2008-10-31 22:25:48
![]() Snipdは、「Grab and save pieces of pages.」とトップページに記されているように、気になるサイトの一部を切り取って、一つのページにまとめて保存できるもの。刻一刻と更新される画像などは、最新版が表示される。ブックマークで切り取り機能を導入するので、どんなブラウザでも多分使える。私は保証できないけど。
Snipdは、「Grab and save pieces of pages.」とトップページに記されているように、気になるサイトの一部を切り取って、一つのページにまとめて保存できるもの。刻一刻と更新される画像などは、最新版が表示される。ブックマークで切り取り機能を導入するので、どんなブラウザでも多分使える。私は保証できないけど。
貼り付けられるものは、テキスト、画像、動画である。でも、レイアウトを自由にできるわけでもないので、下から順に貼り付けたものが表示される(という理解でいいのだろうか)。管理画面と表示画面が別なので、表示画面だけを人に見せることもできる。というより勝手に見られてしまうこともあるという解釈で正しいのだろうか。だから、恥ずかしい情報を集めたりしない方がいいと思う。
でも、どうもうまい使い方が解らない。ニュース記事を集めるとか? 為替相場を表示させるとか? 新刊情報とか? 慣れれば使いやすく感じるのかな。
2008-10-30 23:37:45
私は活字が大好きで、画像とか動画とかにはあまり関心がなかった。だから、誰でも知っているような動画サイトも名前は聞いたことがあるという程度だった。今年の初めまでは。鳥居みゆきを知ってから、動画サイトに詳しくなったのだが、今日の話はそれとは関係なくて、偶然見つけた(見つけるのは大抵偶然だが、そういう細かいことはあまりとやかく云わない方がいい)RuTubeにちょっと驚いた。まあ、ロシアに詳しい人はみんな知っているサイトだろうが、私はロシアには疎いので、全然知らなかったのだ。
もう一つロシアの動画サイトで、ニュースばかり集めているnewstubeというのも見つけて、これはロシアのニュースを見るのに便利だと感激したわけである。尤も、ロシア語がわからないから、さっぱり内容は理解できないのだが。
さらにМедведев大統領のビデオブログ(Видеоблогと書いてあるから、そうなんだろう)を見つけて、これまた驚いた。まあ、何を云っているのかはさっぱり解らないのだが、金融危機の話か何かしているようだ。ビデオブログというんだから、週一回くらいは新しいのを追加してほしいものだが、今月7日から始まって、まだ二つである。三日坊主にならないことを願っている。RSSで新着情報を知らせてくれるはずだと思って探したけれど、見つけられなかった。当然あって然るべきだろう。せっかくだから、リンクを張ってみよう。
2008-10-30 23:07:39
 若い頃は私も肩凝りなんて知らなかった。言葉は知っていても、一体それがどんなものなのかさっぱり想像もつかなかった。やがて肩や首のあたりがつらいと感じるようになったのだが、長い間それが肩凝りと呼ぶものだとは気づかなかったのである。今ではもう肩凝りは常に私から離れることなくつきまとうようになっている。片時も離れず両肩の上に重くのしかかる。
若い頃は私も肩凝りなんて知らなかった。言葉は知っていても、一体それがどんなものなのかさっぱり想像もつかなかった。やがて肩や首のあたりがつらいと感じるようになったのだが、長い間それが肩凝りと呼ぶものだとは気づかなかったのである。今ではもう肩凝りは常に私から離れることなくつきまとうようになっている。片時も離れず両肩の上に重くのしかかる。
床屋に行くと散髪・洗髪の後に数秒から数十秒肩を揉んでくれるのだが、そのときに「凝ってますねえ、ばりばりですね。痛くありませんか」なんて云われることがある。そりゃあ、痛いに決まっていますよ。「ええ、気が狂いそうになるくらい痛いんですよ」と云ったこともある。何か面白いことを云ったと勘違いされたようだが、笑い事じゃないくらい痛いのだ。腕の方まで痛くなって、手が痺れるように感じられることもある。
 右手でマウスが扱えなくなった話は別の機会にしたいと思うが、今日は気持ち悪い枕(といっていいのか)を見つけた話をしたかったのだった。左上に画像がある、それですがね。両手で包み込むように、首から頭を支えてくれる(らしい)。動く枕ではないから、これで肩を揉んでくれるというわけでもないだろう。これで俯せに寝たらどんなに不気味だろうかとつい想像してしまう。最初は優しく頬を包み込むように受け止めてくれていたのが、不意にがっしりとつかまれて口と鼻を押さえられ、必死で引きはがそうとしてもなかなか離れず、やがて手足をばたつかせる動きもなくなって、不気味な枕に顔を包まれて永遠の眠りに就いてしまうのだ。怖い。私にはとても使えない。普段から私は枕を使わないから、関係ないんだけど。
右手でマウスが扱えなくなった話は別の機会にしたいと思うが、今日は気持ち悪い枕(といっていいのか)を見つけた話をしたかったのだった。左上に画像がある、それですがね。両手で包み込むように、首から頭を支えてくれる(らしい)。動く枕ではないから、これで肩を揉んでくれるというわけでもないだろう。これで俯せに寝たらどんなに不気味だろうかとつい想像してしまう。最初は優しく頬を包み込むように受け止めてくれていたのが、不意にがっしりとつかまれて口と鼻を押さえられ、必死で引きはがそうとしてもなかなか離れず、やがて手足をばたつかせる動きもなくなって、不気味な枕に顔を包まれて永遠の眠りに就いてしまうのだ。怖い。私にはとても使えない。普段から私は枕を使わないから、関係ないんだけど。
2008-10-29 23:38:41
 「米Hewlett-Packard(HP)は10月29日、ミニノートPCの新モデル3種を発表した」という記事を今朝目にしてちょっと狼狽えた。379ドルのLinuxモデル? へえ、Linuxって何なのかなあ、羨ましいなあ……といったわけである。もちろん、このHPのが出ようと出まいと私が註文したInspiron Mini9の性能に何の違いも生じない。でも、真っ先にubuntu搭載Netbook機をDellが出したから、Inspiron Mini9を註文したのである。真っ先に発送して欲しい。それに、発送しないうちにクレジットカードで代金を請求しないでもらいたいものだ。
「米Hewlett-Packard(HP)は10月29日、ミニノートPCの新モデル3種を発表した」という記事を今朝目にしてちょっと狼狽えた。379ドルのLinuxモデル? へえ、Linuxって何なのかなあ、羨ましいなあ……といったわけである。もちろん、このHPのが出ようと出まいと私が註文したInspiron Mini9の性能に何の違いも生じない。でも、真っ先にubuntu搭載Netbook機をDellが出したから、Inspiron Mini9を註文したのである。真っ先に発送して欲しい。それに、発送しないうちにクレジットカードで代金を請求しないでもらいたいものだ。
そんなことを思っていたら、Dellから「ご注文いただいた商品の納期遅延のご連絡とお詫び」というメールが届いた。「生産が進まずご購入時に表記のあった納期よりさらにお時間をいただいております」だという。九月下旬に作るんじゃなかったのかね。「早急な出荷に向けて、弊社では最優先事項として引き続きパーツ入庫の交渉および対応を進めてまいります。現時点では、パソコンのお届け予定は11月の中旬になる見込みでございます。」と書いてある。11月中旬か。あと半月なんだが、大丈夫なのか。遅れた分、割引とかしてくれたりしないかね。
2008-10-29 23:10:07
![]() プレゼンテーション(所謂スライド)の作成・発表などがオンラインでできるSlideRocketである。昨日辺りから、PublicBetaになって公開されたというので、早速試してみた。前に280 Slidesを試してみたことがあるが、あれに似ている。無料版、月10ドル、月20ドルの3コースがある。無料版では容量250MB までで共同作業ができないなどの制限がある。用意されている紹介動画を観ると確かに使いやすそう。引用句を検索して利用できるところが面白い。
プレゼンテーション(所謂スライド)の作成・発表などがオンラインでできるSlideRocketである。昨日辺りから、PublicBetaになって公開されたというので、早速試してみた。前に280 Slidesを試してみたことがあるが、あれに似ている。無料版、月10ドル、月20ドルの3コースがある。無料版では容量250MB までで共同作業ができないなどの制限がある。用意されている紹介動画を観ると確かに使いやすそう。引用句を検索して利用できるところが面白い。
問題は、日本語の入力ができないこと。280 Slidesの場合、直接入力はできなかったが、コピー&ペーストで日本語スライドを作成することはできたが、こちらはそれもできない。1バイト文字しか使わないものを作るときにはいいのだろうが、私は極力日本語を使用したいので、あまり活用できない。残念。
2008-10-29 22:57:25
日が暮れるのも早くなって、仕事から帰るときは真っ暗になってしまった。もう少しすると仕事に出るときも真っ暗になってしまう。私は日の光が嫌いなので、大歓迎だ。真冬の寒い夜を歩くのが実は好きだったりする。尤も、北国で暮らしたことがないので、そんなに寒い夜でもない。雪が積もった夜道は苦手だ。
よくある話だが、夜中にかつかつと靴の音を響かせて歩いているときに若い女性を追い越しそうになって、もう少しで追い越せそうになった瞬間に走り出して逃げて行かれるのが困る。そのまま走り去ってしまえばいいのだが、また追いついてしまってまた走り出してまた追いついてしまってまた走り出してを繰り返していると、まるで後を追いかけているような感じになってしまう。心の中で頼むから追い越させてくれと叫んでも無駄である。走って追い抜きたい衝動に駆られるが、犯罪者と間違えられると大変なので、きっとみんな我慢しているのだろう。
怖い気持ちもわからないではない。イギリスの有名な怪奇小説作家E・F・ベンスンの作品に「跫音」(原題The Step)というのがあって、真夜中に跫音に追われる描写がしみじみ怖い。あれを読んだらもう逃げ出さずにはいられまい。結末はちょっと面白いのだけど、跫音を気にしながら歩くところ怖いのだ。私はいつも追いつく方なので、跫音に追われる恐怖を味わうことはほとんどない。
真夜中の道で怖い思いをしたことがある。一月か二月の夜に最寄り駅まで行く電車の最終に乗り遅れて、三つほど手前の駅で降り、二時間ほどとぼとぼ歩いて帰宅していたときのこと。数年ぶりに帰省したときのことで、道もよく覚えていなくて、前にも後ろにも誰も人影のない道を白い息を吐きながら一人で歩いて、ようやく家の近くまで来てほっとしたときのことだった。前方から若い男が自転車に乗ってやってきた。その辺りは田圃の中の一本道で夜中の二時に自転車で走るようなところではない。かなりの速度でじっとこちらを見ながら走ってくる。この頃、若い男が自転車から斬りつけて走り去っていく事件が新聞によく載っているではないか。そんな奴だったらどうしよう。
びくびくしながら歩いていくと、男は真っ直ぐこちらに向かってくる。白っぽいジャンパーを身に着けているから、よく見える。どんどんどんどん近づいてくる。このままではぶつかる! ナイフで刺されるのか、鈍器で殴られるのか、痛いのは嫌だなあと思っていると、自転車は急ブレーキをかけて私の行く手を遮るように止まった。はっきりいって私は腕に自信はない。若者と戦えば負けるだろう。でも、決して強そうな男ではなかった。あと100メートルくらいで家なのに。ここで死ぬのは嫌だ。機先を制して鼻でも殴って相手が怯んだ隙に走って逃げたら可能性はあるだろうか。そんなことを考えながら、身構えていると、若い男が云った。
「駅に行くのはこの道でいいんですか」
こいつは深夜の二時に道も解らずに自転車で走っていたのか。それとも、迷子になったらから二時まで走っているのか。
「○○駅ならこの方向でいいんだけど、一本道じゃないからちょっとわかりにくいかも知れませんね」と答えると、意外に丁寧な感じで「そうですか、ありがとうございました」と礼を云って走り去っていった。
まあ、それだけの話なんですけどね。

2008-10-28 22:26:03
![]() アメリカでは2006年に始まっていたGoogle Trendsの日本語版Googleトレンドが今日公開されたというので、ちょっと見てみた。今まで日本語版がないことに気がついていなかった。
アメリカでは2006年に始まっていたGoogle Trendsの日本語版Googleトレンドが今日公開されたというので、ちょっと見てみた。今まで日本語版がないことに気がついていなかった。
急上昇ワード (日本)一覧ページもある。
何か試してみようか。私の名前なんか入れても、検索回数が少なすぎてグラフが書けないよという警告が出ておしまいだ。そこで、「鳥居みゆき」と入れてみることにした。2007年10月から忽然と姿を現していることが解る。最初のまさこが8月で、「芸人面接」が10月だったか。実はその頃私は全然こんな芸人のことは知らなかった訳だが。2月のR1グランプリのときと、4月30日から5月初旬の「実は結婚していた」ニュースのときに検索件数が多いことが伺える。
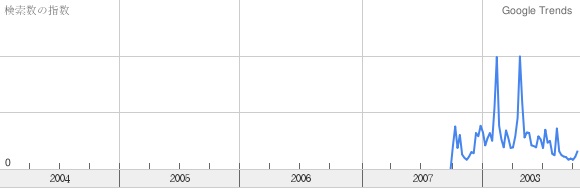
Google TrendはAPIは公開していないのだろうか。前に、近いうちに公開するらしいというニュースを読んだことがあるのだが、結局そのままなのか。利用できたら、自分のサイトに埋め込んだりできるんだろうけど。
2008-10-28 00:00:44
 携帯小説とやらいうものですか、これは。よく携帯電話がよく使えない私には縁のない世界ですね。あんな難しい装置の操作がよくできるものだ。しかも、一本指で文章を入力するなんて人間のすることとは思へません。私は10本全部使っても頭の中に浮かぶ文章を打ち込むのが間に合わないというのに、一本で入力するなんて。前に、駅に着いたということを知らせる文を入力するのに15分くらいかかったことがある。今ではパソコンから転送して送信する技を覚えましたけどね。
携帯小説とやらいうものですか、これは。よく携帯電話がよく使えない私には縁のない世界ですね。あんな難しい装置の操作がよくできるものだ。しかも、一本指で文章を入力するなんて人間のすることとは思へません。私は10本全部使っても頭の中に浮かぶ文章を打ち込むのが間に合わないというのに、一本で入力するなんて。前に、駅に着いたということを知らせる文を入力するのに15分くらいかかったことがある。今ではパソコンから転送して送信する技を覚えましたけどね。
 そんなことはどうでもいいのだけど、あまり関心のない『やさしい旋律』[amazon.co.jp,
そんなことはどうでもいいのだけど、あまり関心のない『やさしい旋律』[amazon.co.jp, bk1,
楽天,
紀伊國屋書店,
Yahoo! Books]ですが、それが映画化されるそうで、それはそれでこれもまたあまり関心がないのですが、鳥居みゆきが出るというところに関心があるわけです。若女将役だそうです。友情出演だそうです。一体どういう友情なんだか。本当の友情を意味していないところだけれども、友情という言葉が本当に似合わない人だと思う。映画を観に行くことはないと思いますが、DVDが出たら註文してしまうかも知れません。
最近驚いたのは2007年7月のGETLIVE #30の映像。白まさこ以前の、まさこの原型というようなものでした。2月のエンタの神様でやった「うらみま〜す」ってやつとほぼ同じなのですが、あれに出てきた木下さん擬きは、地上波用に書き換えた木下さんではなく、木下さんになる前の原型木下さんだった訳です。
映画とかTVのバラエティ番組なんかに出てもあまり面白くないので、芸人鳥居みゆきらしいものを観たいものです。
2008-10-26 19:07:42
もう十月も数日しか残っていないのに、陽が差すと意外に暑くなったりします。そんな中、水苔もそれなりに元気です。この頃はもうプランターの縁からはみ出しそうになっていて、どうしたものかと思案中です。一度全部出して、下の方を切り取って乾燥させて保存し、緑に近い方をまたプランターに植えておくというのが普通でしょうか。

ああ、焦点が合っていない。手が震えてしまったのか。前に、食虫植物の鉢から移植した部分も伸びてきて、ほぼ全面が緑になっています。ところどころ、色が濃くなって形が変わってきた部分があります。冬に備えて形態が変わってきたのか。水苔のことはあまり詳しくないので、よくわからない……。
サラセニアの鉢の水苔も元気で、もう鉢から零れんばかり。写真には写っていないけれども、水苔だけでなく、サラセニアも元気がいい。

