html><body><h1>Test</h1>")
self.response.out.write("<table border='1'><tr><th>title</th><th>content</th></tr>")
for r in results:
self.response.out.write("<tr><td>%s</td>" % r['title'].encode('utf-8'))
self.response.out.write("<td>%s</td></tr>" % r['content'].encode('utf-8'))
self.response.out.write("</table></body></html>")
何となくそれらしい結果は返ってきたようだけど、この方法でいいのだろうか。これで50回まわして400件の結果を取得しても怒られたりしないのだろうか。怒られるかどうか試してみようか。
とりあえず、これでまたKWICだろうか。数百件の結果が得られるなら前後に出現する単語の頻度順に並べてみるとか、検討してみてもいい。
YahooKWICの言語の選択肢を増やしてみた。こんなに増やしてどうするのかというくらい。Yahoo! SearchAPIの方で選べるものでも、右から左に書く言語(アラビア語とヘブライ語)などは入れていない。フレーズ検索も選べるようにした。空白を含む語句で、つまり複数の単語の組み合わせによる表現で検索できるということである。英語でその効果を確認したが、思ったほどでもなかった。単語でもそれなりに結果がでてしまうので。日本語の場合、意味がある結果になっているのかどうか解らなかった。
Technoratiでもこのようなフレーズ検索ができればいいのだが。サイト上での詳細検索ではできるのだが、APIの方には記されていない。どうなのだろう。
最新の日記に戻る