気懸かりなのは、建物の外壁工事があること。ペンキで壁に変な印がたくさん付けられていて、もうすっかり足場が見上げられて変な薄布で建物全体がすっぽり覆われた状態になっています。工事の日には室内に避難させる必要があるでしょう。長期間室内に入れていると、食虫植物は大抵弱って、運が悪いと枯れてしまうというのが今までの経験です。もう来年の春にはこの綺麗な水苔の緑やサラセニアの赤っぽい筒は見られなくなるのかも知れません。
2008-10-26 18:07:39
 EPwingとか電子ブック規格の電子辞書をずいぶん買った。この頃はオンラインで有料あるいは無料でさまざまな辞書が提供されているが、必ずしも自分の好みの辞書がそこにあるとは限らない。だから、いろいろな辞書のCDを買ってきた。
EPwingとか電子ブック規格の電子辞書をずいぶん買った。この頃はオンラインで有料あるいは無料でさまざまな辞書が提供されているが、必ずしも自分の好みの辞書がそこにあるとは限らない。だから、いろいろな辞書のCDを買ってきた。
複数のMacを使用していると、あるいはさらにLinuxも使っていると、いちいち辞書をハードディスクにコピーするのは面倒臭いし、ハードディスクが勿体ない。いくつもコピーするのは違法じゃないかという気もする。そこで、これをAppleのMobilemeに置いて、自分が起動したパソコンにiDiskをマウントして使えばいいではないか。自分しか使わないのだから、一度の何台もでアクセスすることはないので、利用規約に反していないのではないだろうか。実はそんなに気にしていないのだけど。
問題はiDiskが苛々するほど遅いことだ。辞書が遅いのには耐えられないだろう。でも試してみよう。
 私はMacではもっぱらJammingを使っている。「オプション→辞書の追加と削除」を開いて、iDisk上の辞書を指定すればいい。試してみると問題なく使えた。これは便利だ。Macは簡単だが、やはりLinuxでも使いたい。私が使っているのはubuntu 8.04だ。iDiskは前に書いた通りマウント自体は簡単である。ところが……
私はMacではもっぱらJammingを使っている。「オプション→辞書の追加と削除」を開いて、iDisk上の辞書を指定すればいい。試してみると問題なく使えた。これは便利だ。Macは簡単だが、やはりLinuxでも使いたい。私が使っているのはubuntu 8.04だ。iDiskは前に書いた通りマウント自体は簡単である。ところが……
UbuntuではもっぱらEBViewを使っている。これで辞書を設定するときにはPathがわからないと困るのだ。でも、どこにマウントされたのかわからないのだ。MacOSXの場合は/Volumesにあるのだが、Ubuntuでは? Gnomeデスクトップ(Nautilus)でネットワーク接続機能を使ってマウントすると実に簡単なのだが、どこにマウントされたのかわからないではないか。必死で探したが見つけられなかった。そこで、前に諦めたdavfs2を再度使うことにした。blog@browncat.org(Ubuntuからmobilemeのidiskを使うためのいくつかの方法のメモ)とか、あるシステム管理者の日常(WebDAVをマウント)を参考にしながら。
書いてあるとおりにすれば、簡単にマウントできる。今回は、ホームディレクトリにiDiskというフォルダを作って、そこにマウントした。これも前からわかっていることなのだけど、そうすると書き込み権眼がなくなるのだ。ファイルの書き換えとか新たなファイルの保存ができないではないか。先の方法を使うと普通の自分のファイルとして読み書きできるのに。でも、今回は辞書の設定だ。
「ツール→オプション→辞書検索」の設定でiDiskの辞書を指定したら、ちゃんと動いた。ああ、よかった。これで、ネットに繋がる環境であれば自分の辞書をどこからでも使用できる。ハードディスクにもいくつも辞書を保存しなくていい。
2008-10-26 13:08:45
![]() Box.netは1GBまで無料。フォルダを作って好きなようにファイルを保存できる。無料版「Lite」では、一つのファイルの上限が25MBなのがちょっと小さいかも。月7.95ドルで5GBに増える(一つのファイルの上限は1GBになる)。外部APIも用意されている。下の方にある微細な文字で記されているDeveloperというリンクから入ると詳細な説明が読める。これに気づくのに時間がかかってしまった。だから、最初はAPIがないどころか、詳しい説明もないじゃないかと思って、試していなかったのである。どうしてこんなに小さい字にするのだろう。老眼の人には使わせたくないのかな。まだ老眼になってなくてよかった。
Box.netは1GBまで無料。フォルダを作って好きなようにファイルを保存できる。無料版「Lite」では、一つのファイルの上限が25MBなのがちょっと小さいかも。月7.95ドルで5GBに増える(一つのファイルの上限は1GBになる)。外部APIも用意されている。下の方にある微細な文字で記されているDeveloperというリンクから入ると詳細な説明が読める。これに気づくのに時間がかかってしまった。だから、最初はAPIがないどころか、詳しい説明もないじゃないかと思って、試していなかったのである。どうしてこんなに小さい字にするのだろう。老眼の人には使わせたくないのかな。まだ老眼になってなくてよかった。
PDFの閲覧、写真の簡単な加工、Zoho.comのdocument/spreadsheet/presentationが直接利用できるのが便利だと思う。その他にも、多数の連携機能がある。もちろん、共有も可能。
APIは、REST、SOAP、XML-RPCなどが使えて、AS3、PHPやPythonの例が示されている。私が使えるPHPとPythonがあるのが嬉しい。認証のところはざっと読んだけれどもよくわからなかった。
もっといろいろ使い方が解ってきたら、有料版にアップグレードしたくなってしまうのではないかと恐れてしまうほど機能が充実しているような気がする。
Dell Partners with Box.net for New Inspiron Mini 9 Notebookという記事が気になる。私はInspiron Mini 9 を註文したのだ。なかなか来ないけど。どうやったら容量を増量できるんだろう。
2008-10-26 10:10:20
 Xdrive停止のニュースを読んで、再びオンラインストレージ探しに熱が入ってしまった昨日でした。
Xdrive停止のニュースを読んで、再びオンラインストレージ探しに熱が入ってしまった昨日でした。
MediaFireは画像、動画、音楽ファイル限定というような記事を読んだことがあって、覗いてもいなかったのですが、見てみたら、そういうのに便利だというだけで、他のファイルは駄目だとは書いていないような気がしてきました。ということで、試しに登録してみました。尤も、ここは登録しなくてもファイルをアップロードできるのです。だから、メールで送れないような大容量のファイルの受け渡しに利用するのにも便利だという評判のようです。
私はとりあえず個人用ファイルを置いてみたいので、登録することにしました。まあ、気分の問題です。
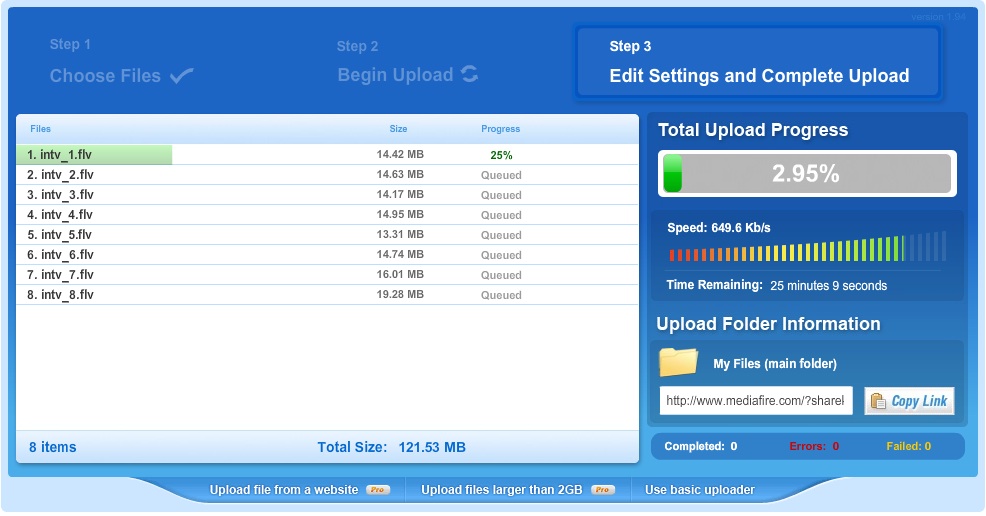
アップロードは、上のような画面で操作します。簡単です。公開(あるいは共有・受け渡し用)のURLがすぐに表示されます。埋め込み用URLも。動画ファイルを公開したい人なんかにへ便利でしょう。私はしませんが。非公開にしたいときは、private設定にすればいいようです。フォルダも自由に作れます。
太っ腹にも容量制限がないので、大きなファイルのバックアップに利用しようと考えています(でも、一つのファイルの大きさの上限はあって、無料版では100MB)。試しに小さなテキストファイルをアップしてみたら、問題なく保存されました。
有料のMediaProというのもあって、ファイルの大きさの上限が10GBになるとか、Direct/Hot linkが設定できるようになるとか、広告なしとか、Redundant backupsとか、そんなところが違うようです。
2008-10-25 18:31:57
 土曜日なのでパンを焼く。
土曜日なのでパンを焼く。
ロールパン用の卵の残りが冷凍してあるので、それを片付けようと思って、今日はロールパン。実はロールパンは私の好みよりかなり柔らかい。もっと重くて固いパンの方が好きなのだ。そこで、ちょっと気分を変えて、ライ麦を混ぜてみた。ライ麦入りロールパンである。あまり聞いたことないけれど、それは私が聞いたことがないだけなのか、一般的にそんなものは作らないのかはよく解らない(でも、今Googleで検索してみたら、それなりの数が出てきたので、そんなに変なことでもないようだ)。

ライ麦を入れるとベタつくので、小麦粉の分量を増やした方がいいようだ。というより水を減らせばいいということなのか。今回はライ麦を10%入れてみた。食べてみると、ライ麦の入ったバターロールとしかいいようにない味だった。不味くはない。でも、特別美味いわけでもない。かなり悲惨なパンを予想していたので、それよりは美味かった。私はいつも最悪の未来に備えているのだ。物事はたいていうまく行かないものだから。
明日もパンを焼こう。

2008-10-25 16:56:52
 昨夜、デルが8.9型Atomノート「Vostro A90」を発売するというITmediaの記事を読んで驚いた。いわゆるNetbookの製品をInspiron Mini 9を出してまだそんなに経っていないのに、もう出すのかと。
昨夜、デルが8.9型Atomノート「Vostro A90」を発売するというITmediaの記事を読んで驚いた。いわゆるNetbookの製品をInspiron Mini 9を出してまだそんなに経っていないのに、もう出すのかと。
いや、本当は前の機種を出した時期なんかに関心はないのだ。私が気になるのはInspiron Mini 9を註文した時期だ。一ヶ月以上前に註文したInspiron Mini 9がまだ来ないのである。私が欲しかったのはubuntu版なので、直販しかない。作業工程確認サイトのような者があるのだが、ずっと製造中である。どうなっているのか。9月下旬から製造開始だったはずなのに。
数日前にクレジットカードの請求書が来て驚いた。もうInspiron Mini 9の代金が請求されていたのだ。まだ発送もしていない製品の代金を私は支払わなければならないのか。でも、大らかな性格の私は特に苦情を訴えるつもりもないので、代金は近々支払われるだろう。でも、あまり楽しいことではない。
Dellはこんなものを作っている暇があったら、私が一ヶ月以上も前に註文したInspiron Mini 9を作った方がいいんじゃないか。
2008-10-25 16:18:49
 TechCrunch Japaneseの記事に「AOL、主要サービス三つの終了アナウンスを開始」と書いてあって、その三つの一つがXdriveだった。せっかく登録して、使い方を調べているところだったのに。夏には、AOLが売却先を探しているという記事を見たのだが、結局見つからなかったのか。
TechCrunch Japaneseの記事に「AOL、主要サービス三つの終了アナウンスを開始」と書いてあって、その三つの一つがXdriveだった。せっかく登録して、使い方を調べているところだったのに。夏には、AOLが売却先を探しているという記事を見たのだが、結局見つからなかったのか。
やれやれ、よさそうだと思ったのに。
今からでも買い手がついたりすることはないのかな。
2008-10-25 00:04:02
 とにかく速いFirefoxがあるという記事を読んだので、早速試してみた。Chromeが速いといっても、Mac版がなくて不愉快だった訳だが、これにはMac版もある。まだ所謂α版だけど。
とにかく速いFirefoxがあるという記事を読んだので、早速試してみた。Chromeが速いといっても、Mac版がなくて不愉快だった訳だが、これにはMac版もある。まだ所謂α版だけど。
ここからMac版をダウンロード。Firefox-3.1b2preというやつである。アプリケーション・フォルダにコピーするだけ。あとはダブルクリックで立ち上げる。確かに速い……ような気がする。アドオンに使えないのが多いので、まだ常用はできないかも知れないが、ただの閲覧ならほとんど問題ないのではなかろうか。実はubuntuのFirefox 3.0が不安定で困った状態になっている。すぐに反応しなくなってしまって、強制終了させざるを得なくなっているのである。macよりもubuntuで試してみようか。
今度はfirefox-3.1b2pre.en-US.linux-i686.tar.bz2をダウンロードして、展開。試用アプリケーションをいつも置くことにしているフォルダに入れて、./firefoxで立ち上げる。速い……ような気がする。いろいろアドオンは使えないのだけど。速くて安定しているではないか。でも、ubuntuでは終了ができない。その代わり、Firefox 3.0が安定化したような気がするのだけど、気のせいだろうか。
さっき Encyclopaedia Britannicaにログインしようとしたら、IDとパスワードを入力する小窓が途中で消えてしまうことを発見。そういう細かい問題にはいろいろ遭遇しそうだ。でも、今はMinefieldでこれを書いています。
2008-10-24 21:25:32
 偶然こんな記事[Impress, Gizmodo Japan]を見つけました。面白い……のか。私にはわかりません。私は銃を撃つのにそんなに関心がないし、目覚まし時計もあまり使わないから。
偶然こんな記事[Impress, Gizmodo Japan]を見つけました。面白い……のか。私にはわかりません。私は銃を撃つのにそんなに関心がないし、目覚まし時計もあまり使わないから。
普段目覚まし時計は使わない。だから、「朝、起きられなくて〜」なんていう言葉にまったく共感できないのだ。眠りが浅いのか、夜中に何度も目を覚まして時計を確認するから、目覚まし時計は要らない。私の願いは、朝起きることではなく、朝までぐっすり眠ることだ。
誰かに指示されるのも嫌だ。起こされる前に起きたくなる。それを利用して、依存するようになるのも嫌だ。人に命令されたり指示されたり指導されたり試されたりするのは嫌いだから。
以前、夜中に突然妻が「明日、○○に買い物に行くけど何か買ってきて欲しいものある?」と訊くので、「別にない」と答えたら、「何で答えるのよ! 眠っていたんじゃないの? 起きてたの?」と叫んだことがある。「起きていたんじゃなくて、起こされたんじゃないか。どうでもいい質問して起こさないでくれ」と文句を云ったのだが、気がつくと妻はもう眠っていて、私は不愉快な気持ちでなかなか眠れなかった。
我が家には機能する目覚まし時計がないので、私が目覚まし時計代わりになっている。「明日は6時に起こして」とか云い放って、妻や娘は寝てしまう。娘はしばらく前は自分の目覚まし時計を持っていてそれで起きようとしていたが、この頃は目覚まし時計の設定・管理よりも私に云う方が楽だと思ったのか、いつしか壊れた時計を捨てていた。
それでも、大事な用事のあるときは私でも目覚まし時計を使いたくなることがある。やはり体内時計だけに頼るのは心配である。目覚まし時計がないので、携帯電話の目覚まし時計機能でも使うかということになるのだが、設定方法などがよくわからなくて苦労する。あれは悪魔の機械だ。
私は時間に遅れるのが嫌なので、それはもう恐怖に近いくらいの感情なので、早起きして早めに準備して出かけることになる。不安なのだから仕方がない。大抵は約束の時間の2時間くらい前に着いて場所を確認して、暇を持てあまして本を読んだり書店で本を買ったりしているうちに時間に遅れそうになったりする。
「二時間前行動なんです、不安なので。だから、一日に仕事が二つ入ると、前の仕事に行けないんです」と云っていたのは鳥居みゆきだが、共通点がそんなに嬉しい人でもないかな。
2008-10-23 23:23:06
 Mac miniはもう製造終了ではないかという記事をいくつか見かけた[GIZMODO Japan, TechCrunch]。次に買うときはMac miniにしようかと思っていたのに。予想外の世界経済の混乱なんかで資金調達の予定が大幅に狂ってMac購入時期が遅れている間に、Mac miniが消えてしまうなんて。
Mac miniはもう製造終了ではないかという記事をいくつか見かけた[GIZMODO Japan, TechCrunch]。次に買うときはMac miniにしようかと思っていたのに。予想外の世界経済の混乱なんかで資金調達の予定が大幅に狂ってMac購入時期が遅れている間に、Mac miniが消えてしまうなんて。
オンラインストレージやらオンラインデスクトップなどをいろいろ物色して、手元に大量のファイルを蓄えなくていい方法を確立しつつあったのに。身軽になったデータ量ならMac miniでもいいと思っていたのだった。私は目に見えるところにコンピュータがあるのが嫌なので、実はあのMac miniを机の裏に貼り付けようという計画を密かに心の奥底で温めていた。外付けハードディスクとか、DVDドライブとかを貼り付けたことはある。今机の裏に張り付いているのはルータ兼Ethernet hubだけである。
今使っているPowerMac G5って結構邪魔なのだ。ああ、Mac miniが欲しかった。
こうなったら、MacBook + 外部モニタだろうか。あるいは、iMacだろうか。でも、iMacはモニタを二枚に出来ないんじゃなかったかな。私はたくさんモニタを使うのが好きなのだ。あ、Mac miniだとそれはできないのか。困ったな。
はやく世界経済が安定を取り戻してもらわなければ。Mac miniの在庫がなくなる前に。

2008-10-23 22:58:14
![]() 今日はADriveというのを見つけたので、使ってみた。Online Storageというやつである。まずはメールアドレスとパスワード、国名などで登録完了。50GBまで無料。管理画面が出てきて、アップロード、ダウンロードができる。フォルダを自由に作って保存できる。URLを指定して、保存することも。
今日はADriveというのを見つけたので、使ってみた。Online Storageというやつである。まずはメールアドレスとパスワード、国名などで登録完了。50GBまで無料。管理画面が出てきて、アップロード、ダウンロードができる。フォルダを自由に作って保存できる。URLを指定して、保存することも。
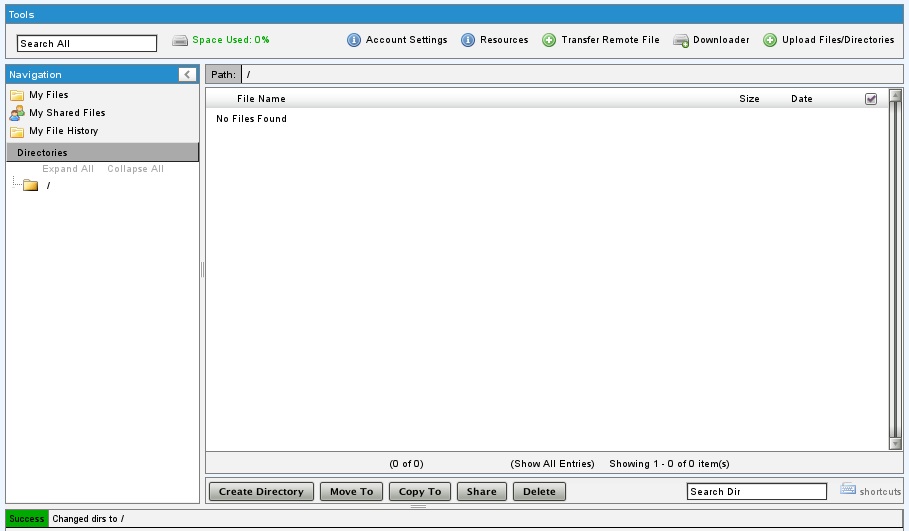
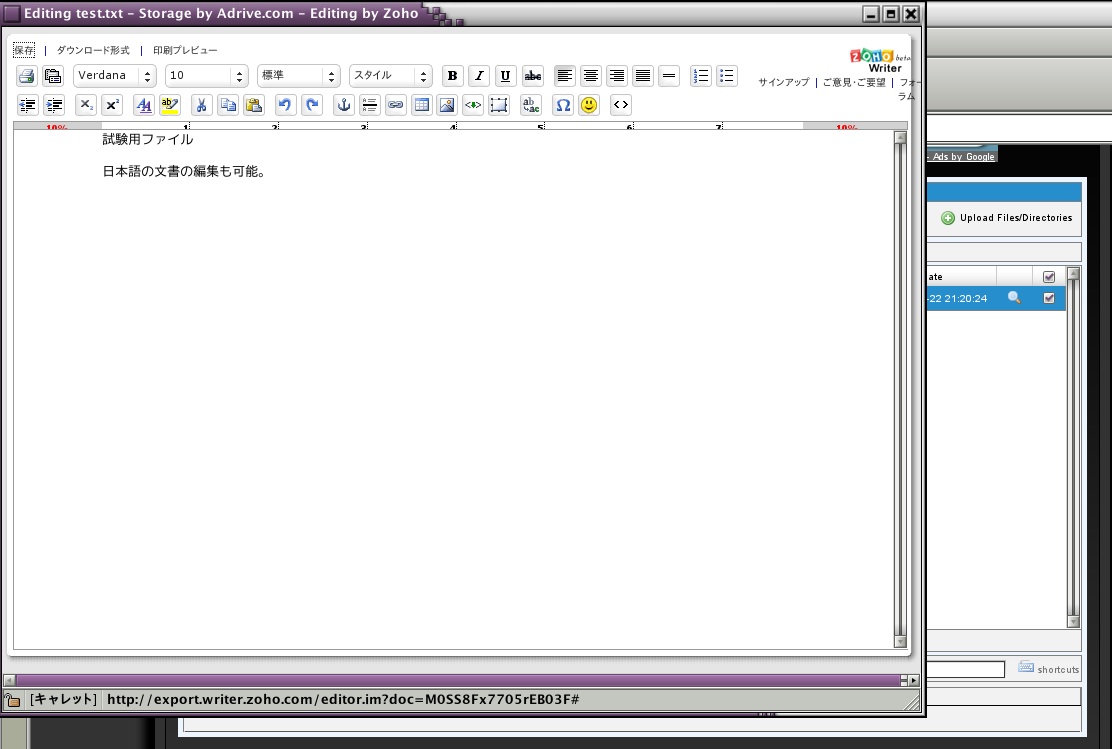
Zoho.comと連動していて、ワープロ文書の編集、表計算ファイルの編集などができる。日本語も書けるので安心。新たに文書を作ることはできないようだ。虫眼鏡のマークを押すと「Edit in Zoho」という項目が選べるようになる。これになかなか気づかなかったが、これは便利だ。
有料版にアップグレードすると、WebDavの利用などができるようになるという。ちょっと心惹かれるところ。
アップロードはかなり早い印象を受けたが、気持ちで比較しているだけで、ちゃんと測定したわけではない。ログアウトせずにウィンドウを閉じてしまうと、ほかのコンピュータからアクセスできなってちょっと悲しいことになる。
2008-10-22 22:57:28
 先日、保温鍋というものを買ったのは前に報告したとおり。二度ほど使ってみた。半信半疑で使ってみたのだが、宣伝文句に嘘偽りはなかった。確かに便利である。ガスの炎で熱する時間が大幅に短縮できるし、だから真夏に汗だくになって鍋の中を覗き込まなくていいし、うっかり忘れていて鍋の中身が黒こげになったりすることもない。
先日、保温鍋というものを買ったのは前に報告したとおり。二度ほど使ってみた。半信半疑で使ってみたのだが、宣伝文句に嘘偽りはなかった。確かに便利である。ガスの炎で熱する時間が大幅に短縮できるし、だから真夏に汗だくになって鍋の中を覗き込まなくていいし、うっかり忘れていて鍋の中身が黒こげになったりすることもない。
しかし、何か物足りない。
家族には好評である。私は5時間近く煮て軟骨が柔らかくなった鳥の手羽元でカレーを作るのだが、ガスの炎を使う時間は一時間もなかった。玉ねぎの形が崩れていなくて、しかし突くと簡単にばらばらになるくらい柔らかく、口に入れれば溶けるようだという。
しかし、何か物足りない。
玉ねぎの形が崩れないのはかき混ぜていないからだ。私は加熱しながら鍋を覗き込んでかき混ぜて観察し、内容物が徐々に変化していく様子を確認するのが好きだったのだ。加熱と攪拌は化学反応の基本である。それが好きで大学は理学部化学科へ進んだくらいだ。料理も楽しいのは加熱と攪拌である。だから、私は肉を長時間煮込む料理が好きである。
保温鍋を使うとまったく触れない。中を覗き込むことすらできない。誰も観察していない鍋の中で鶏の手羽元は果たして生きているのか死んでいるのかというシュレーディンガーの猫のような状態になってもう心配でたまらない(もちろん、シュレーディンガーの猫にはなりません、念のため)。でも、開けるとできあがっているのだ。量子論のように謎めいた鍋である。
加熱と攪拌。魔法使いの大鍋の扱いの基本である。ロード・ダンセイニの作品にA Narrow Escapeという作品があって(河出文庫『世界の涯の物語』に収録されている)、そこでも老魔法使いが大釜に怪しい材料を放り込んでぐつぐつと煮込んでかき回す。そして恐ろしい呪文を唱えるとロンドンの街が崩壊する……はずだったのだが、弟子が偽物の蟾蜍を持ってきたために効力が発揮されずにロンドンは九死に一生を得るという他愛もない話である。大釜は、加熱しながら熱心に攪拌しなければならない。保温大釜があれば魔法使いも楽だろうが、そんなことをしては強力な魔法は生まれない。加熱と攪拌から魔法は生まれるのである。加熱と攪拌が好きなので、将来は魔法使いになろうと子供の頃は決めていた。
保温鍋は何時間待っても中身を煮詰めることができない。いつも蒸発分を見込んで水分を入れているので、ずいぶん勝手が違う。その辺が最大の戸惑いである。それでも、いろいろと利点があるので、多分保温鍋を使い続けるだろう。買ってよかったのだろうと思う。
でも何か物足りない。こんなものを使っていては魔法使いにはなれないだろうし、もしかしたら、化学者にもなれないかも知れない。
2008-10-22 22:06:25
Amazon S3にPDFファイルを保存して、検索対象情報はローカルホストのMySQLで管理する、論文管理システムをPythonで作ってみたのだが、どうも文字コード関連のエラーが多発して甚だ不便だという話は昨日までに報告したとおりである。ならば、PHPで作ってみようというわけである。
問題は論文からの情報抽出とMySQLへの情報追加、そしてpdfファイルのAmazon S3へのアップロードである。最後のアップロードはPHPでどうやったらいいか解らない。そこで、それだけは今までどおりPythonに頼むことにしよう。PHPではこんなふうにした。やっていることは、Pythonの場合と同じ。
<?php
$con=mysql_connect("localhost","user","password");
mysql_select_db("paperdb",$con);
$pmidarray = array();
foreach (glob("*.pdf") as $pdffile) {
$pmid=ereg_replace("\.pdf","",$pdffile);
$sql="select pmid from pdfdata where pmid = '".$pmid."'";
$res=mysql_query($sql);
$num_row=mysql_num_rows($res);
if ($num_row == 0){
array_push($pmidarray,$pmid);
}
}
$ids = implode(",",$pmidarray);
$url = "http://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&id=".$ids."&retmode=xml&rettype=full";
$xml=simplexml_load_file($url);
foreach($xml->PubmedArticle as $item){
$id = $item->MedlineCitation->PMID;
$volume=$item->MedlineCitation->Article->Journal->JournalIssue->Volume;
if (empty($volume)){
echo $id." This paper has not been published yet.\n";
break;
}
$year=$item->MedlineCitation->Article->Journal->JournalIssue->PubDate->Year;
$title=$item->MedlineCitation->Article->ArticleTitle;
$pages=$item->MedlineCitation->Article->Pagination->MedlinePgn;
$abstract=$item->MedlineCitation->Article->Abstract->AbstractText;
$abstract=mysql_escape_string($abstract);
$aus=$item->MedlineCitation->Article->AuthorList->children();
$authors="";
foreach ($aus as $au){
$lastname=$au->LastName;
$initials=$au->Initials;
$authors=$authors.$lastname."_".$initials.", ";
}
$authors=ereg_replace(", $","",$authors);
$authors=mysql_escape_string($authors);
$journal=$item->MedlineCitation->MedlineJournalInfo->MedlineTA;
$cmnd = "pdftotext -enc UTF-8 -nopgbrk ".$pmid.".pdf -";
$fulltext = mysql_escape_string(shell_exec($cmnd));
$insert="insert into pdfdata (pmid,authors,title,journal_title,journal_vol,Journal_pages,year,abstract,fullcontent) values('".$id."','".$authors."','".$title."','".$journal."','".$volume."','".$pages."','".$year."','".$abstract."','".$fulltext."')";
mysql_query($insert);
echo $id."\n";
}
mysql_close($con);
passthru("python s3upload.py ".$ids);
?>
最後のs3upload.pyというのはこんなファイル。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import os
import sys
from boto.s3.connection import S3Connection
from boto.s3.key import Key
ids = sys.argv[1]
idlist = ids.split(',')
s3conn = S3Connection()
bucket = s3conn.get_bucket('pdffiles-pmid')
bucket.set_acl('private')
for id in idlist:
filename = id + ".pdf"
if bucket.lookup(filename) == None:
k = Key(bucket)
k.key = filename
k.set_contents_from_filename(filename)
# k.get_contents_to_filename("d" + filename)
PHPだと、pdftotextの出力も受け取りやすい。私は改めてPHPが好きになってきましたよ。
2008-10-21 21:56:29
昨日、pythonのスクリプトを書くのを忘れていました。さらにちょっと検討してみたので、今日の時点でのスクリプトを掲げておきます。流れは昨日書いたとおり。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import os
import MySQLdb
from urllib import urlopen
import xml.etree.ElementTree as ET
from boto.s3.connection import S3Connection
from boto.s3.key import Key
from types import *
s3conn = S3Connection()
bucket = s3conn.get_bucket('pdffiles-pmid')
bucket.set_acl('private')
filelist = os.listdir('./')
verbindung = MySQLdb.connect(host='localhost',user='tolleetlege',passwd='password',db='database')
cursor = verbindung.cursor()
idlist = []
for pdf_file in filelist:
if pdf_file.find('pdf') > 0:
pmid = pdf_file.replace(".pdf","")
sql = "select * from pdfdata where pmid = '" + pmid + "'"
cursor.execute(sql)
res = cursor.fetchall()
if len(res) == 0:
idlist.append(pmid)
else:
print pmid + ': This article already exixts in the database.\n ------'
url = 'http://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&id=' + ','.join(idlist) + '&retmode=xml&rettype=full'
xml = urlopen(url).read()
dom = ET.fromstring(xml)
for particle in dom.findall('PubmedArticle'):
pmid = particle.findtext('./MedlineCitation/PMID')
filename = pmid + '.pdf'
os.system("pdftotext -enc UTF-8 -nopgbrk " + filename)
fulltext = open((pmid + '.txt'),'r').read()
fulltext = MySQLdb.escape_string(fulltext)
journal = particle.findtext('./MedlineCitation/Article/Journal/ISOAbbreviation')
if type(journal) == NoneType:
journal = particle.findtext('./MedlineCitation/MedlineJournalInfo/MedlineTA')
journal = journal.replace('.','')
volume = particle.findtext('./MedlineCitation/Article/Journal/JournalIssue/Volume')
if type(volume) == NoneType:
print pmid + ': This article is in press.\n ------'
else:
pubyear = particle.findtext('./MedlineCitation/Article/Journal/JournalIssue/PubDate/Year')
pages = particle.findtext('./MedlineCitation/Article/Pagination/MedlinePgn')
title = particle.findtext('./MedlineCitation/Article/ArticleTitle')
abstract = particle.findtext('./MedlineCitation/Article/Abstract/AbstractText')
abstract = MySQLdb.escape_string(abstract)
authors = particle.findall('./MedlineCitation/Article/AuthorList/Author')
aulist = []
for author in authors:
aname = author.findtext('./LastName') + "_" + author.findtext('./Initials')
aulist.append(aname)
au = ', '.join(aulist)
print pmid, journal, "(", pubyear, ")", volume, ":", pages
print title
try:
isitems = "','".join([pmid,au,title,journal,volume,pages,pubyear,abstract,fulltext])
insert = "INSERT INTO pdfdata (pmid,authors,title,journal_title,journal_vol,journal_pages,year,abstract,fullcontent) VALUES ('" + isitems + "')"
cursor.execute(insert)
print 'Data have been uploaded.\n ------'
if bucket.lookup(filename) == None:
k = Key(bucket)
k.key = filename
k.set_contents_from_filename(filename)
k.get_contents_to_filename("d" + filename)
except UnicodeDecodeError:
print "UnicodeDecodeError\n ------"
verbindung.close()
os.system("rm *.txt")
pdftotext をいちいちテキストファイルで保存してから読み込むのは無駄なような気がして、標準出力にしたらそれをpythonが受け取ってくれるんじゃないかと思ったのだ。今日初めて知ったのだが、出力ファイルを" - "とすれば、標準出力になるのだという。PHPなら、
$text = shell_exec("pdftotext filename.pdf -")
echo $text
とすれば、ちゃんと表示されるのだが、pythonで同じように、
text = os.system("pdftotext filename.pd -")
とやっても、textに入っているのは 0 という数値である。なぜだ。コードエラーは相変わらず。もう解らないからいい。
2008-10-20 22:50:50
 よく「野菜しか食べないと云われても驚かない」と聞くので、あまり肉が大好きなようには見えないらしいが、肉ばかり食べている。もちろん、パンを焼いて食べたりもするけど。
よく「野菜しか食べないと云われても驚かない」と聞くので、あまり肉が大好きなようには見えないらしいが、肉ばかり食べている。もちろん、パンを焼いて食べたりもするけど。
魚は臭いから嫌いである。野菜は驢馬か兎になったような気がするので嫌いである。植物なら果物は好きだ。しかし、野菜も大事だと思っている。肉を美味く煮るためには玉ねぎやトマトが欠かせない。香辛料だって諸靴物由来だ。決して植物を憎んでいるわけではない。
子供の頃から肉が好きだったが、一時期、うまく食べられないことがあった。おそらく、幼稚園かどこかで、食べ物はよく嚙んで食べなさいとか云われたのだろう。よく嚙んでいると、繊維の固まりのような変な物体に変容するのである。肉が好きなのに、肉が食べられない。これはつらい。子供の私は毎日悩んだ(嘘)。
子供の頃、野生動物の番組とか、世界の未開の領域を旅するTV番組が好きだった。「すばらしい世界旅行」とか「野生の王国」である。あるとき、ありがちなアフリカものの映像を観ているときに気がついた。これだ、肉の食い方はこうなのだ! ライオンは肉をよく嚙まない。引きちぎるように嚙んで、がつがつと飲み込む。くちゃくちゃよく嚙むのは草食動物じゃないか。草のように肉を嚙んで美味いはずがない。幼い私は大発見に驚き喜び、感動に打ち震えた。もう明日から悩まなくていいのだ。肉汁を味わうように数回嚙んだら、あとは飲み込んでしまえばいいのだ。肉は喉ごしだ!
それ以来、私は肉をよく嚙まずに食べている。美味い。肉は本当に美味い。
娘もまた幼い頃、肉をよく嚙んで食べようとして、不味い繊維の固まりを作っていた。よく嚙むな、セレンゲティのライオンになった気持ちで肉を食え。ライオンはくちゃくちゃ嚙まない。草を食べる動物がよく嚙むのだ。牛なんか反芻してまで嚙む。牛になるな、ライオンになれ。そんなふうに教えたせいか、ちょっと変わった子に育ってしまった。もう「野生の王国」が放送されていなかったから、いい見本を見せられなかったのだ。
2008-10-20 22:05:56
![]() 何度も書いてきた、論文のpdfファイルをAmazon S3に保存する話。まず、すでにデータベースに登録されているかどかを確認して、なかったらpubmedサイトで情報を検索し、pdftotextで全文テキストを抽出して、得られた情報をMySQLのデータに保存すると同時に、pdfファイルはAmazon S3にアップロードするという流れになっている。
何度も書いてきた、論文のpdfファイルをAmazon S3に保存する話。まず、すでにデータベースに登録されているかどかを確認して、なかったらpubmedサイトで情報を検索し、pdftotextで全文テキストを抽出して、得られた情報をMySQLのデータに保存すると同時に、pdfファイルはAmazon S3にアップロードするという流れになっている。
pdftotextでのテキストの抽出で文字コードがどうも合わないので、utf-8で出力するように設定してみた。
/etc/xpdfrcの #textEncoding UTF-8をコメントアウトして、テキスト抽出の時には-encで文字コードを指定した。
pdftotext -enc UTF-8 xxx.pdf xxx.txt
というかんじ。これでいいのかな。よくわからない。pdfには、もとからpdf-8のものとasciiのものがあると思うのだが、これもまたよくわからない。はっきりいって、何もかもよくわからない。
保存したpdfファイルを、最後ダウンロードしてあたまにdを付けた名前で再保存することで、動作の確認をしているが、これは確認後は外した方がいい。
処理していくとときどきエラーが出る。
TypeError: sequence item 4: expected string, NoneType found
とか、
AttributeError: 'NoneType' object has no attribute 'replace'
というエラーである。NoneTypeって何だ。前にも遭遇して困ったことがあるような気がしないでもないが、よく思い出せない。それが、歳を取るということなのだ。とりあえず今日はここまで。エラーが出たものは自動的に失敗フォルダに移動するようにしようか。

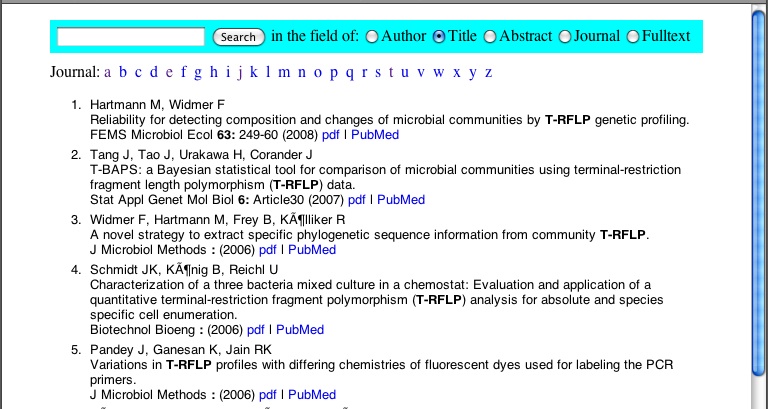
現在のところ、論文データ検索画面はこんなふうにできている。PHPで作ったページ。Journal名で一覧を出すこともできる。検索は、著者名、題名、要旨、全文検索ができる。題名にT-RFLPが含まれる論文を検索すると、下のように検索後が強調されて表示される。それで、関連情報を探したかったら、PubMedへのリンクをクリックすればいいし、論文を読みたいと思ったらpdfというリンクをクリックすればいい。Amazon S3にあるpdfファイルが呼び出されてくる。ちょっと遅いなあ。こんなちまちましたファイルには向いていないのか。まあ、いいか。
2008-10-19 17:29:14
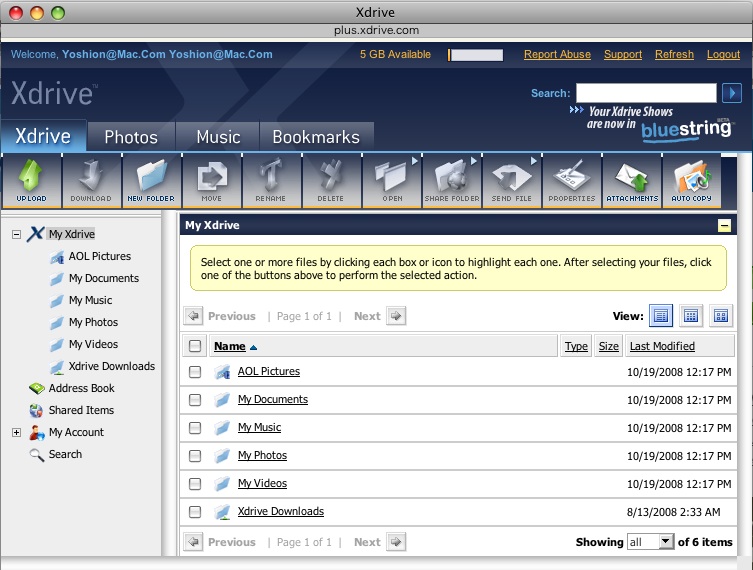
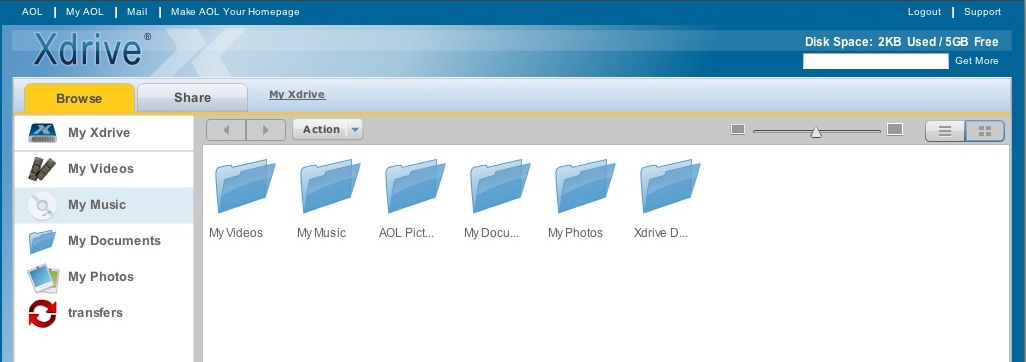
![]() Xdriveという同名のファイル共有サービスが日本にあるが、それとは関係ないAOL傘下のonline storageである。一度、広告料だけの運営が厳しくなって無料サービスを廃止して、企業向けの有料サービスだけになったこともあったようだ。と思ったら、2001年のニュースに「オンラインストレージ米国最大手の「Xdrive」が日本進出。ソフトバンクグループ会社と日本法人設立」という記事があるから、関係あるのか。よく解らないが、そんなことはどうでもいい。少なくとも私にとっては。
Xdriveという同名のファイル共有サービスが日本にあるが、それとは関係ないAOL傘下のonline storageである。一度、広告料だけの運営が厳しくなって無料サービスを廃止して、企業向けの有料サービスだけになったこともあったようだ。と思ったら、2001年のニュースに「オンラインストレージ米国最大手の「Xdrive」が日本進出。ソフトバンクグループ会社と日本法人設立」という記事があるから、関係あるのか。よく解らないが、そんなことはどうでもいい。少なくとも私にとっては。
登録にはAOLのメールアドレスが必要だという記事を読んだことがあったのだが、mac.comのメールアドレスを入力したら登録できた。なぜなのかはよく解らない。5GBまで無料。なかなか気前がいい。そのメールアドレスとパスワードの設定だけで登録完了。Xdrive Classicというのをクリックすると下のような画面が現れて、ファイルの操作ができる。
Xdrive Liteというのもあって、これをクリックすると、Adobe Airで動くアプリケーションがインストールされる。ブラウザと独立して、ファイル操作ができる。
さらに、Open XDriveという名のJSONベースのAPIが用意されている。Xdrive's Data Service Platform (XDSP)という名前で呼んでいるようだ。JSONをPythonで扱う方法を前に調べたことがあったが、あれは何とときだったか。ああ、「Google App EngineでGoogle AJAX Search APIを使う」ときだった。使い方はまだ全然解らない。これから少しずつ試してみよう。
2008-10-19 14:52:58
 Online storageってやつを物色する日曜日。外はいい天気ですが、私は太陽の光が嫌いだから外出なんかしませんね。気分はonline storageですから。
できるだけ大容量で、料金は安い方がいい。できれば無料でお願いします。Windowsだけ便利だったりすると不愉快。APIが利用できて、お仕着せの操作画面以外にもファイルを出し入れする手段があるといい。こんな我が儘が通じるところがいくつかあるようです。
Online storageってやつを物色する日曜日。外はいい天気ですが、私は太陽の光が嫌いだから外出なんかしませんね。気分はonline storageですから。
できるだけ大容量で、料金は安い方がいい。できれば無料でお願いします。Windowsだけ便利だったりすると不愉快。APIが利用できて、お仕着せの操作画面以外にもファイルを出し入れする手段があるといい。こんな我が儘が通じるところがいくつかあるようです。
まずは、Openomy。ユーザ名、パスワードなど決めて、メールアドレスを入力すれば、登録完了。下のような操作画面があって、ファイルをアップロードしたり検索したりできる。フォルダはなくて、タグで全てを管理する。複数のタグもつけられるし、もちろんタグの追加、変更も可能(そうでなかったら管理できない)。最初は画期的なonline storageと脚光を浴びたようだけど、今はそれほど目立っていないような感じである。もちろん、愛用者は多いんだろうと思う。サイトはすっきりしていて、好感が持てる。
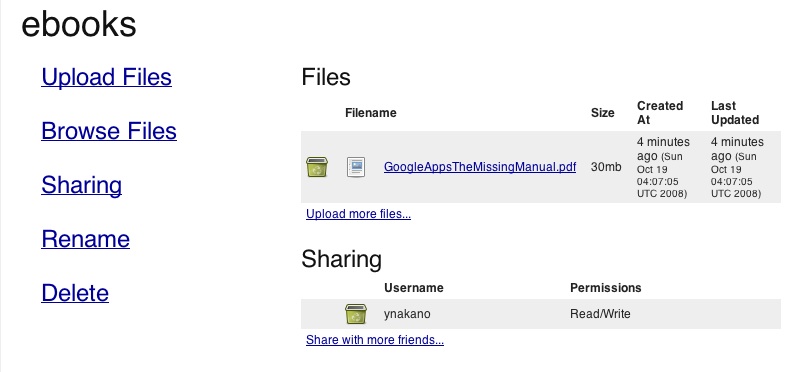
これは一つのファイルをebooksと、あと二つほどのタグを付けて保存し、ebooksのタグがついたファイルの一覧を表示させたところ。ここまでは、解りやすい。次はAPIである。
APIを使うにはIDが必要。Create An Appをクリックすると、Name, Description, Linkを入力する小窓が現れる。よくわからない。
In order to use our API, you must first create an application. This will provide you with an application key and private key. The application key is the equivalent of a username, and the private key is the equivalent of a password.と書いてあるから、まずはApplicationを作らなければならないようだが。
認証には、Amazon S3のときによく解らなくて困ったHMAC-SHA1を使ってSignatureを作ること、REST-based API だということ、 Ruby library があるということくらいしか、今は解らない。
よく解らないから、ちょっと他所も見てみよう。
2008-10-19 11:59:28
いつも牛頬肉を買う店で、ライ麦粉を見つけたので牛頬肉と一緒に買ってしまった。早速、ライ麦入りパンを焼いた。
前に作った基本の丸パンとほぼ同じ。ライ麦粉が10.5%入っている。どうして、10.5%なのかというと、堀井和子の1つの生地で作るパンに載っていたライ麦入りパンの組成がそうなっていたからだ。
ねばねば手について捏ねにくい。でも、できあがってみると、普通のパンだ。

左側がライ麦入り、右側がライ麦なし。食べてみるとそんなに変わらない。普通のパンじゃないかと思ったけれど、ライ麦ありなしを食べ比べてみると、それなりに違っているかも知れないと思える。
ライ麦というと、『ライ麦畑でつかまえて』とか『ポケットにライ麦を』を思い出すわけだけれども、パンの味とはとりあえず関係ない。
2008-10-18 22:26:38
 Encyclopaedia Britannicaは前はCDやDVDを買ったりしていたのだが、この頃、オンライン辞書にも慣れてきたので、利用料金切れで解約になり数年経っていたBritannica Online Encyclopediaにまた申し込んでみた。年間 $69.95である。以前は、画像や動画資料などは莫迦にしていたのだが、その利用価値もわかってきた(というか利用する機会が生じてきた)。日本語の辞書・百科事典などはJapanKnowledgeを利用している。実はあまり利用していないけど。これでは、登録料がもったいない。これからはもっと利用しよう。ただ、その料金がいくらだったかまったく思い出せないのが情けない。
Encyclopaedia Britannicaは前はCDやDVDを買ったりしていたのだが、この頃、オンライン辞書にも慣れてきたので、利用料金切れで解約になり数年経っていたBritannica Online Encyclopediaにまた申し込んでみた。年間 $69.95である。以前は、画像や動画資料などは莫迦にしていたのだが、その利用価値もわかってきた(というか利用する機会が生じてきた)。日本語の辞書・百科事典などはJapanKnowledgeを利用している。実はあまり利用していないけど。これでは、登録料がもったいない。これからはもっと利用しよう。ただ、その料金がいくらだったかまったく思い出せないのが情けない。
ちょっとだけ心が動いたのがOxford English Dictionaryである。年間195ポンド。何年も前に300ドルほどでCDを買ったことがある。それと同じくらい高い。でも、このところの円高で心が揺らいでしまったのだ。この際、思い切ってクリックしてしまおうか。購入ボタンの上で人差し指がひくひくと震えた。が、我慢した。私もたまには我慢ということができるようになったのだ。
どんどん身軽になっていきたいと思うと同時に、辞書類は手元にあるとそれだけで嬉しいものなので、そこはかとなく寂しい気分になってしまう。ときどきは分厚い辞書のページの間に鼻を突っ込んで、紙とインクの匂いを胸一杯に吸い込みたいものである。
2008-10-18 17:51:51
 冷蔵庫を開けたら柿があった。私は柿が大好きである。固い柿が好きだ。嚙むとかりこり音がするくらいが好きだ。その柿は、何となく色合いが柔らかいというか明るいというか、私が好きな柿とはちょっと違う感じがした。袋の字を読んだら、渋抜きした柿だと書いてあった。
冷蔵庫を開けたら柿があった。私は柿が大好きである。固い柿が好きだ。嚙むとかりこり音がするくらいが好きだ。その柿は、何となく色合いが柔らかいというか明るいというか、私が好きな柿とはちょっと違う感じがした。袋の字を読んだら、渋抜きした柿だと書いてあった。
私は渋抜きした柿が大嫌いだ。
渋抜きした柿って、アル中のにおいを漂わせていないか? ときどき電車の中なんかで遭遇してしまうともう車両を変えずには本を読み続けられないような、アル中のにおい。アル中なんて云うと怒る人もいるかも知れない。アルコール依存症とかね。でも、実態に違いはない。
渋柿の渋抜きにアルコールを使うから、そんなにおいがするのだろう。ときどき渋柿と焼酎がセットで売られていたりするらしい。まるで、アル中の柿を食っているような気分になるのだ、私は。酒そのもののにおいとは微妙に異なっていると思う。あの、アル中独特のにおい。
渋柿の渋抜きには、アルコールを使う他に、二酸化炭素を使う方法もあるらしい。というより、この頃は二酸化炭素による渋抜きの方が多いという記事もある。ドライアイスの欠片と一緒に袋に入れて密封しておくと、渋が抜けるとか。それならアル中臭い柿にならないんだろうか。今度、試してみようか。二酸化炭素による渋抜き。
思い切って、冷蔵庫の柿を食べてみた。アル中の柿ではなかった……
2008-10-18 16:24:07
![]() pdf論文ファイルデータベースの続きですが、最後にpdfファイルからテキストを抽出して全文検索ができるように設定しておきたいところ。pyPdfというのが
あるっていうので、これを試してみることにした。ubuntuにはpdftoolsというパッケージがあるが、よくわからなかったのだった。
Recipe 511465: Pure Python PDF to text converterを参考にやってみたのだが……。しかし、妙にスペースがなくなって詰まった文字列が出力されてしまった。単語間のスペースが消えてしまうことが多いのである。もちろん、# Collapse whitespaceの行を外してみたりもしたのだけど。どうしたらいいのか解らないので、結局xpdfのpdftotextを使うことにした。このXPDFというのは本当に便利だ。MacOSXでも、ビューア以外は使える。さて、
pdf論文ファイルデータベースの続きですが、最後にpdfファイルからテキストを抽出して全文検索ができるように設定しておきたいところ。pyPdfというのが
あるっていうので、これを試してみることにした。ubuntuにはpdftoolsというパッケージがあるが、よくわからなかったのだった。
Recipe 511465: Pure Python PDF to text converterを参考にやってみたのだが……。しかし、妙にスペースがなくなって詰まった文字列が出力されてしまった。単語間のスペースが消えてしまうことが多いのである。もちろん、# Collapse whitespaceの行を外してみたりもしたのだけど。どうしたらいいのか解らないので、結局xpdfのpdftotextを使うことにした。このXPDFというのは本当に便利だ。MacOSXでも、ビューア以外は使える。さて、
#!/usr/bin/python
# -*- coding: utf-8 -*-
import os
filelist = os.listdir('./')
idlist = []
for pdf_file in filelist:
if pdf_file.find('pdf') > 0:
pmid = pdf_file.replace(".pdf","")
idlist.append(pmid)
for id in idlist:
cmd = "pdftotext -nopgbrk " + id + ".pdf"
os.system(cmd)
txt = open((id + '.txt'),'r').read()
print txt
print "-----------------------"
os.system("rm *.txt")
こんなふうにしてみた。os.system("command")で外部プログラムの実行ということで処理した。pdfという拡張子を外したり付けたり無駄なことをしているように見えると思うが、これは昨日からの作業の流れでこうなっているだけ。もちろん、テキスト抽出だけだったらこんなことをする必要はない。pdftotextはxyz.pdfというもので、ファイルから文字列を抽出するとxyz.txtというファイルに保存する。標準出力にする方法が解らなかったので、一旦txtファイルに保存してから、それを読み、作業後に削除することにした。削除もos.system("rm *.txt")で実行。
これでいいのかな。一応、pmidをファイル名としたpdfファイルから、掲載誌、著者、題名、発表年、要旨、全文テキストなど、必要な情報が得られたので、こいつをMySQLデータとして保存すると同時に、Amazon S3にpdfファイルを保存すれば目的は達成できる。少なくとも私の目的は。
2008-10-18 15:22:01

昨日「告別式」の方を予約註文したばかりだったのですが、同じ2009年1月21日発売予定で「みみずひめ」の予約註文も受付が始まりました。同日発売とは! 何枚も註文しなくてよかった。両方で6000円なので、5枚ずつかったら六万円だ。いや、そんなに買わないけど。
今日、最初に気づいたときには、Amazon.co.jpのDVD部門で250位くらいだったのが、見る間に順位があがって、もう86位になっている。誰が買うだろう。私はもう註文しましたが。
この蚯蚓のDVDの噂は、撮影現場の近所の人のブログでたまたま言及されていたのがきっかけで、鳥居ンフルエンザ患者たちが「ミミズ? 鳥居みゆきはミミズだったのか!」と大騒ぎした(嘘)事件から広まったものでした。その撮影には鳥居みゆきは来ていなくて、蚯蚓だけが来ていたようです。
2008-10-17 23:28:00
 本当はAmazon S3にデータをアップロードするスクリプトの続きなのだけど、ちょっと手間取ってしまったので、途中まで。PubMedをpmidで検索して、論文情報の掲載誌、発表年、著者、題名、要旨などの情報を得て、それをPythonで処理する手順である。これができないと、データの整理ができないのだ。
本当はAmazon S3にデータをアップロードするスクリプトの続きなのだけど、ちょっと手間取ってしまったので、途中まで。PubMedをpmidで検索して、論文情報の掲載誌、発表年、著者、題名、要旨などの情報を得て、それをPythonで処理する手順である。これができないと、データの整理ができないのだ。
またもやElementTreeで戸惑う。面倒臭いなあ、ElementTreeは。とにかく、あるフォルダにpmidをファイル名とするpdfファイルを入れておいて、それをまとめて上記の論文情報をPubMedに問い合わせて取得するというところまで。明日は、全文テキストの書き出しと、Amazon S3へのアップロードをしたい。スクリプトは以下の通り。
#!/usr/bin/python
# -*- coding: utf-8 -*-
import os
from urllib import urlopen
import xml.etree.ElementTree as ET
filelist = os.listdir('./')
idlist = []
for pdf_file in filelist:
if pdf_file.find('pdf') > 0:
pmid = pdf_file.replace(".pdf","")
idlist.append(pmid)
url = 'http://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&id=' + ','.join(idlist) + '&retmode=xml&rettype=full'
xml = urlopen(url).read()
dom = ET.fromstring(xml)
for particle in dom.findall('PubmedArticle'):
print particle.findtext('./MedlineCitation/PMID')
journal = particle.findtext('./MedlineCitation/Article/Journal/ISOAbbreviation')
journal = journal.replace('.','')
volume = particle.findtext('./MedlineCitation/Article/Journal/JournalIssue/Volume')
pubyear = particle.findtext('./MedlineCitation/Article/Journal/JournalIssue/PubDate/Year')
pages = particle.findtext('./MedlineCitation/Article/Pagination/MedlinePgn')
title = particle.findtext('./MedlineCitation/Article/ArticleTitle')
abstract = particle.findtext('./MedlineCitation/Article/Abstract/AbstractText')
authors = particle.findall('./MedlineCitation/Article/AuthorList/Author')
aulist = []
for author in authors:
aname = author.findtext('./LastName') + "_" + author.findtext('./Initials')
aulist.append(aname)
print journal, "(", pubyear, ")", volume, ":", pages
print ', '.join(aulist)
print title
掲載のために一部省略している部分があります。
2008-10-17 22:40:15
今年7月の単独ライブの収録を中心とした鳥居みゆきのDVD『故 鳥居みゆき告別式 ~狂宴封鎖的世界~
』の予約註文が始まりました。来年1月21日発売予定となっています。当然のことながら、早速註文しました。
観に行った人たちのほとんどは、夏の暑い時期だというのに律儀にも喪服で参加したそうです。せめて蟹の季節にやればいいのに。
ああ、一枚だけで註文してしまった! 一枚だとメール便で配達されるので、到着が一日ほど遅れるのだ。ああ、25枚くらい註文して宅配便で配達されるようにすればよかった。大失敗だ。
一月に、鳥居みゆき主演の蚯蚓の映画のDVDが発売されるという話もあるのですが、これとは別に同じ月にもう一枚出るのでしょうか。
2008-10-16 22:53:01
![]() ファイルをダウンロードするために、REST requestで認証する方法はhttp://docs.amazonwebservices.com/AmazonS3/2006-03-01/index.html?RESTAuthentication.htmlに書いてある。
ファイルをダウンロードするために、REST requestで認証する方法はhttp://docs.amazonwebservices.com/AmazonS3/2006-03-01/index.html?RESTAuthentication.htmlに書いてある。
http://s3.amazonaws.com/(bucket)/(item)?AWSAccessKeyId=xxxxxx&Expires=0000000&Signature=yyyyyyyy
というように、ファイル名で決められるurlにAWSAccessKeyId、Expires、Signatureの3項目があればいいようだ。
最初のIDは自分のAWSAccessKeyIdだということは解る。有効期限は今から何分(何時間、何か月……)後までと自分で設定すればいいらしい。PHPでtimestampを使えば簡単に得られる。解らないのが、signatureである。全然解らないので、誰かが書いた例を見つけてきた。http://developer.amazonwebservices.com/connect/thread.jspa?messageID=82680に載っていたもの。
$accessKey = "<ACCESS KEY>";
$secretKey = "<SECRET KEY>";
$bucket = "<BUCKET>";
$item = "<OBJECT>";
$timestamp = strtotime("+3 days");
$strtosign = "GET\n\n\n$timestamp\n/$bucket/$item";
$signature = urlencode(base64_encode(hash_hmac("sha1", utf8_encode($strtosign), $secretKey, true)));
$url = " http://s3.amazonaws.com/$bucket/$item?\\
AWSAccessKeyId=$accessKey&Expires=$timestamp&Signature=$signature";
print "<a href='$url'>$url</a>";
全然解らないけれども、この通りにやればurlができた。これを、
function s3uri($pmid)
{
$accessKey = "xxxxxxxxxxx";
$secretKey = "xxxxxxxxxxxxxxxxxxxxxxx";
$bucket = "pdffiles-pmid";
$item = $pmid.".pdf";
$timestamp = strtotime("+10 minutes");
$strtosign = "GET\n\n\n$timestamp\n/$bucket/$item";
$signature = urlencode(base64_encode(hash_hmac("sha1", utf8_encode($strtosign), $secretKey, true)));
$url = " http://s3.amazonaws.com/$bucket/$item?\\
AWSAccessKeyId=$accessKey&Expires=$timestamp&Signature=$signature";
return $url;
}
というようにユーザ関数として設定して、urlを作成するのに使った。ちなみにここで、$pmidはPubMedのIDで、ここに登録されている論文一つ一つに付されている、固有の番号である。自分が持っている論文のpdfファイルをこの番号で管理すると何かと便利で、これで、論文の要旨をPubMedから取得したり、検索したりできる。pdfは自由に配布されているものは、わざわざ自分で保存する必要はないのだが、そうでないものも多いので、やはり自分で持っておきたい。というのは、例えば自分の所属している組織の図書館がとの学術雑誌の契約を解約してしまったりするとファイルを読めなくなってしまうのだ。そういう場合に備えてである。だから、これを世間に公表してしまって皆がダウンロードできるようにしてしまってはならないのである。認証をきちんとして、自分だけが利用できるようにしておかなければならない。
わかりにくい説明で申し訳ないが、そういうことなのだ。
ここまでで、ファイルを読み出せるようになったところである。次に自分のファイルをpdfファイルを除く情報は手元のコンピュータのMySQLにデータを保存して、pdf本体だけはamazon s3に保存するというスクリプトを書くのはまた明日以降にしよう。
2008-10-15 22:45:22
![]() 認証しながらリンク先のpdfファイルを開くときのやり方がもう少しで解りそうだけど、時間がなくてできなかった。ということで、今日はファイルがちゃんと保存されているかどうかと、費用の確認。
認証しながらリンク先のpdfファイルを開くときのやり方がもう少しで解りそうだけど、時間がなくてできなかった。ということで、今日はファイルがちゃんと保存されているかどうかと、費用の確認。
ログインしてアカウントを見るだけだけど。
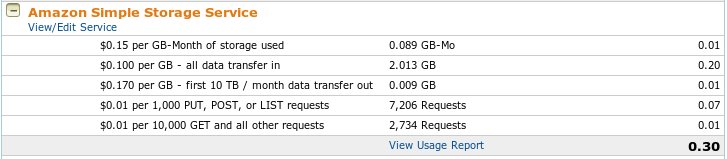
7200回のリクエストってなにだろう。よく解らないけど、2700くらいのファイルを保存するのに、8セントかかったということだろうか。2.013GBなので、11月からは毎月15セントの料金がファイルの保存にかかる。値下げされてよかった。先日、関係ないなんて書いたけれども、関係あったようだ。
ということで今日はこれだけ。
2008-10-15 22:04:44
噂だけでどうせでないだろうと思っていた13インチの銀色MacBookが出てしまいました。先日、DellのInspiron Mini 9を註文したばかりですよ。とても買えません。まだ、Inspiron Mini 9だって届いていないのに(遅いなあ)。新しいMacBookは1000ドルMacだという噂があったんですが、1000ドルになったのは、白のMacBookの方でした。銀は15万円です。
と思ったら、こんな記事を見つけました。デル Inspiron Mini 9でOS Xを起動、Macミニノート化。やりませんけどね、私は。
今晩、夢に出てきそうです、MacBook。女神が水から出てきて「あなたが落とした13インチMacBookは、銀のMacBookですか、白のMacBookですか」と問われたらどうしよう。
2008-10-14 22:42:06
![]() Pythonを使って、Amazon S3のデータを読み出す、あるいは保存する方法を調べてみた。あまり迷うことなく、botoを使うことにした。傀儡師の館.Pythonの記事を参考にしながら。
Pythonを使って、Amazon S3のデータを読み出す、あるいは保存する方法を調べてみた。あまり迷うことなく、botoを使うことにした。傀儡師の館.Pythonの記事を参考にしながら。
ダウンロードして、展開。sudo python setup.py installでインストール。ubuntuの場合は、packageがあるから、Synapticなどを利用してインストール。
.bash_profileなどに、
export AWS_ACCESS_KEY_ID=アクセスキー export AWS_SECRET_ACCESS_KEY=秘密鍵と書いておく。ubuntuの場合は、.profileか。そうすると、いちいちスクリプトで二つのIDを書き込まなくてもいいというので。
testsフォルダに入っているtest.pyを使って確認。
python test.py -t s3 --- running S3Connection tests --- --- tests completed --- . ----------------------------------------------------------- Ran 1 test in 9.836s OKとなる。ただし、ubuntuの場合は、そのままこのテストを実行しようとしても、 ImportError: No module named tests.test_sqsconnection というエラーが出てしまうので使えない。
さて、ここからPythonで試してみることにする。まずは、pdffiles-pmidというbucketに入っている1558312.pdfというファイルをダウンロードして、1558312b.pdfというファイル名で保存するスクリプトを書いてみる。
#!/usr/bin/python
# -*- coding: utf-8 -*-
from boto.s3.connection import S3Connection
from boto.s3.key import Key
conn = S3Connection()
bucket = conn.get_bucket('pdffiles-pmid')
bucket.set_acl('private')
if bucket.lookup('15583162.pdf') != None:
k = Key(bucket)
k.key = '15583162.pdf'
k.get_contents_to_filename('15583162b.pdf')
できた(MacOSXでもubuntuでも)。これで、何をやろうとしているのかは、また後で。少しだけ書くと、論文のPDFファイルの管理である。今日は、3000ほどあるpdfファイルをAmazon S3へとコピーした。ここを書庫として、いつでもどこからでも、論文のファイルを読み出そうという計画である。ファイル容量は合計で多分2GBくらいだと思う。
2008-10-14 21:27:10
 今日はこの本を参考に、基本となる丸パンを焼いてみた。強力粉(190 g)、ドライイースト(小さじ 3/4程度)、砂糖(小さじ1)、塩(小さじ 1/2)、ぬるま湯(125 ml)を混ぜて、捏ねる。十分くらい捏ねたら、30度で50分発酵させた。それから、生地をまとめて、9等分。丸めてから、十数分寝かせた。その後、少し丸め直して粉をまぶしてから40度で50分くらい発酵させた。最後に200度で十分焼いた。
今日はこの本を参考に、基本となる丸パンを焼いてみた。強力粉(190 g)、ドライイースト(小さじ 3/4程度)、砂糖(小さじ1)、塩(小さじ 1/2)、ぬるま湯(125 ml)を混ぜて、捏ねる。十分くらい捏ねたら、30度で50分発酵させた。それから、生地をまとめて、9等分。丸めてから、十数分寝かせた。その後、少し丸め直して粉をまぶしてから40度で50分くらい発酵させた。最後に200度で十分焼いた。
あまり膨らまずに、団子のようなパンになってしまった。二次発酵を50分でやめずに、もっと膨らむまで続けた方がよかったのか。次回はその辺りを考慮してみよう。本には二次発酵の時間は書いてなくて、2倍程度に膨らむまでと書いてあったのだ。「切り口が表面に出ないように下に回しながら丸めるのがこつ」と書いてある意味が、できあがってから理解できた。いきなり上手にできるほど、世の中甘くはないのだ。

私はふわふわしたパンよりも、少し重いくらいのパンが好きなので、昨日のバターロールよりこちらの方がいい。
パンは漢字で書くと麵麭となる。好きな字なのだが、あまり通じそうにないので片仮名で書いている。

2008-10-13 13:53:54
二日続けてパンを焼いたら筋肉痛になった。情けない。パンを焼く前に、少し体力をつけた方がいいんだろうか。数週間トレーニングしてから、万全の体調で臨むのがいいのだろうか。などと心にもないことを書いてみた。私は運動が大嫌いだ。そんなことはしない。躰を鍛えてからでなければパンを作ってはならないという法律が出来たら私は潔くパン作りを諦めよう。そんなことあるわけないけど。
前回に引き続いて基本のバターロール。最後に生地を巻くときにシナモンシュガーなどまぶしてみる。パンを作っている間に、紀伊國屋書店から、本が届いた。堀井和子『堀井和子の1つの生地で作るパン』(1380円+税/文化出版局)[amazon.co.jp,
bk1,
楽天,
紀伊國屋書店,
Yahoo! Books]と『BAGLE&BAGLEオリジナル・レシピ集』(1300円+税/PARCOエンタテインメント事業局)[amazon.co.jp,
bk1,
楽天,
紀伊國屋書店,
Yahoo! Books]である。ベーグルは本当に湯で茹でるのかと軽く驚きながら、基本的なバターロールを作る。蜂蜜入りの湯を使うのはなぜだ。先日買った蜂蜜は勿体なくて使えないなあ。ベーグル用の安い蜂蜜を買わなければならないのか。どうして、蜂蜜入り? 解らない。Wikipediaによると、蜂蜜入りの湯を使うのは北米で広まったモントリオール形式のものだと読めるが、そうなんだろうか。
サンアントニオに二年間住んでいたときは、ベーグルをよく買った。それでサンドウィッチを作って弁当として仕事に行った。今は近所の店にベーグルは売っていない。自分で作れるようになったらいいなと思っている。

できあがったパンは、心配したほどシナモンの香りが強くなく、ちょうどいい感じ。巻き方が下手だと娘に指摘される。できたてよりも、冷えてから食べた方が美味かった。何でもできたてが美味いとは限らないのか。次は、今日届いた本を参考にして、焼いてみよう。
2008-10-13 11:46:20
![]() 昨日は気がつかなかったのだけど、Amazon S3にファイルをアップロードしたりダウンロードしたりするのは、H3Hubが使いやすそう。Bucketを作るのはどうしたらいいんだと戸惑ったが、「新規フォルダ」というのがそれだった。これは使いやすい。MacOSXでしか使えないけど。使いもしないbucketを作ってみたり、ファイルをアップロードしてみたり。無料じゃないのに。
昨日は気がつかなかったのだけど、Amazon S3にファイルをアップロードしたりダウンロードしたりするのは、H3Hubが使いやすそう。Bucketを作るのはどうしたらいいんだと戸惑ったが、「新規フォルダ」というのがそれだった。これは使いやすい。MacOSXでしか使えないけど。使いもしないbucketを作ってみたり、ファイルをアップロードしてみたり。無料じゃないのに。
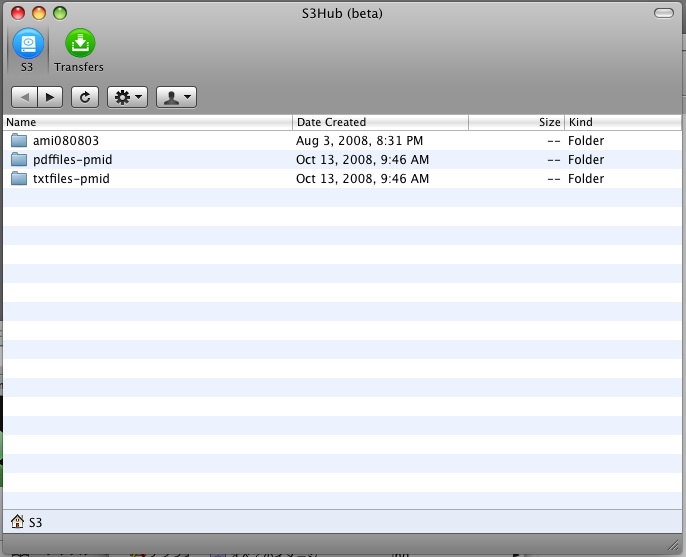
Amazon S3は私が思っていた以上にいろいろなことに利用できるものらしい。これから少しずつ使い方を考えていこう。
2008-10-13 11:41:11

イナゴである。蝗の季節である。子供の頃、田圃の中に忽然と出現する新興住宅地に住んでいた。周囲は田なので、秋には蝗がたくさん発生した。隣の家の人が、蝗好きだったようで、秋になると、農薬散布の前に蝗をたくさん捕ってきて佃煮だか甘露煮だかにしていた。大量に作ってしまうと自分の家では食べきれなくて、近所にお裾分けということになる。そんなわけで、ときどき我が家にも蝗が食卓に出現した。
私の家族は特に蝗が好きだったわけでもなく、もらってしまったから少し食べようかと、些か困惑気味に食卓に登場するのである。あれは受け付けない人は、どうにも無理だろう。ちぎれた脚が散らばっている様子は、まるでBlattella germanicaの脚そっくりである。詳しい人が見れば違いは一目瞭然なのかも知れないが、素人目には区別がつかない。でも、私は平気である。蝗だと思えば、何ともない。蝗なのだから。その中に数本Blattella germanicaの脚が混ざっているんじゃないかなんてことは考えない。考え始めるとだんだんその姿がBlattella germanicaにしか見えなくなってくる。もう口の中であれがもぞもぞ動き出すんじゃないか、胃の中で生き返って動き出すんじゃないかという想像が頭の中に満ちてきてしまうから。だから、考えない。黙って食べる。でも、気がつくと、黒くててかてかしたBlattella germanicaが頭の中を縦横無尽に走り回っている。頭を掻きむしって叫び出したくなってくる。
それでも、何食わぬ顔をして食う。それがなめられない食事のマナーというものである。
2008-10-13 08:15:58
 パンを焼いているうちに、鍋が欲しくなった。肉を料理するとき、煮込むことが多い。牛頬肉なんか買っているから、どうしてもそうなる。年中煮込んでいる。つらいのは夏だ。真夏に何時間も煮ていると、部屋の温度があがる。暑い、暑すぎる。
パンを焼いているうちに、鍋が欲しくなった。肉を料理するとき、煮込むことが多い。牛頬肉なんか買っているから、どうしてもそうなる。年中煮込んでいる。つらいのは夏だ。真夏に何時間も煮ていると、部屋の温度があがる。暑い、暑すぎる。
それでも煮込む。肉を煮込む。それしか作れないから。
圧力鍋がいいよと教えてくれた人がいた。調理時間が短縮されるから。保温鍋がいいよと教えてくれた人がいた。火を使う時間が短いから。
圧力鍋は実はもう持っている。我が家の圧力鍋は大きくて重い。だからといって、小さい圧力鍋を買う気にもならない。ならば保温鍋か……と数年考え続けた。昨日、ようやく結論を出した。保温鍋を買おう。
燃料の高騰、地球温暖化の問題、世界金融危機(これは関係ないけど)などの状況を勘案して、保温鍋の購入を決定した次第である。TIGER 保温調理鍋 (真空ステンレス) NFA-B300XSをAmazon.co.jpに註文した。8000円もした。本を買うときにはあまり8000円にくよくよしないのだが、鍋一つでこんなに躊躇うのはなぜだろう。
本はいくら買っても腹は満たされない。しかし、鍋を買えば調理ができて、家族がひもじい思いをせずに済むのだ。もっと堂々と買っていいはずだ。人はパンのみで生きるのではないと云うではないか。あ、逆だ。
というわけで、鍋が届くのを心待ちにしながらパンを焼く休日である。
2008-10-12 18:04:31
![]() Amazon S3が値下げされたというので、もっと活用しようと思った瞬間に、ログイン方法やら何やら、すっかり忘れていることに気がついた。
Amazon S3が値下げされたというので、もっと活用しようと思った瞬間に、ログイン方法やら何やら、すっかり忘れていることに気がついた。
価格は:
Storage — Current Pricing (thru October 31st)
$0.15 per GB-Month of storage used
Storage — New Pricing (effective November 1st)
$0.150 per GB – first 50 TB / month of storage used
よく見たら、50TB以下の場合は変わらないということじゃないか。私がそんなに使うわけはないから、全然変わっていないということだ。でも、これを機会にもっと使おう。そう決めてしまったのだから。まずは、IDなど思い出さなければならない。登録情報の確認するために、本を買うときのメールアドレスとパスワードでAWSの登録情報サイトへ入る。
Access Identifiers というページで、Access Key IDとSecret Access Keyを確認する。S3では使わないけれども、EC2で必要なX.509 Certificateは、このページの一番下で確認できる。
Amazon S3 Firefox Organizer (S3Fox)を使ってみる。具体的な説明はgihyo.jpの記事に詳しいので、それを参照すれば誰でもできると思う。
もう一つ、こちらはMacOSXでしか使えないが、Cyberduckというのもある。もともとftpとかsftpのためのものなのだが、Amazon S3にも対応しているのだ。
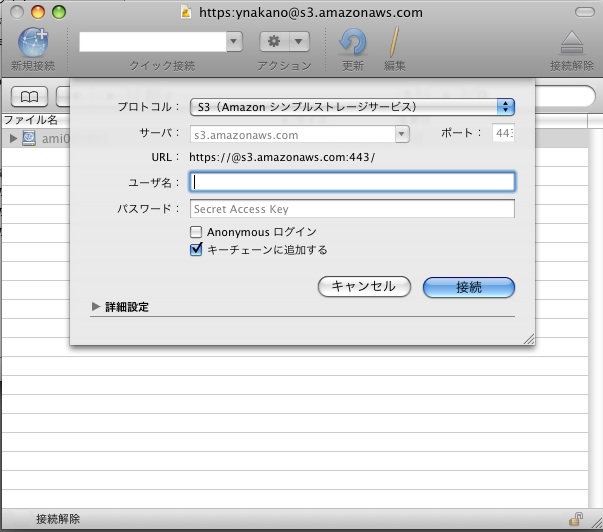
ここにIDを二つ入れればログインできる。ここのユーザ名には、Access Key IDを入れるのだ。そのあとの使い方は、見れば解るような感じだ。
Amazon EC2も使っていないと、使い方を忘れてしまいそうだ。
2008-10-12 13:22:55
パンの本はまだ来ないけれども、パンを焼いてみた。本が来なくてもできることはあるはずだ。小麦粉の袋やドライイーストの箱に、簡単なパンの作り方が書いてある。多分、パンの基本なので、これからやってみよう。これもネットで検索すればいくらでも出てくるからここで手順は説明しない。強力粉とドライイーストと砂糖と卵と水、さらにバターを加えて、捏ねて捏ねて捏ねくり回して、しばらく寝かせて、ぱんぱんぱんぱんぱんよぉ〜って鳥居みゆきじゃないんだから。
さて、一次発酵、分割・整形して二次発酵、そして焼き上げと順調に進んで(粉を混ぜたところで卵がないことに気づいて買いに行ったことは別にして)できあがったのがこれ。

まるでバターロールである。食べてみるとこれまたバターロールである。特別美味いわけでもなく特別不味いわけでもない。普通のパンができた。面白くないな。でも、最初は基本的な操作から身につけないと、一気に難しいことはできない。私はもっと固いパンが好きなのだ。
少しずついろいろなパンを焼けるようになりたい。
2008-10-11 16:41:43
使い方を忘れてしまったときのために、控えておく。
たとえば、flvをmpegに変換して保存したい場合。昨日、flv形式の動画ファイルをKeynoteに埋め込もうとしたらできなかった。mpegに変換しなければならない。そんなときは、ffmpegを使えばいいらしいと解ったので、早速使ってみた。 ubuntuでは、synapticで選んでインストールすればいい。
ffmpeg -i input.flv output.mpg
これだけで、flvファイルがmpgファイルに変換される。さらに、詳しい使い方は、こちらで。
MacOSXでいろいろ探して何種類かダウンロードして試してみたのだが、結局ffmpegをコマンドラインで使うのが一番確実でわかりやすかった。 MacPortを使って、sudo port install ffmpegとやって簡単にインストールできる。MacPort自体の説明やインストール方法についてご存じない方は、MacPortのサイトか、検索エンジンで日本語の解説など探してみていただきたい。
2008-10-11 13:49:33
 グルジア料理のСуп Харчо(これはロシア語。グルジア語表記は知らない。グルジア文字なんてどうやって入力したらいいかも解らない)を本を見ながら作っていたときに、初めてフェネグリークを使って、その香りに驚いた。調べるとカレーに不可欠とか書いてあるのだが、単独での香りは甘い。偽物のメープルシロップはこれで作ると書いてあるのを読んだことがある。それくらい甘い。それで、その独特の芳香を放つ牛肉とトマトのスープを、娘にもう飽き飽きだと云われるくらい作った。
グルジア料理のСуп Харчо(これはロシア語。グルジア語表記は知らない。グルジア文字なんてどうやって入力したらいいかも解らない)を本を見ながら作っていたときに、初めてフェネグリークを使って、その香りに驚いた。調べるとカレーに不可欠とか書いてあるのだが、単独での香りは甘い。偽物のメープルシロップはこれで作ると書いてあるのを読んだことがある。それくらい甘い。それで、その独特の芳香を放つ牛肉とトマトのスープを、娘にもう飽き飽きだと云われるくらい作った。
話は変わるが、「シクラメンのかほり」という歌をご存じだろうか。1975年に布施明が歌った曲である。『日本レコード大賞』をはじめとするその年の音楽賞を総なめにした。作詞・作曲は小椋桂である。当時は気づかなかったのだが、後に何か変じゃないかと思うようになった。「香り」は「かをり」だろう。仮名遣いが間違っているじゃないか。それにシクラメンに香りはないし(それは、どうでもいいけど)。
それに反比例して好感度が上がったのは眞鍋かをりである。ちゃんと仮名遣いが解っている人に名付けてもらえたんだろう。鳥居みゆきの「社交辞令でハイタッチ」の第一回目だけときどき鳥居みゆきが眞鍋かをりに似て見えるという現象のせいで印象がよくなったということもある。
一体何の話をしているんだ。かをりの話である。フェネグリークのかをりの話を書きたかったのである。
最初に買ったフェネグリークがなくなったので、別の会社が販売しているのを買ったのだけど、これが全然香りがない。色も緑っぽいし。蒔いたら芽が出るんじゃないかと思えるほどだ。蒔かなかったけど。ちょっと茶色になるまで煎ってみたが、あまり香りは強まらなかった。残念ながらこれは半分くらい捨ててしまって、新しいのを買った。少し香りは強くなったけれども、最初のには遠く及ばない。次に買ったのも、やはり弱い。あのフェネグリークの香りを感じることはもうないのだろうか。今年の夏はグルジア紛争のニュースが目に入るたびに、フェネグリークの香り漂うСуп Харчоの幻覚を見た。
最初に買ったのは、実はVoxspiceの商品だった。いつも仕事帰りに寄る店には、ここの香辛料がいろいろ置いてあるのだが、フェネグリークは置いていないのだ。だから、店の人に頼んで取り寄せなければならない。私は店の人と話すのが嫌いなので(その店の人が嫌いなのではない。人と話すのが嫌いなのだ)、一回しか註文したことがないのだ。とにかく、人と話すのが嫌いなのだ。怖いのだ。社会生活を営むのにかなりぎりぎりのところにいると自分でも思う。
でも、通販を見つけたからこれからはこいつで註文しようか。再びあの芳香で鼻腔を満たすことができるのか。
2008-10-11 11:18:54
 オンライン・デスクトップではかなり有名なんじゃないかと思う。名前とメールアドレスなどを登録すると、無料でアカウントが手に入る。5GBまでの容量が無料。OpenOffice.orgとAdobe readerは入っている。OpenOffice.orgは別窓が開いて動き始めるのだが、日本語の入力ができない。何なんだ。アジア言語を有効にしてみたのだが。ubuntu linuxでもMacOSXでも駄目だった。Windowsのことは解らない。Notepad という簡単なエディタのようなものがあるが、これは日本語入力が可能。ただ、Linux ATOK3では、文字入力の小窓がでてこないので変換がどうなっているのかわからない。事実上日本語入力ができないのだ。インライン入力ができればいいのに。MacOSXでは日本語入力の小窓が現れる。Hard Driveが全然使えるようにならないのだけど、なぜだ。ずっとくるくる回っている。ああ、とうとう何も動かなくなってしまった。仕方がないから、ログアウトだ。
オンライン・デスクトップではかなり有名なんじゃないかと思う。名前とメールアドレスなどを登録すると、無料でアカウントが手に入る。5GBまでの容量が無料。OpenOffice.orgとAdobe readerは入っている。OpenOffice.orgは別窓が開いて動き始めるのだが、日本語の入力ができない。何なんだ。アジア言語を有効にしてみたのだが。ubuntu linuxでもMacOSXでも駄目だった。Windowsのことは解らない。Notepad という簡単なエディタのようなものがあるが、これは日本語入力が可能。ただ、Linux ATOK3では、文字入力の小窓がでてこないので変換がどうなっているのかわからない。事実上日本語入力ができないのだ。インライン入力ができればいいのに。MacOSXでは日本語入力の小窓が現れる。Hard Driveが全然使えるようにならないのだけど、なぜだ。ずっとくるくる回っている。ああ、とうとう何も動かなくなってしまった。仕方がないから、ログアウトだ。
あとで、Desktoptwoから送ったメールをubuntuのSylpheedで開いてみたら、文字化けしていた。がっかり。日本人には使えないんじゃないか。
2008-10-11 09:12:56
![]() そんなに試してどうするんだと自分でも思うけれども、これはと思う者になかなか出会わないから、探し続けるのである。ここも、ユーザ名とメールアドレスの入力で簡単に登録できる。ログイン時にこんな幽霊がうろうろするのが微笑ましい。ログインすると、かなりデスクトップらしいデスクトップ。いろいろ並びすぎていて鬱陶しいが、あとで片付ければすっきりする。背景ももちろん変えられる。
そんなに試してどうするんだと自分でも思うけれども、これはと思う者になかなか出会わないから、探し続けるのである。ここも、ユーザ名とメールアドレスの入力で簡単に登録できる。ログイン時にこんな幽霊がうろうろするのが微笑ましい。ログインすると、かなりデスクトップらしいデスクトップ。いろいろ並びすぎていて鬱陶しいが、あとで片付ければすっきりする。背景ももちろん変えられる。

ディスク容量5GB、メール容量3GBが無料で使えるのは嬉しい。Office相当のアプリケーションはZoho WriterやZoho SpreadSheetか、Google Docsかを使えるようになっている。Google Docsの方は自分のgoogleアカウントを使って動かすので、他のブラウザでGoogle.docsにログインして、その文書を書き続けることも可能。Zohoの方は、G.ho.stのドライブに保存されるので、自分の他のZoho Writerファイルと同様には扱えない。使い慣れないせいか、何がどこに保存されるのかよくわからず、ちょっと戸惑う。
メールは、g.ho.stメールの他に、Gmail、YahooMailなども選べる。日本語のメールもちゃんと文字化けせずに受信できた。ウェブブラウザの中で動いているのに、ウェブブラウザがあるのがおもしろい。
これなら使えるかも知れないと思わせてくれたのだが、少し試しているうちに、どうもブラウザが不安定になる(LinuxでもMacでも。Windowsのことは知らない)ようだ。困るなあ。あと、ファイルのアップロードができなかった。いつまで経っても進まないのだ(LinuxでもMacでも。Windowsのことは知らない)。これじゃあ、使えない。でも、私の使い方が間違っている可能性もあるから、少し様子を見てみようとは思っている。
2008-10-10 23:16:10
 バッハの作品、一部は妻が作曲したと主張している人がいるという[eXciteニュース]。「無伴奏チェロ組曲が、ヨハン・セバスチャンによって書かれていないことに疑いはない」と云っているらしい。無伴奏チェロ組曲が? まさか。あれこそバッハじゃないのか。アンナ・マグダレーナにあれが作曲できるのか。まあ、私は音楽の専門家じゃないし、楽譜を読むことすらできないから、反論は何もできないのだが。
バッハの作品、一部は妻が作曲したと主張している人がいるという[eXciteニュース]。「無伴奏チェロ組曲が、ヨハン・セバスチャンによって書かれていないことに疑いはない」と云っているらしい。無伴奏チェロ組曲が? まさか。あれこそバッハじゃないのか。アンナ・マグダレーナにあれが作曲できるのか。まあ、私は音楽の専門家じゃないし、楽譜を読むことすらできないから、反論は何もできないのだが。
ひと頃、無伴奏チェロ組曲ばかり聴いていた。始めはミッシャ・マイスキーとヨーヨー・マ。そのうち、フルニエとかビルスマとか。その前は、カンタータばかり聴いていた。4番と106番をよく聴いた。この頃はオルガン曲ばかり聴いている。Nun komm, der Heiden Heiland! (BWV 659) や Ich ruf zu dir, Herr Jesu Christ (BWV 639)が好きだが、なんと言ってもPassacaglia & Fugue (BWV582) である。真夜中に頭がギチギチしてきて、何もかもが嫌になったときでも、これを聴けば何となく落ち着いてくるというものだ。
ここ30年くらい、バッハばかり聴いている。おそらく、この後もバッハばかり聴いて過ごすのだろう。きっと死ぬまで。
2008-10-09 23:08:41
 なぜか解らないが、パンを焼きたくなった。一週間以内にパンを焼かなかったらもう倒れるんじゃないかというくらいの感情である。理由は全くわからない。でも、何か行動を起こさないと仕事も手につかないような気がして、ドライイーストと強力粉を買ってきた。次は本である。何をするにも私は本を買わないと気が済まない。が、今は極力書棚の本を増やさないように努力しているところである。オンラインで検索して作成法を見つければいいではないかと心の中の声が囁き続けたのだが、オンライン書店の誘惑には勝てず二冊註文してしまった。『パンの歴史』とかいう本を買うのを我慢しただけ自分を褒めてやりたい。
なぜか解らないが、パンを焼きたくなった。一週間以内にパンを焼かなかったらもう倒れるんじゃないかというくらいの感情である。理由は全くわからない。でも、何か行動を起こさないと仕事も手につかないような気がして、ドライイーストと強力粉を買ってきた。次は本である。何をするにも私は本を買わないと気が済まない。が、今は極力書棚の本を増やさないように努力しているところである。オンラインで検索して作成法を見つければいいではないかと心の中の声が囁き続けたのだが、オンライン書店の誘惑には勝てず二冊註文してしまった。『パンの歴史』とかいう本を買うのを我慢しただけ自分を褒めてやりたい。
本を検索していたときも、パン屋の店頭でも、この頃目につく不愉快なものが「天然酵母」である。酵母は生き物だから、天然に決まっている。人工酵母なんていない。酵母の人工染色体は遺伝子工学の手法で作れるようになってはいるが、酵母そのものは天然の生き物以外にこの世に存在しない。それなのに、天然酵母とは一体何事だ。許せない。だから、パン屋の店先でどんなに美味そうなパンであっても、そういう怪しい言葉を掲げているパンは買わない。何か雑菌が入っていそうだし。
「天然酵母」なんて文字を見ると、「う〜、嫌らしい、イースト菌のにおい!」と鳥居みゆき風に顔を歪めてみたくなる。「あんなお堅いフランスを、捏ねて捏ねて、捏ねくり回して、しばらく寝かせて、バターを体全身にたっぷり塗って、ぱんぱんぱんぱんぱんぱんよぉ〜っ」と怒鳴ったらもう気が狂ったと思われるので我慢するが。そういえば、昨日だか一昨日もTVで「米のよしだ」を演っていたが、この台詞はちゃんと云ったのかな(今までとは違った短縮版だった。でも、珍しくTVで「山崎春のパン祭り」がでてきた)。
アメリカに二年間いたときは、毎日のようにパンを焼いていたのだった。出来合いの粉を混ぜて焼くだけだったが、自分で焼いたパンで弁当を作って仕事に行っていた。カフェテリアの料理がちょっと高かったということもある。そこでスープだけ買って、自分で持っていったサンドイッチを食べていた。子供が生まれた頃、ちょっと火傷をして作れなくなるまで、そうやっていた。手に火傷をしてからは、パン屋で買ったパンを食べていた。ベーグルが好きだった。作るのが大変らしいが、いつか作ってみたいものだ。
材料も本も買ったから、本が届いたらパンを焼こう。
2008-10-09 21:36:32
 今年はノーベル賞受賞者に日本人の名前が何人もあがっている。でも、一人はもうアメリカに帰化しているから、アメリカ人なんじゃないかな。実際、他国の新聞にはノーベル物理学賞はアメリカ人一人と日本人二人で分け合ったと報じられている。日本の新聞では日本人3人みたいな扱いだが、まあ、アメリカ合衆国に帰化したとはいえ、日本で研究者になってからアメリカに渡ったから、そう書く気持ちは解らないでもない。
今年はノーベル賞受賞者に日本人の名前が何人もあがっている。でも、一人はもうアメリカに帰化しているから、アメリカ人なんじゃないかな。実際、他国の新聞にはノーベル物理学賞はアメリカ人一人と日本人二人で分け合ったと報じられている。日本の新聞では日本人3人みたいな扱いだが、まあ、アメリカ合衆国に帰化したとはいえ、日本で研究者になってからアメリカに渡ったから、そう書く気持ちは解らないでもない。

何人かというのは国籍の問題であって、人種の問題ではない。そんなこといったら、アメリカ人はアメリカ先住民しかいなくなってしまうではないか。そんなことは、実はどうでもいいのだが、私はアメリカで生まれたのでアメリカ国籍がある。娘もアメリカで生まれたのでアメリカ国籍がある。両親が日本人なので、日本国籍もある。娘も同じである。ノーベル賞を取ったらどう数えられるのだろう。心配になってきた。日本0.5、アメリカ0.5だろうか。それとも、日本1、アメリカ1だろうか。あるいは、どちらかに一つだけ数えられるのだろうか。それは本人の意志だろうか。それとも、どっちの国が強いかの勝負になるのだろうか。私のせいで日米間の関係が悪化してしまったらどうしよう。もう夜も眠れそうにない。困り果てた私は、同じ立場の娘に相談した。われわれがノーベル賞を取ったらどうすればいいのかと。娘は「お父さん、莫迦?」と云った。
2008-10-08 22:54:08
![]() 実は Nivioを試してみようと思った。JavaPluginが必要なのだが、当然入っているはずと思っていたものが入っていない。UbuntuではSynapticでsun-java6-pluginをインストールするだけでいいはず。「about:plugins」とURLを入れるところに打ち込んでちゃんと有効になっていることを確認したり、いろいろJAVAアプレットを動かすサイトで動作確認をしたあとで、さてNivioを動かしてみようと思ったのに、「アプレットは初期化されていません」という表示が出る。どういうことなのか。他のアプレット確認サイトではちゃんとアプレットが動くのに。仕方がないから、Macで試してみたら動いた。でも、日本語が入力できなかった。それに遅い。あまりにも遅い。このサイトをInternetExplorerで表示することはできた。遅いけど。GYAOで動画を観てみようかと思ったが、動かなかった。遅すぎて。GYAOの動画はMacやLinuxでは観られないのだ。一部、Macでも表示される形式もあるけど、大半は駄目。「鳥居みゆきの社交辞令でハイタッチ」を観ようかと思ったのだけど。
実は Nivioを試してみようと思った。JavaPluginが必要なのだが、当然入っているはずと思っていたものが入っていない。UbuntuではSynapticでsun-java6-pluginをインストールするだけでいいはず。「about:plugins」とURLを入れるところに打ち込んでちゃんと有効になっていることを確認したり、いろいろJAVAアプレットを動かすサイトで動作確認をしたあとで、さてNivioを動かしてみようと思ったのに、「アプレットは初期化されていません」という表示が出る。どういうことなのか。他のアプレット確認サイトではちゃんとアプレットが動くのに。仕方がないから、Macで試してみたら動いた。でも、日本語が入力できなかった。それに遅い。あまりにも遅い。このサイトをInternetExplorerで表示することはできた。遅いけど。GYAOで動画を観てみようかと思ったが、動かなかった。遅すぎて。GYAOの動画はMacやLinuxでは観られないのだ。一部、Macでも表示される形式もあるけど、大半は駄目。「鳥居みゆきの社交辞令でハイタッチ」を観ようかと思ったのだけど。
と思っていたら、「Silverlight対応のWebサイトを表示するには」なんて記事がでているではないか。早速、インストールしてみた。が、記事の中でも「試した限りでは、残念ながらMoonlightでは動作しないサンプルが多い」と書いてあることから予期していたとおり、Gyaoは駄目だった。MacOSXで見てみると、ニュースなんかは表示されたものの、GyaoJockyはまたSilverlight形式ではないようだ。いや、だから「鳥居みゆきの社交辞令でハイタッチ」を観ようかと思ったのだけど。
2008-10-07 23:21:49
![]() Deskjumpを試してみた。この頃、いろいろ試し過ぎの感はあるが、まあいいだろう。誰かに迷惑をかけるわけでもないし。
Deskjumpを試してみた。この頃、いろいろ試し過ぎの感はあるが、まあいいだろう。誰かに迷惑をかけるわけでもないし。
トップページで名前とメールアドレスくらいを登録すると、使用できる。LinuxとPowerPC版MacOSXでは、DeskJunp Liteしか使えないらしいので、これをダウンロード。deskjump.jnlpというファイルが保存されるので、実行権を与えてから、Sun Java 6 Web Startで開くと(Macでは勝手に開く)、デスクトップ上にこんなデスクトップが出てくる。

左下のDeskJumpの印を押すと、文書を作ったり、表計算ソフトを作ったり、WebSiteを作ったりできる。ディスク容量は1GBまで無料。Terminalというのがあったので、開いてみると、
pwd - Print out the current working directory ls - List the contents of the current working directory cd - Chang Directory ps - Print out all current process information kill - Kill a process help - Prints out this help, and can be used to print out help on any specific function. i.e help execute copy - Copy a source file or folder to a destination rename - Rename a source file or folder delete - Delete a specific file or folder execute - Execute a java program, you can specify the classpath used ssh - Connect to a server via ssh sftp - Transfer files securely to any server, which is running ssh urldownload - Download a file from any URL to a file skin - Apply a Synth skin to DeskJump clear/cls - Clear the screenが実行できるという。ディレクトリの配置はまだ慣れないので直感的に把握できない。SSH/SFTPが使えるので、別のサーバとのファイルのやり取りはやりやすいかも。このTerminalでLocalというディレクトリが表示されるので、一体どこのローカルなのかと思ったら、本当に自分がいま使っているローカルだった。Fileというアプリケーションを開くと、LocalとHome(Deskjump側)との間で簡単にファイルの移動ができる。wwwブラウザから独立しているので、面白い。Glide OSよりもデスクトップっぽい。でも、使うかなあ。
明日はIntel版MacでDeskJump Fullとやらを試してみようか。どこが違うのだろう。
2008-10-07 20:48:00
蜂蜜がないときは、主に林檎を煮てヨーグルトと一緒に食べている。英語圏には、「An apple a day keeps the doctor away」などという諺があって、健康にいい食べ物の雰囲気があるところが嫌なのだが、仕方がない。
林檎はワインと砂糖で煮る。方法はネット上に溢れているので、検索すればいくらでも出てくるから、ここで詳しく紹介はしない。
以前は赤を使っていたのだけど、この頃は専ら白ワインを使っている。林檎の色そのものが濃縮された感じで、気に入ったからだ。保存の気持ちが強いときは砂糖は多めに。あと、レモン果汁を適量入れる。
私はいつもシナモンスティックの欠片を茶葉用の袋に入れて一緒に煮込んでいた。先日、シナモンスティックがなくなったのだが、ちょっと金のない時期でスティックが買えず、粉末を購入したのだった。これはどうやって使ったらいいのだろう。少量を鍋に放り込んでみた。すると、できあがったときに妙に濃縮された変なシナモン風味がついて気味が悪い。はっきりいってまずい。これは後でほんの少し振りかけた方がよかったようだ。まるで、失敗したアップルパイをゴミ箱に捨てた後に、もったいないからと回収したパイの中身のような代物である。実際に捨てたアップルパイを拾ってきたことはないので、あくまで想像だが。
そうはいっても、冷蔵庫で冷やしてヨーグルトと一緒に食べたらまずくはなかった。次回から気をつければもう少しましになるだろう。
冷蔵庫の奥で萎びた林檎を発見して悲しみに沈んでいるときには、お勧めである。そんな失敗をしたときに、これを作ると少し心が軽くなる。そういう間抜けなことをしないという人は好きなようにしてください。新鮮で美味しい林檎は、生で食べた方が美味いと思うけど。
2008-10-05 19:58:04
 Google 10周年記念とかで、期間限定でGoogle 2001というサイトが出来ているという。2001年当時の検索ができるらしい。この私のサイトは1996年から続いているので、当時も検索できたはずだ。早速、調べてみよう。「Tolle et Lege」と入力すると、トップにこのサイトが出てきた。しかし、内容はすでに存在しない洋書の紹介ページで、ピーター・S・ビーグルの本に関するページのようだ。トップページはわざとわかりにくくしていたのである。「海外書店リンク」と入れると、やはりここのページがトップに出てくる。海外書店リンク集である。
Google 10周年記念とかで、期間限定でGoogle 2001というサイトが出来ているという。2001年当時の検索ができるらしい。この私のサイトは1996年から続いているので、当時も検索できたはずだ。早速、調べてみよう。「Tolle et Lege」と入力すると、トップにこのサイトが出てきた。しかし、内容はすでに存在しない洋書の紹介ページで、ピーター・S・ビーグルの本に関するページのようだ。トップページはわざとわかりにくくしていたのである。「海外書店リンク」と入れると、やはりここのページがトップに出てくる。海外書店リンク集である。
日記を検索してみようと思ったが、すぐには出てこない。何か、長ったらしい名前を付けていたのだが、それが何だか思い出せない。しかし、それは思い違いで、当時すでに「手に取って、読め!」だったようだ。自分の名前を入力したらトップに出てきた。
2001年当時はJustNetを利用していたので、どのURLもすでに無効になっている。自宅サーバにしたのはいつの頃からだったか。懐かしいねえ。でも、いろいろ思い出していたら、いろいろ思い出したくないことも思い出しそうになってきたので、もう止めておこう。気分が暗くなるから。暗くなるだけでなくて、今晩眠れなくなったりしたら嫌だから。
2008-10-05 16:37:30
 そういえば、AdobeにもBuzzWordっていうオンライン・ワープロがあるそうじゃないかということで、早速試してみた。Acrobat.comのアカウントを作る必要があるらしい。初めてだから、新規登録をしようとしたら、そのメールアドレスはもう登録済みだと云われる。そうだったのかなあと思い、メールアドレスと最初に思いついたパスワードを入力したらログインできた。
そういえば、AdobeにもBuzzWordっていうオンライン・ワープロがあるそうじゃないかということで、早速試してみた。Acrobat.comのアカウントを作る必要があるらしい。初めてだから、新規登録をしようとしたら、そのメールアドレスはもう登録済みだと云われる。そうだったのかなあと思い、メールアドレスと最初に思いついたパスワードを入力したらログインできた。
いつの間にこんなものができていたんだと思ったら、どうやら今年の6月辺りからだとか。共有作業にも使えて、Acrobat 9とも連携しているという。
ああ、何だか綺麗な画面じゃないか。しかし、遅い。もっと速いコンピュータを買った方がいいということなんだろうか。私にはそんな金はない。Microsoft Word形式のファイルも読み込めるらしい。Adobe Air版もあるのか。オフラインでも使えるということだ。遅いということを別にすれば、実に素晴らしい。無料だし。と思ったら、日本語が入力できないじゃないか。コピー&ペーストでも駄目だ。ちぇ、そのうち日本語が使えるようになったらまた来てやると呟いて、ログアウトだ。
2008-10-05 13:43:57
 水苔の日がまたやって来たので撮影。三週間おきに撮影して、その育ち具合を確認しようというわけである。もうプランターから溢れそうだ。この頃、最低気温が20度前後、最高気温が25度前後となって、水苔にも心地よい気温になった……のかどうかはよく知らない。少なくともハエトリソウにはちょうどよくなったと思う。酷暑の頃はいかにもつらそうである。
水苔の日がまたやって来たので撮影。三週間おきに撮影して、その育ち具合を確認しようというわけである。もうプランターから溢れそうだ。この頃、最低気温が20度前後、最高気温が25度前後となって、水苔にも心地よい気温になった……のかどうかはよく知らない。少なくともハエトリソウにはちょうどよくなったと思う。酷暑の頃はいかにもつらそうである。
食虫植物といえば、これが巨大化して人を襲ったりしないかと想像を膨らませたことが誰でも、少年少女だった頃に一度はあるだろう。一度もなかったとしたら、あなたは生まれながらにして老人だったに違いない。人を襲う植物と云って真っ先に頭に思い浮かぶのが、普通「トリフィド」ではないだろうか。少なくとも私はそうだ。The Day of the Trifidsである。東京創元社版では『トリフィド時代』、早川書房版では『トリフィドの日』という邦題になっている。緑色の流星群の光を見た人間は視力を失ってしまって、油を取るために栽培していたトリフィド(名前は三本足に由来している)が凶暴化して盲目の人々を襲うようになるのだ。これは昔『人類SOS』という名前の映画になって、そこでは結末は海水をかけたらたちまちトリフィドは死んでしまって、ああ助かったという陳腐な結末になっているのだが、原作では生き残った人類が手探りで(いや、盲目にならなかった生き残りなので、文字通りの手探りではない)文明を再建していこうとするところで終わっている。傑作も、実に陳腐な映画に仕立て上げられるという例である。この本が今は新刊書で入手できないというのは信じがたい。
1981年に映像化されたTVシリーズのDVDは入手可能のようだ。面白かどうかは知らないけど。
何だかよく解らなくなって来ましたが、トリフィドを思い出しながら、元気な水苔と食虫植物を眺める秋の日曜日です。皆さんの食虫植物は元気でしょうか。

2008-10-04 19:56:48
 私は健康にいいことが大嫌いである。健康にいいことは一切したくないので、スポーツ・運動の類はまったくしない。スポーツは嫌いなので、観戦もしない。大競技場なんてパンとサーカスの香りがするではないか。スポーツ観戦は危険だと思う。話は変わるが私が子供の頃は「健康優良児」なんて不気味なものが学校で表彰されたりした。30年くらい前になくなったようだが。高井昌吏・古賀篤『健康優良児とその時代―健康というメディア・イベント』(1680円/青弓社)[amazon.co.jp,
私は健康にいいことが大嫌いである。健康にいいことは一切したくないので、スポーツ・運動の類はまったくしない。スポーツは嫌いなので、観戦もしない。大競技場なんてパンとサーカスの香りがするではないか。スポーツ観戦は危険だと思う。話は変わるが私が子供の頃は「健康優良児」なんて不気味なものが学校で表彰されたりした。30年くらい前になくなったようだが。高井昌吏・古賀篤『健康優良児とその時代―健康というメディア・イベント』(1680円/青弓社)[amazon.co.jp, bk1,
楽天,
紀伊國屋書店,
Yahoo! Books]という本が今年の6月に出ていて、気になっているのだが、財布の中身と本の収納空間が厳しい状況なのでまだ買えない。ああ、ラジオ体操も大嫌いだった。学校に関係することは嫌な思い出が多くなるので、もう思い出すのはやめよう。
健康によさそうなのであまり云いたくないのだが、私は毎日片道40分近く歩いて地下鉄の駅まで行って通勤している。しつこいようだが、健康にいいから歩いているのではない。バスが怖いからだ。バスに乗ると結構楽に通勤できるらしい。でも、私はバスが怖いのだ。本が読めないから嫌いだというのもあるが、それ以上にバスは怖い。どこか知らないところに連れて行かれてしまうのではないかという恐怖を抱いてしまうから。夜に乗ったバスの乗客が一人だったら、ほぼ間違いなくそのバスは妖怪の国か地獄へと直行すると昔から決まっている。その点、鉄道は安心である。線路から外れてどこかへ行くことはない。存在しない駅に止まる列車の話は、まあないわけではないのだが、異界へ走っていくバスに比べれば少ないはずだ。きっと。だから、私は一人でバスには乗れない。
どれくらい怖いものかというと、バスに乗り間違えて25年間迷子になってしまった人がいるくらいなのだ。本当にあったタイの話である。元のニュース記事はすべてリンク切れなので、引用記事を引用しておくが、とにかく、私も言葉の通じないところへ連れて行かれてしまって、25年くらい帰れなくなったら大変なので、バスには極力乗らないようにしているという訳だ。
だから毎日毎日歩く。歩くと靴底がすり減る。今履いている靴は底がすり減ると、ゴムの部分がなくなって固い部分が露出し、かつかつかつと跫音が響くようになる。早朝の人の少ない地下道なんか恥ずかしいくらいである。尤も、ひと頃か〜んか〜んか〜んと駅の階段で鋭い音を響かせていたカスタネット娘(カンカン女ともいう)たちほどではないが。そういえば、もうあのミュールっていう履き物はすたれたのか、消音テープが普及したのかは知らないが、街が静かになってよかった。いやいや、その静かになった地下道で妙にかつかつと音を鳴らして歩いてしまうのが私なのだ。はやく新しい靴を買わなければ。
バスに怖くて乗れないから、はやく靴を買わなければならないという話である。
2008-10-04 13:22:07
紀伊国屋書店の毎日のベストセラーリストを画像付きで自分のサイトに埋め込むことにしよう。PHPを使って私はもう嫌と云うほど埋め込んできたのだが、今日はJavaScriptの練習なので、いきなりPHPでincludeとか使ってはならない。勝手に紀伊国屋書店が管理している商品の画像を持ってきたりしてはいけないのだが、それが許される場合がある。Affiliateプログラムである。契約条件を確認したら、埋め込んでいいと書いてあるから、いいのだ。ということで、広告を一つ作って貼り付けてみようか。
アフィリエイトの申し込みの説明はここではしない。自分の広告のsidとpidが何になるかを確認する方法もここでは説明しない。アフィリエイトなんかどうでもいいのだ、私には。合法的にリンクを貼る手段に過ぎない。とにかく、二つのIDがわかったら、下のようなPHPスクリプトを書く。
$url = "http://bookweb.kinokuniya.co.jp/";
$file = file_get_contents($url);
$content=ereg_replace("\x0D\x0A|\x0A|\x0D","\n",$file);
$content=mb_convert_encoding($content,"UTF-8","Shift_JIS");
$b_start = strpos($content,"和書デイリーベスト10");
$b_end = strpos($content,"</div>",$b_start);
$block = substr($content,$b_start,$b_end-$b_start);
$items = split("<td class=\"genre-r03-td01\">",$block);
$output = "document.writeln('<table class=\"table1\" \"><tr>');\n";
$output .= "document.writeln('<col width=\"50%\"> </col>');\n";
$output .= "document.writeln('<tr><th class=\"th1\">紀伊國屋書店</th><th> </th></tr>');\n";
for ($i=1;$i<3;$i++){
$isbn10 = substr($items[$i],strpos($items[$i],"/htm/")+5,10);
$img_url = "http://bookweb.kinokuniya.co.jp/imgdata/".$isbn10.".jpg";
$a_pos = strpos($items[$i],"<a href");
$a_end = strpos($items[$i],"</a>",$a_pos);
$title = strip_tags(substr($items[$i],$a_pos,$a_end-$a_pos));
$title = str_replace("−","ー",$title);
$output .= "document.writeln('<td><img src=\"".$img_url."\" height=\"70\" align=\"left\" />');\n";
$output .= "document.writeln('<a href=\"http://ck.jp.ap.valuecommerce.com/servlet/referral?sid=xxxxxxx&pid=xxxxxxxx&vc_url=http://bookweb.kinokuniya.co.jp/htm/".$isbn10.".html\" target=\"_blank\"><small>".$title."<small></a></td>');\n";
}
$output .= "document.writeln('</table>');\n";
print $output;
これを、kino.phpとかいう名前で保存して、PHPを動かせるサーバに置く。次に目的のサイトのhtmlに以下のようにして引用する。
<script
type="text/javascript"
src="http://xxx.xxx.xxx.kino.php">
</script>
そうするとこんなものが表示されるはず。
あれ、CSSが反映されないなあ。こんな筈じゃなかったのだが。今は原因を追求する元気がないので、とりあえず、このまま出してしまう。

本当はこうなる筈だった。
このベストセラーリストは毎日更新で、Amazonみたいに毎時更新ではないから、一日一回情報を取得してテキストファイルで保存しておいてからそれを呼び出した方が効率的だと思う。よく見る広告のような感じに仕上げるのもここの目的ではないので雑な作りになっている。気が向いたら少し工夫してみるかも。
でも、これならJavaScriptを使わなくてもいいのだ。何というか、わざわざ慣れない言語で書くのは疲れるのだ。もっとJavaScriptを使っているんだっていう感じのものはないのか。あ、Google AJAX Search APIがいいか。前にはわざわざPythonを使ったんだが、JavaScriptの方が説明が詳しいではないか。
2008-10-03 22:34:23
 私は健康にいい食品が大嫌いだ。「健康にいい」と聞いただけで、不愉快になる。健康にいいものを追い求めるのって、不健康な考え方だと思う。まあ、求めたい人は求めてもいいんだけど、私は嫌いなのだ。食べたいものを食べたいだけ食べることに決めている。いや、私は食欲が必要量よりも少ないので、食べたい以上に食べなければならない。そこが面倒くさい。そもそも食事は面倒くさい。食べ過ぎて太るのを気にしている人には羨ましがられるが、それはそれでそんなに楽しいものでもない。
私は健康にいい食品が大嫌いだ。「健康にいい」と聞いただけで、不愉快になる。健康にいいものを追い求めるのって、不健康な考え方だと思う。まあ、求めたい人は求めてもいいんだけど、私は嫌いなのだ。食べたいものを食べたいだけ食べることに決めている。いや、私は食欲が必要量よりも少ないので、食べたい以上に食べなければならない。そこが面倒くさい。そもそも食事は面倒くさい。食べ過ぎて太るのを気にしている人には羨ましがられるが、それはそれでそんなに楽しいものでもない。
嫌いなものは食べないので、自分で調理するときは肉ばかりだ。野菜は肉を美味く料理するために使うだけ。だから、トマトと玉葱を大量に使う。生野菜は基本的に好きではない。レタスは食べるけど、たくさん食べると兎になったような気分になるから、あまり多くは食べたくない。
さて、私は美味い蜂蜜が好きなので、毎朝ヨーグルトと一緒に食べたりする。ヨーグルトってちょっと健康的な雰囲気があって嫌なのだが、好きだから仕方がない。と思っていたら、先日、
ハチミツに高い殺菌効果、抗生物質に代わる可能性も カナダ研究などという報道が! 私の好きなマヌカ蜂蜜が特によいと書いてある。困るじゃないか。これではまるで私が健康に気を遣ってヨーグルトとマヌカ蜂蜜を食しているみたいじゃないか。しかし、だからといって、ヨーグルトとマヌカ蜂蜜を諦める気にもならない。悔しいけれども、ちょうど蜂蜜がなくなってしばらく経ったので、マヌカはちみつ 500gをAmazon.co.jpを註文した。悔しい。誰か、蜂蜜は不健康だという研究結果を報告してくれないか。
そういえば、この頃バナナが品薄になっているらし[47NEWS]。莫迦か。これだけ騙されてまだ懲りないのか。私はバナナも前から好きなんだ。食べられなくなるじゃないか。
2008-10-02 21:29:05
Amazon.co.jpの書籍情報を取得して結果を表示する。というのはこれまで嫌と云うほどやってきたことなのだが、専らPHPだった(希にRuby、一応Pythonでもやり方だけは確認した)。サーバーサイド処理至上主義者だった私は(嘘)、JavaScriptで処理するなんて許せなかったのだ(本当は知らなかっただけだ)。PHPもRubyもPythonも動かせないところでも、私にもいろいろなものを組み込んだサイトを作れるということなんだろうか。ようやく何が便利なのか解ってきた。しかし、JavaScriptのことはまだほとんど解っていない。
Amazonからの情報はxsltで変換するらしい。.xslってファイルを作って保存するとか。前に作ったことがある。数年前にはこれをちょっとは作れるようになったのだ。ちょっとだけど。もうすっかり忘れてしまっているのが情けない。ということでAmazon Web サービス入門を参考にして、見よう見まねで作ってみた。今回はASINで商品情報を得るItemLookupというものである。
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:aws="http://webservices.amazon.com/AWSECommerceService/2008-08-19"
version="1.0">
<xsl:output method="html" encoding="utf-8"/>
<xsl:template match="/">
<xsl:apply-templates select="aws:ItemLookupResponse/aws:Items/aws:Item"/>
</xsl:template>
<xsl:template match="aws:ItemLookupResponse/aws:Items/aws:Item">
document.write('<p>『<xsl:element name="a">
<xsl:attribute name="href">
<xsl:value-of select="aws:DetailPageURL" />
</xsl:attribute>
<xsl:attribute name="target">_blank</xsl:attribute>
<xsl:value-of select="aws:ItemAttributes/aws:Title" />
</xsl:element>』<br />');
document.write('<xsl:value-of select="aws:ItemAttributes/aws:Author" /><br />');
document.write('<xsl:element name="a">
<xsl:attribute name="href">
<xsl:value-of select="aws:DetailPageURL" />
</xsl:attribute>
<xsl:attribute name="target">_blank</xsl:attribute>
<xsl:element name="img">
<xsl:attribute name="src">
<xsl:value-of select="aws:ImageSets/aws:ImageSet/aws:MediumImage/aws:URL" />
</xsl:attribute>
<xsl:attribute name="width">
<xsl:value-of select="aws:ImageSets/aws:ImageSet/aws:MediumImage/aws:Width" />
</xsl:attribute>
<xsl:attribute name="height">
<xsl:value-of select="aws:ImageSets/aws:ImageSet/aws:MediumImage/aws:Height" />
</xsl:attribute>
<xsl:attribute name="alt">
<xsl:value-of select="aws:ItemAttributes/aws:Title" />
</xsl:attribute>
<xsl:attribute name="border">0</xsl:attribute>
</xsl:element>
</xsl:element></p>');
</xsl:template>
</xsl:stylesheet>
よく解らないなあ。参考にしたサイトには、JavaScriptの呪文は入っていない。これの入れ方がまだよく解らないのだ。これだけでもずいぶん苦労したのである。こいつをamztest.xslという名前で、外からアクセスできるところに保存する。数年前にも戸惑ったことを忘れて、またlocalhostに保存して、どうして動かないんだろうと思ってしまったことは、恥ずかしくて云えない。とりあえず、.mac(今はMobileMeとかいう変な名前だ)に保存しよう。htmlの中へは下のようにして、組み込んだ。
<script type="text/javascript" src="http://xml-jp.amznxslt.com/onca/xml?Service=AWSECommerceService&SubscriptionId=0HA30CHFKA8AR774MT82&AssociateTag=tolleetlege0d-22&Operation=ItemLookup&IdType=ASIN&ItemId=433603835X&ResponseGroup=Medium&Version=2008-08-19&ContentType=text/html&Style=http://homepage.mac.com/yoshion/amztest.xsl"> </script>
そうするとこんなふうに表示される。
Amazonのitemlookupでは、ItemIdをコンマで区切って最大10件まで一度に調べられる。上のもやってみたのだが、2個以上にすると結果が表示されないのだ。JavaScriptの部分を外して、生で表示させるとうまくいくのだが、JavaScriptで組み込もうとすると失敗する。どうしたらいいんだろう。根本を理解せずに見よう見まねだけでやっていると、こういうときに対処のしようがない。情けない。
最新の日記に戻る